[논문리뷰] X2SAM: Any Segmentation in Images and Videos
링크: 논문 PDF로 바로 열기
저자: Hao Wang, Limeng Qiao, Chi Zhang, Lin Ma, Guanglu Wan, Xiangyuan Lan, Xiaodan Liang, et al.
1. Key Terms & Definitions (핵심 용어 및 정의)
- MLLM (Multimodal Large Language Model): 텍스트와 시각적 정보를 동시에 처리하여 다중 모달 데이터에 대한 이해와 추론을 수행하는 거대 언어 모델입니다.
- V-Prompts (Visual Prompts): 모델이 특정 개체를 식별하고 세분화할 수 있도록 지시하는 시각적 큐(점, 박스 등)입니다.
- Mask Memory: 비디오 프레임 간의 시간적 일관성을 유지하기 위해 이전 프레임의 시각적 특징과 마스크 정보를 저장하고 추출하는 모듈입니다.
Token : LLM이 마스크 디코더에게 특정 개체를 세분화하도록 지시하기 위해 생성하는 특수 토큰으로, 의미론적 정보와 공간적 마스크 생성 사이의 연결 고리 역할을 합니다.- V-VGD (Video Visual Grounded Segmentation): 비디오 내의 개체를 대화형 시각 프롬프트를 통해 프레임 전반에 걸쳐 추적하고 세분화하는 것을 평가하기 위해 제안된 새로운 벤치마크입니다.
2. Motivation & Problem Statement (연구 배경 및 문제 정의)
본 논문은 MLLM의 강력한 추론 능력과 foundation segmentation model의 정밀한 픽셀 단위 인식 능력을 통합하여 정적 이미지뿐만 아니라 동적 비디오까지 포괄하는 통합된 세분화 프레임워크를 구축하는 것을 목표로 합니다. 기존 연구들은 이미지 전용(예: LISA)이거나 비디오 전용으로 분절되어 있으며, 텍스트와 시각적 프롬프트를 통합적으로 처리하는 데 한계가 있습니다 [Figure 2]. 특히 기존 비디오 세분화 접근 방식은 프레임별로 독립적으로 디코딩을 수행하여 시간적 일관성을 유지하지 못하는 문제점이 있습니다. 따라서 다양한 이미지 및 비디오 세분화 작업을 단일 프레임워크 내에서 처리하고 시간적 정합성을 보장하는 새로운 해결책이 요구됩니다.
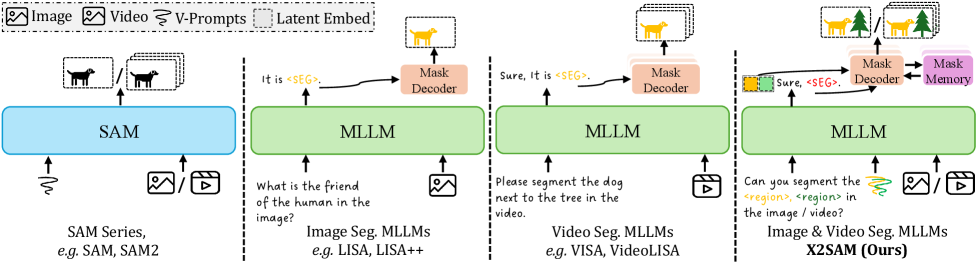
Figure 2 — 기존 모델과의 구조적 비교
3. Method & Key Results (제안 방법론 및 핵심 결과)
본 논문은 X2SAM이라는 unified segmentation MLLM을 제안하여, 임의의 이미지 및 비디오 입력에 대해 텍스트와 시각적 프롬프트를 처리하고 일관된 마스크를 생성합니다 [Figure 1]. 이 프레임워크는 Vision Encoder와 Mask Encoder를 통해 글로벌 및 로컬 특징을 추출하고, LLM을 통해 생성된 세분화 지시 토큰(SEG token)을 Mask Decoder에 주입합니다 [Figure 3]. 특히, Mask Memory 모듈은 FIFO(First-In-First-Out) 전략을 기반으로 이전 프레임의 guided vision features를 캐싱하여 동영상 전체에 걸친 시간적 일관성을 강화합니다 [Figure 4].
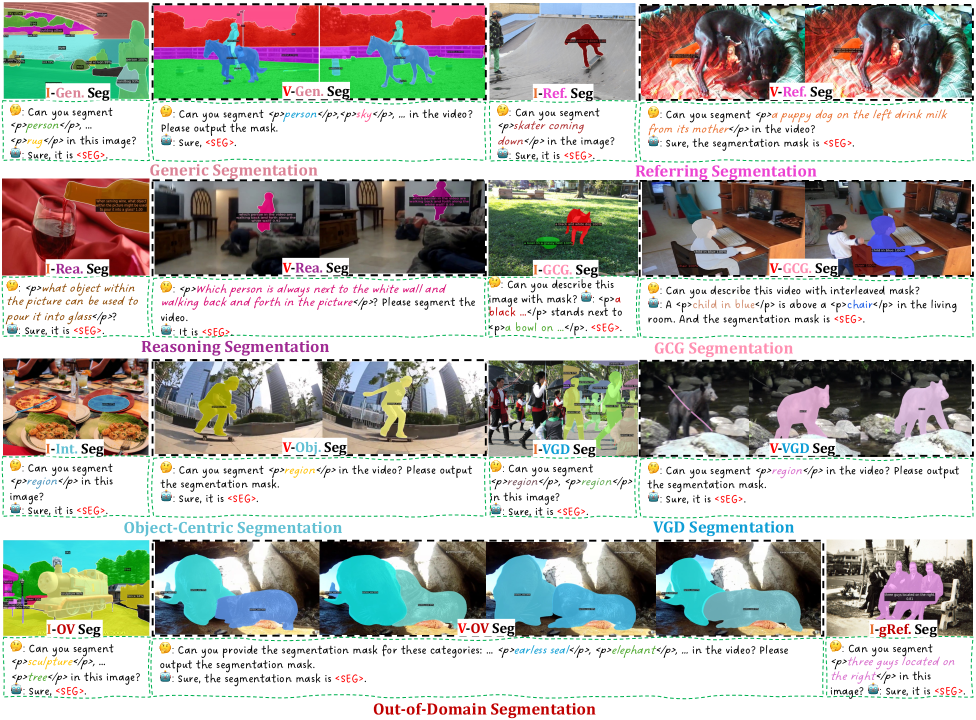
Figure 1 — X2SAM의 포괄적 기능
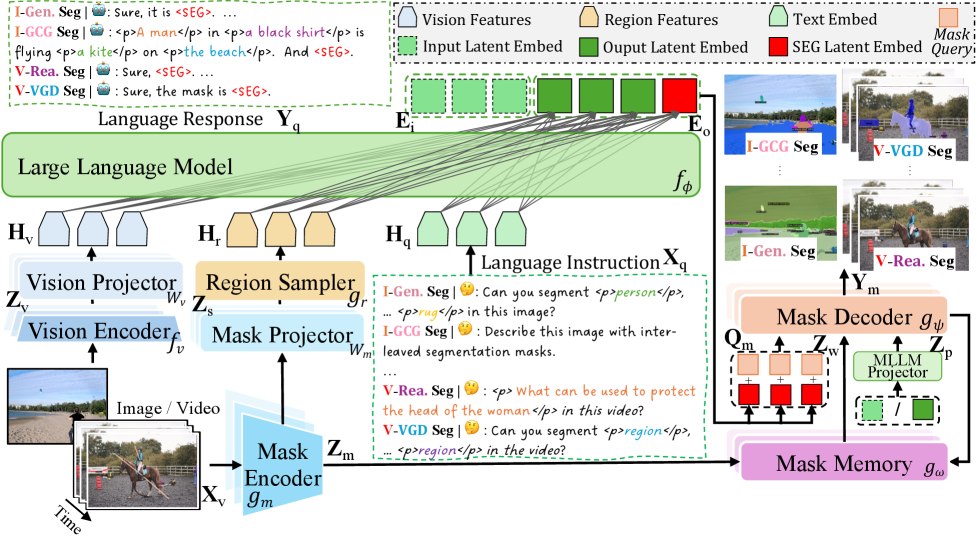
Figure 3 — X2SAM의 전체 아키텍처
실험 결과, X2SAM은 기존 방법론 대비 뛰어난 성능을 입증하였습니다.
- 영상 내 세분화 성능: V-VGD 벤치마크(YT-VIS19 및 VIPSeg)에서 box 프롬프트 평가 시, 기존 SAM2-H 대비 각각 54.0/40.4에서 74.4/57.8 AP로 대폭 향상된 성능을 기록했습니다 [Table 9].
- 통합 학습 효율: 제안된 Unified Joint Training 전략은 기존 방식 대비 GPU 사용량을 36.5% 절감하면서도 이미지와 비디오 세분화 성능을 안정적으로 유지하거나 개선했습니다 [Table 3].
- 다목적성: 영상 Reasoning 세분화(V-Rea. Seg.) 성능에서 기존 모델인 HyperSeg를 14.2 포인트 상회하며 SOTA를 달성했습니다 [Table 7].
4. Conclusion & Impact (결론 및 시사점)
본 연구는 X2SAM을 통해 이미지와 비디오를 아우르는 통합된 any-segmentation 프레임워크를 성공적으로 제안하였습니다. LLM의 추론 능력과 Mask Memory를 통한 시간적 일관성 확보를 통해 기존의 분절된 모델 구조의 한계를 극복했습니다. 이 연구는 비디오 기반의 복합 지능형 애플리케이션 및 세분화 모델 분야에서 중요한 학술적 기초를 제공하며, 효율적인 다중 모달 학습 전략의 실용적인 가이드라인을 제시합니다. 향후 연구는 더욱 정교한 효율성 확보와 고성능 경량 백본을 통한 확장성 강화에 중점을 둘 것으로 예상됩니다.
⚠️ 알림: 이 리뷰는 AI로 작성되었습니다.
관련 포스트
- [논문리뷰] One Forward Beats Two: InnerZoom for Accurate and Efficient GUI Grounding
- [논문리뷰] ShutterMuse: Capture-Time Photography Guidance with MLLMs
- [논문리뷰] P3D-Bench: Benchmarking MLLMs for Parametric 3D Generation and Structural Reasoning
- [논문리뷰] Towards One-to-Many Temporal Grounding
- [논문리뷰] MementoGUI: Learning Agentic Multimodal Memory Control for Long-Horizon GUI Agents
Review 의 다른글
- 이전글 [논문리뷰] Workspace-Bench 1.0: Benchmarking AI Agents on Workspace Tasks with Large-Scale File Dependencies
- 현재글 : [논문리뷰] X2SAM: Any Segmentation in Images and Videos
- 다음글 [논문리뷰] AI Co-Mathematician: Accelerating Mathematicians with Agentic AI
댓글