[논문리뷰] Code-as-Room: Generating 3D Rooms from Top-Down View Images via Agentic Code Synthesis
링크: 논문 PDF로 바로 열기
저자: Yixuan Yang, Zhen Luo, Wanshui Gan, Jinkun Hao, Junru Lu, Jinghao Yan, Zhaoyang Lyu, Xudong Xu
1. Key Terms & Definitions (핵심 용어 및 정의)
- Code-as-Room (CaR): top-down view 이미지를 입력받아 3D 공간의 구조, 가구 배치, 재질, 조명 등을 포괄하는 Blender 코드를 생성하는 MLLM 기반의 agentic 프레임워크입니다.
- Structured Execution Harness: 전체 생성 과정을 다단계 파이프라인으로 구조화하여, MLLM이 복잡한 3D 장면을 안정적으로 코딩할 수 있도록 유도하는 제어 체계입니다.
- Cross-stage Memory: 각 단계(stage)의 출력 결과를 저장하여 모델의 context forgetting 문제를 완화하고 파이프라인 전반의 일관성을 유지하는 공유 메모리 모듈입니다.
- Render-and-Compare Feedback Loop: 생성된 코드를 Blender에서 즉시 렌더링하고, MLLM이 시각적 결과를 평가하여 배치, 크기, 정렬 등을 교정하는 반복적 최적화 과정입니다.
2. Motivation & Problem Statement (연구 배경 및 문제 정의)
본 논문은 기존의 text-driven 3D 생성 방식이 갖는 공간적 정보의 불명확성과, 기존 agentic 프레임워크가 holistic room generation 과정에서 직면하는 무한 루프 및 불안정성 문제를 해결하고자 합니다. 텍스트 기반 방식은 정확한 객체 수나 위치 지정이 어렵고, 기존 image-conditioned agent는 복잡한 3D 장면 구성 시 context forgetting이나 정밀한 spatial reasoning 부족으로 실패하는 경우가 많습니다. 저자들은 top-down view 이미지가 풍부한 spatial prior를 제공한다는 점에 착안하여, 이를 코드로 변환하는 구조화된 접근 방식이 필수적이라고 판단하였습니다 [Figure 1].

Figure 1 — CaR 모델의 개요
3. Method & Key Results (제안 방법론 및 핵심 결과)
본 논문은 top-down view 이미지를 단계별로 3D 공간 코드로 변환하는 multi-stage agentic 프레임워크를 제안합니다. 이 과정은 크게 scene structuring, layout generation, object profiling, object-level coding, interior decoration 순으로 진행됩니다 [Figure 2]. 각 단계는 Cross-stage Memory를 통해 정보를 공유하며, major layout은 Render-and-Compare Feedback Loop를 통해 5회 이내의 반복적인 수정으로 높은 정밀도를 확보합니다. 실험 결과, CaR은 기존 VIGA 대비 공간 정렬 및 usability 측면에서 유의미한 성능 향상을 보였습니다. 특히 Gemini 3.1-Pro와 결합했을 때 Layout IoU 및 Spatial Relation 성능 지표에서 가장 우수한 결과를 기록하며, 수치적으로나 정성적으로 일관된 3D 룸 생성 능력을 입증하였습니다 [Table 1, Figure 6]. 또한, 생성된 장면은 고품질의 structural prior로 활용되어 재렌더링 시 더욱 현실적인 텍스처와 조명 효과를 구현할 수 있습니다 [Figure 7].
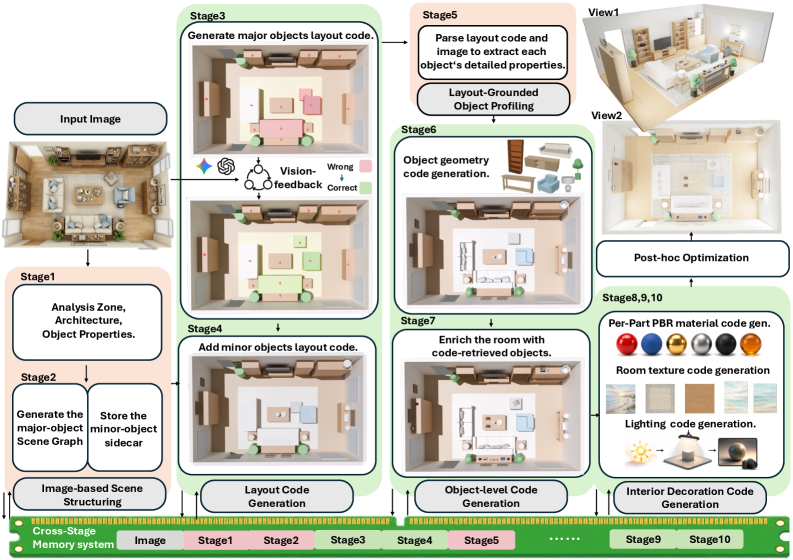
Figure 2 — CaR 파이프라인 구조
4. Conclusion & Impact (결론 및 시사점)
본 연구는 top-down view 이미지를 활용하여 편집 및 렌더링이 가능한 3D 룸을 생성하는 agentic 프레임워크 Code-as-Room을 성공적으로 제시하였습니다. 이 시스템은 structured execution harness와 memory 모듈을 통해 코드 생성의 안정성을 극대화하며, 다양한 MLLM 백본에서 일관된 고품질 결과를 도출합니다. 본 논문에서 구축한 benchmark는 향후 3D 장면 생성 연구의 표준 평가 모델로 활용될 수 있습니다. 본 기술은 향후 인테리어 디자인, 가상현실, Embodied AI 환경 구축 등 3D 콘텐츠 생성 분야에 큰 실무적 기여를 할 것으로 기대됩니다.

Figure 6 — CaR과 VIGA 모델 비교
⚠️ 알림: 이 리뷰는 AI로 작성되었습니다.
관련 포스트
- [논문리뷰] One Forward Beats Two: InnerZoom for Accurate and Efficient GUI Grounding
- [논문리뷰] The Hitchhiker's Guide to Agentic AI: From Foundations to Systems
- [논문리뷰] ShutterMuse: Capture-Time Photography Guidance with MLLMs
- [논문리뷰] AGORA: An Archive-Grounded Benchmark for Agentic Workplace Document Reasoning
- [논문리뷰] P3D-Bench: Benchmarking MLLMs for Parametric 3D Generation and Structural Reasoning
Review 의 다른글
- 이전글 [논문리뷰] Code as Agent Harness
- 현재글 : [논문리뷰] Code-as-Room: Generating 3D Rooms from Top-Down View Images via Agentic Code Synthesis
- 다음글 [논문리뷰] CompactAttention: Accelerating Chunked Prefill with Block-Union KV Selection
댓글