[논문리뷰] Parallax: Parameterized Local Linear Attention for Language Modeling
링크: 논문 PDF로 바로 열기
저자: Yifei Zuo, Dhruv Pai, Zhichen Zeng, Alec Dewulf, Shuming Hu, Zhaoran Wang
## 1. Key Terms & Definitions (핵심 용어 및 정의)
- LLA (Local Linear Attention): Local linear estimator를 사용하여 기존 Softmax Attention의 국소 상수(local constant) 추정을 개선한 기법으로, associative memory 용량을 최적화함.
- Parallax: 기존 LLA의 계산 및 수치적 불안정성 문제를 해결하기 위해 고안된 parameterized Local Linear Attention으로, 추가적인 query-like projector를 통해 KV covariance를 탐색함.
- Muon: Hidden layer의 가중치 행렬을 최적화하기 위한 기법으로, SVD 기반의 polar factor를 통해 Steepest descent under operator norm을 구현하여 spectral collapse를 방지함.
- Arithmetic Intensity: FLOPs와 HBM(High Bandwidth Memory) 트래픽 간의 비율을 의미하며, Parallax는 이를 두 배로 높여 연산 집약적인(compute-bound) 환경에서 성능을 극대화함.
## 2. Motivation & Problem Statement (연구 배경 및 문제 정의) 본 논문은 대규모 언어 모델(LLM) 학습에서 Softmax Attention이 가지는 구조적 한계를 극복하고 효율성을 높이는 것을 목표로 한다. 기존 LLA는 theoretical 측면에서 탁월한 bias-variance trade-off를 제공하지만, per-token conjugate gradient solve에 의한 I/O 부하와 수치적 불안정성으로 인해 대규모 LLM pretraining에 적용하기 어려웠다 [Figure 1]. 또한, 기존 연구들은 효율적인 attention variants를 탐구해 왔으나, 여전히 Softmax Attention 대비 in-context recall 능력에서 격차를 보여왔다. 이에 저자들은 LLA의 원리를 보존하면서도 확장 가능한 Parameterized LLA인 Parallax를 제안하며, 특히 특정 optimizer와의 강력한 architecture-optimizer interaction을 확인하고자 한다.
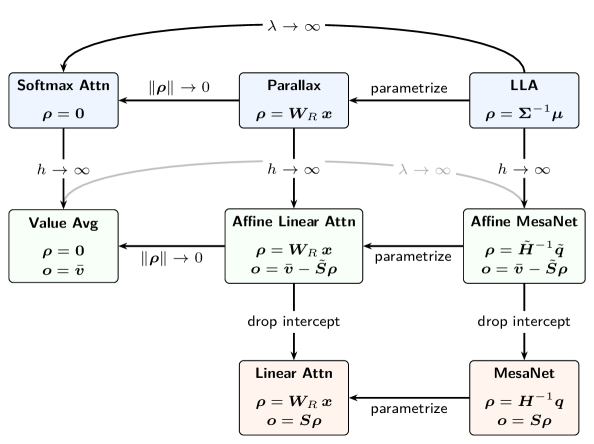
Figure 1 — Parallax와 타 Attention 기법 관계
## 3. Method & Key Results (제안 방법론 및 핵심 결과) 저자들이 제안하는 Parallax는 별도의 수치적 solver를 제거하고, 추가적인 학습 가능한 projection matrix인 $W_R$을 도입하여 입력값으로부터 직접 probe($\rho$)를 계산함으로써 효율성을 확보했다 [Figure 1]. 이 메커니즘은 Softmax Attention의 연산 구조를 확장하여, KV covariance의 정보를 보정값으로 추가하는 방식을 취한다. 또한, 저자들은 이 메커니즘을 CUDA 기반의 CuTeDSL로 구현하여, 기존 FlashAttention 2/3보다 높은 연산 강도를 달성하는 하드웨어 가속 커널을 개발했다 [Figure 2]. 정량적 실험 결과, Parallax는 0.6B 및 1.7B 규모의 pretraining에서 Transformer baseline 대비 일관된 perplexity 향상을 기록했다. 특히 Muon optimizer를 사용할 경우, AdamW 대비 성능 격차가 두드러지게 나타나며 강력한 architecture-optimizer codesign 효과를 입증하였다 [Table 3]. 또한 parameter-matched 및 compute-matched 제어 실험을 통해 이러한 성능 향상이 단순한 모델 크기 증가가 아닌 메커니즘 자체의 우수성에서 기인함을 증명했다.
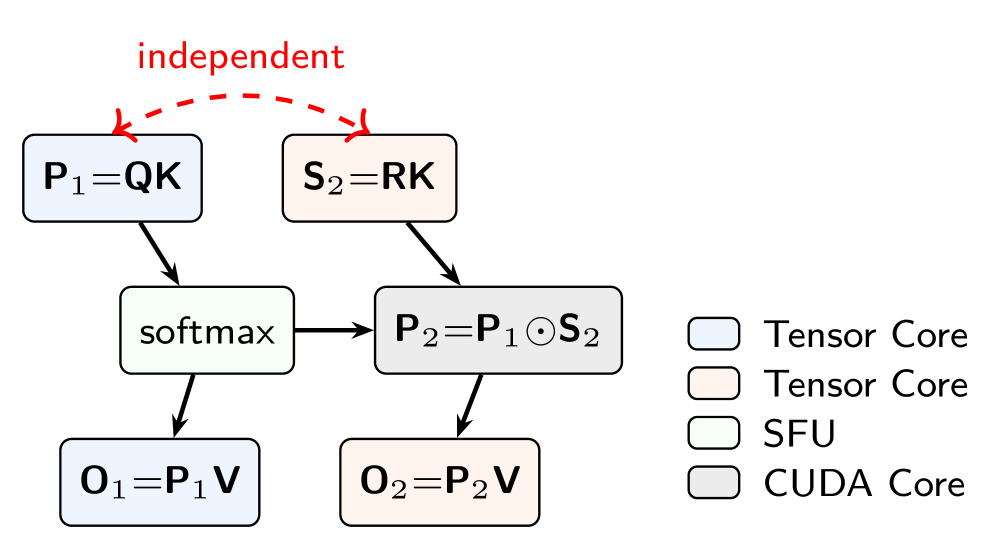
Figure 2 — Parallax 연산 의존성 및 하드웨어 매핑
## 4. Conclusion & Impact (결론 및 시사점) 본 연구는 고전적인 비모수적 통계 기법인 Local Linear Attention을 modern LLM 아키텍처에 성공적으로 확장한 사례로, Parallax라는 혁신적인 parameterized 메커니즘을 제안하였다. 특히 단순한 아키텍처 변경을 넘어 Muon optimizer와 같은 최신 최적화 도구와의 상호작용이 모델 성능에 결정적인 영향을 미침을 실증적으로 밝혀냈다. 본 연구는 향후 효율적인 long-context 언어 모델 설계에 있어 architecture-optimizer codesign의 중요성을 강조하며, 대규모 학습 파이프라인에서 성능 향상을 위한 새로운 지평을 열었다.
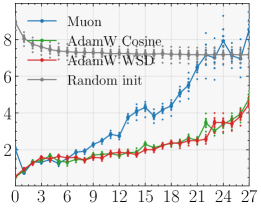
Figure 5 — optimizer에 따른 메커니즘 분석
⚠️ 알림: 이 리뷰는 AI로 작성되었습니다.
관련 포스트
Review 의 다른글
- 이전글 [논문리뷰] PRISM: A Multi-Dimensional Benchmark for Evaluating LLM Peer Reviewers
- 현재글 : [논문리뷰] Parallax: Parameterized Local Linear Attention for Language Modeling
- 다음글 [논문리뷰] PhoneWorld: Scaling Phone-Use Agent Environments
댓글