[논문리뷰] OmniRetrieval: Unified Retrieval across Heterogeneous Knowledge Sources
링크: 논문 PDF로 바로 열기
메타데이터
저자: Jinheon Baek, Soyeong Jeong, Sangwoo Park, Woongyeong Yeo, Minki Kang, Patara Trirat, Heejun Lee, Sung Ju Hwang
1. Key Terms & Definitions (핵심 용어 및 정의)
- OmniRetrieval: 구조적으로 이질적인(Heterogeneous) 지식 소스를 각각의 고유한 query language(SQL, SPARQL, Cypher 등)를 통해 통합적으로 접근하는 프레임워크입니다.
- Native Query Language: 각 지식 소스가 데이터를 조회하기 위해 사용하는 고유의 언어입니다. 본 논문은 이 언어들을 직접 생성함으로써 각 소스의 구조적 특성을 온전히 보존합니다.
- Cross-Source Evidence Selection: 다수의 소스에서 검색된 결과를 자연어 기반으로 통합하고, 질문에 가장 적합한 최종 근거(Evidence)를 추출하는 단계입니다.
- Structural Context ($c_b$): 각 지식 소스가 외부 호출자에게 노출하는 메타데이터(예: relational schema, ontology, corpus descriptor)로, 쿼리 생성의 기초가 됩니다.
2. Motivation & Problem Statement (연구 배경 및 문제 정의)
본 연구는 현실 세계의 다양한 정보 요구가 비정형 텍스트, 관계형 데이터베이스, 지식 그래프 등 구조적으로 이질적인 소스들에 분산되어 있음에도 불구하고, 기존 검색 시스템들이 단일 소스 혹은 단일 query language에만 최적화되어 있어 통합적인 검색이 어렵다는 점을 해결하고자 합니다 [Figure 1]. 기존 연구들(Baseline)은 모든 소스를 하나의 고정된 embedding space로 투영(Homogenization)하여 정보를 검색하는데, 이는 각 지식 소스가 가진 고유한 구조적 특성(join, ontology, compositional operator 등)을 상실시키는 Lossy Projection 문제를 야기합니다. 따라서, homogenization 대신 각 지식 소스의 구조를 존중하면서도 이들을 통합적으로 접근할 수 있는 Access Layer가 필요합니다 [Figure 1].
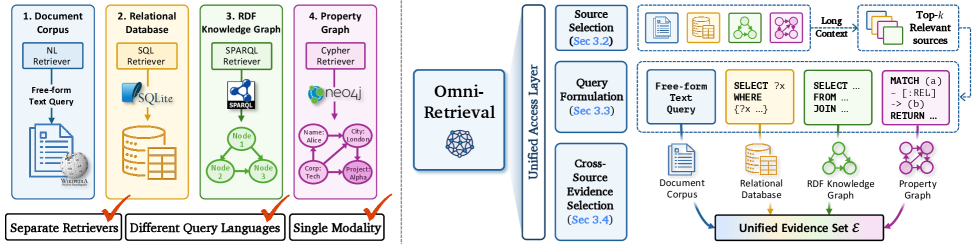
Figure 1 — OmniRetrieval 전체 아키텍처
3. Method & Key Results (제안 방법론 및 핵심 결과)
OmniRetrieval은 질문이 입력되면 적절한 지식 소스를 선택하고, 해당 소스의 native query language로 실행 가능한 쿼리를 생성한 뒤, 실행 결과를 Consolidation하는 통합 프레임워크입니다 [Figure 1]. 먼저 긴 문맥을 이해하는 LLM을 통해 지식 소스의 구조적 context를 참조하여 쿼리에 적합한 소스 후보군을 선정하고, 각 소스에 최적화된 Native Query를 생성합니다. 최종적으로 실행된 결과들 중에서 질문에 가장 관련성 높은 evidence를 선택하는 Cross-Source Evidence Selection 단계를 거칩니다 [Figure 1]. 13개의 데이터셋과 309개의 지식 베이스를 포함하는 벤치마크 실험 결과, OmniRetrieval은 단일 소스 기반의 모든 Baseline 모델 대비 우수한 성능을 보였습니다 [Table 1]. 특히, 소스 선택(Source Selection)부터 최종 증거 선택까지 단계별로 정확도를 높이며, 소스 후보군($k$)이 증가할수록 성능이 향상되는 경향을 확인하였습니다 [Figure 2]. 또한, 단순 통합 임베딩 방식(Unified-Representation) 대비 구조적 연산(join, traversal 등) 보존 측면에서 압도적인 비교 우위를 점함을 입증하였습니다 [Table 3].
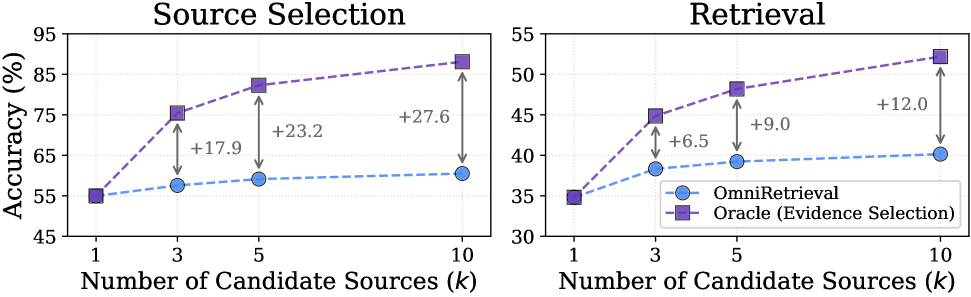
Figure 2 — 후보군 수(k)에 따른 성능 변화
Table 3 — Unified 방법론 비교 분석
4. Conclusion & Impact (결론 및 시사점)
본 논문은 구조적으로 이질적인 지식 소스들을 homogenization 없이 Native Query를 통해 통합적으로 검색하는 OmniRetrieval 프레임워크를 제안하였습니다. 이 접근 방식은 각 소스가 가진 구조적 affordance를 보존하면서도 사용자에게는 통일된 자연어 인터페이스를 제공함으로써 정보 검색의 한계를 확장하였습니다. 본 연구는 향후 복잡한 지식 기반의 agent 시스템 설계에 있어 지식 검색의 표준적인 아키텍처로 기능할 것으로 기대됩니다.
⚠️ 알림: 이 리뷰는 AI로 작성되었습니다.
관련 포스트
Review 의 다른글
- 이전글 [논문리뷰] OmniInteract: Benchmarking Real-World Streaming Interaction for Real-Time Omnimodal Assistants
- 현재글 : [논문리뷰] OmniRetrieval: Unified Retrieval across Heterogeneous Knowledge Sources
- 다음글 [논문리뷰] PRISM: A Multi-Dimensional Benchmark for Evaluating LLM Peer Reviewers
댓글