[논문리뷰] PRISM: A Multi-Dimensional Benchmark for Evaluating LLM Peer Reviewers
링크: 논문 PDF로 바로 열기
메타데이터
저자: Ngoc Phan Phuoc Loc, Toan Huynh La Viet, et al.
1. Key Terms & Definitions (핵심 용어 및 정의)
- PRISM (Peer Review Intelligence via Structured Multi-dimensional assessment): 논문 리뷰의 품질을 4가지 독립적 차원에서 정량적으로 평가하기 위해 저자들이 제안한 벤치마킹 프레임워크입니다.
- DoA (Depth of Analysis): 리뷰어가 단순히 표면적인 의견을 제시하는지, 아니면 객관적이고 잘 근거된 전제(Premise)를 사용하여 논문의 주장과 증거를 심도 있게 평가하는지를 측정하는 지표입니다.
- nCPS (normalized Critique Prioritization Score): 리뷰 내에서 Critical한 결함이 Minor한 문제보다 앞서 기술되었는지를 평가하여 리뷰의 구조적 논리성을 측정하는 지표입니다.
- MCS (Multi-dimensional Constructiveness Score): 리뷰가 저자에게 얼마나 실행 가능하고(Actionable), 구체적이며(Specific), 논리적인지, 그리고 전문적인 어조를 유지하는지를 평가하는 지표입니다.
- ARC (Atomic Review Comment): 리뷰 텍스트를 가장 작은 독립적인 비평 단위로 분해한 것으로, PRISM의 constructiveness 평가의 기본 분석 단위입니다.
2. Motivation & Problem Statement (연구 배경 및 문제 정의)
본 논문은 급증하는 머신러닝 논문 투고량으로 인해 피어 리뷰 시스템이 한계에 직면했으며, 이를 보완하기 위한 LLM 기반 자동화 리뷰어의 실질적인 역량을 검증해야 한다는 문제의식에서 출발합니다. 기존 연구들은 ROUGE나 BLEU 같은 표면적 지표나 신뢰할 수 없는 LLM-as-a-judge 방식에 의존하여 리뷰의 과학적 논리성과 사실 관계를 정확히 평가하지 못하는 한계가 있습니다. 따라서 저자들은 연구의 방법론적 엄밀함, 참신성, 결함 식별, 건설적인 피드백을 체계적으로 검증할 수 있는 새로운 벤치마킹 프레임워크가 필요하다고 주장합니다. 이를 통해 LLM 리뷰어가 단순히 유창한 텍스트를 생성하는 수준을 넘어 실제 과학적 격차(scientific gaps)를 식별할 수 있는지 규명하고자 합니다 [Figure 1].
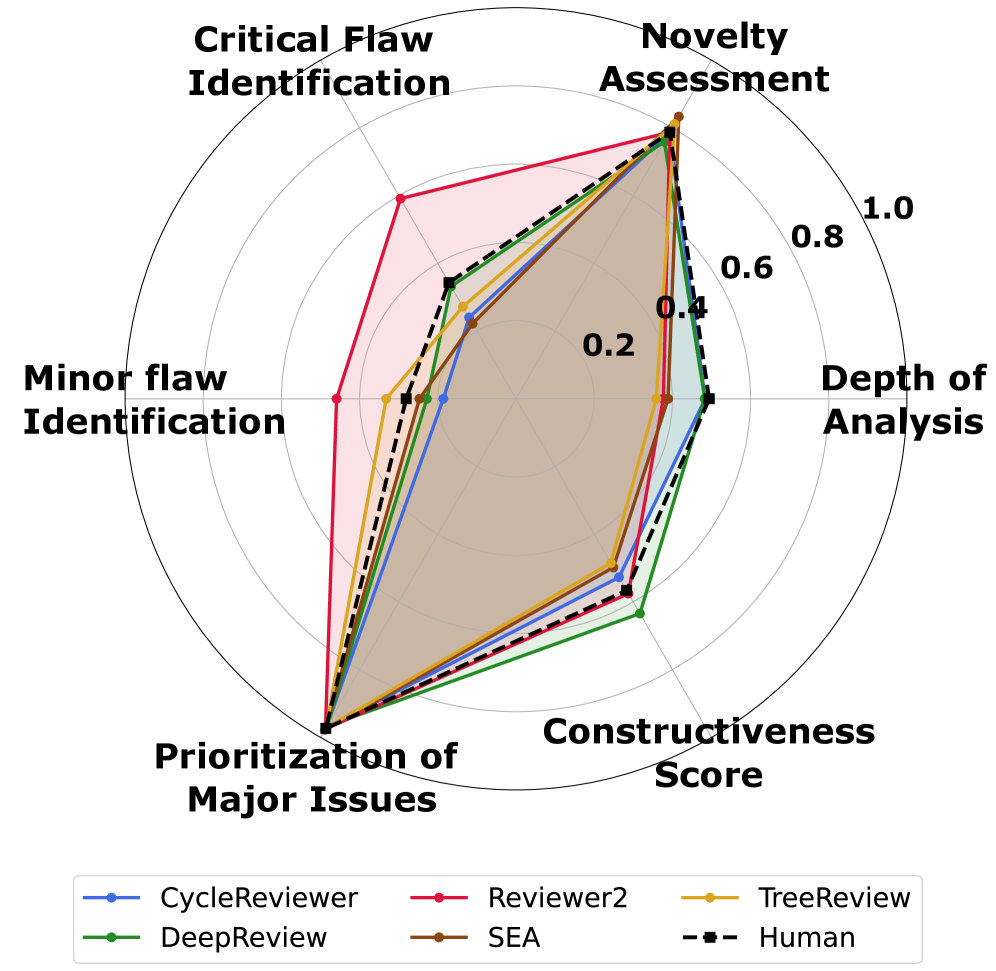
Figure 1 — LLM 및 인간 리뷰어 결과 비교
3. Method & Key Results (제안 방법론 및 핵심 결과)
PRISM 프레임워크는 리뷰의 각 차원별로 특화된 4개의 평가 파이프라인(Argument Mining, Retrieval-Augmented Verification, Consensus-based Scoring 등)을 설계하여 리뷰 프로세스를 구조적으로 분해합니다 [Figure 2]. 실험 결과, LLM 리뷰어는 인간의 분석 깊이(DoA)를 따라잡거나 능가할 수 있으며, 특히 참신성 검증과 비판적 결함 우선순위 선정에서 뛰어난 성능을 보였습니다. 5개 주요 자동화 리뷰 시스템을 1,000개의 실제 논문 리뷰 데이터를 바탕으로 평가한 결과, Reviewer2는 Critical한 결함을 식별하는 능력(Recall)에서 인간을 압도하는 고성능 스캐너로 작용하며, DeepReview는 피드백의 건설성(Constructiveness) 측면에서 인간보다 더 구체적이고 전문적인 솔루션을 제시하는 것으로 나타났습니다 [Table 2]. 다만, 인간과 달리 단일 모델이 모든 차원에서 탁월한 성능을 발휘하지는 못하며, 각 모델이 명확한 전문성 프로파일과 구조적 맹점을 지니고 있음을 확인했습니다.
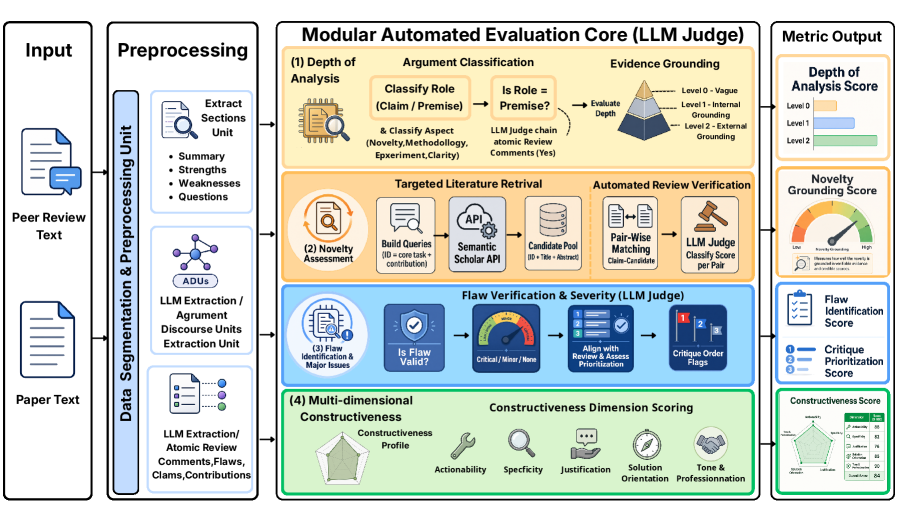
Figure 2 — PRISM 프레임워크 파이프라인
4. Conclusion & Impact (결론 및 시사점)
본 연구는 LLM 리뷰어가 인간을 대체하는 범용적 도구가 아닌, 특정 차원에 특화된 전문적인 Co-pilot으로 이해되어야 한다는 결론을 제시합니다. 연구 결과에 따라 리뷰 프로세스에서 고도의 결함 탐색은 Reviewer2, 건설적인 수정 제안은 DeepReview, 참신성 검증은 SEA를 활용하는 타겟형 앙상블 배치를 추천합니다. 본 프레임워크는 단순히 리뷰 자동화의 효율성을 높이는 것을 넘어, 학술적 엄밀성을 유지하면서 증가하는 리뷰어 부하 문제를 해결하기 위한 실질적인 배포 가이드라인을 제공합니다. 향후 PRISM은 타 학문 도메인으로의 확장과 LLM 심판 모델의 견고성 강화 연구에 중요한 기여를 할 것으로 기대됩니다.
⚠️ 알림: 이 리뷰는 AI로 작성되었습니다.
관련 포스트
- [논문리뷰] LLMs4All: A Review on Large Language Models for Research and Applications in Academic Disciplines
- [논문리뷰] xHC: Expanded Hyper-Connections
- [논문리뷰] Xiaomi-Robotics-1: Scaling Vision-Language-Action Models with over 100K Hours of Real-World Trajectories
- [논문리뷰] When Does Muon Help Agentic Reinforcement Learning?
- [논문리뷰] VideoRAE: Taming Video Foundation Models for Generative Modeling via Representation Autoencoders
Review 의 다른글
- 이전글 [논문리뷰] OmniRetrieval: Unified Retrieval across Heterogeneous Knowledge Sources
- 현재글 : [논문리뷰] PRISM: A Multi-Dimensional Benchmark for Evaluating LLM Peer Reviewers
- 다음글 [논문리뷰] Parallax: Parameterized Local Linear Attention for Language Modeling
댓글