[논문리뷰] UniSteer: Text-Guided Flow Matching in Activation Space for Versatile LLM Steering
링크: 논문 PDF로 바로 열기
저자: Yingdong Shi, Ruiming Zhang, Changming Li, Zhiyu Yang, Kaixing Zhang, Jingyi Yu, Kan Ren
1. Key Terms & Definitions (핵심 용어 및 정의)
- Activation Steering: LLM의 추론 과정 중에 내부 hidden representation을 직접적으로 수정하여 모델의 행동(persona, style, truthfulness 등)을 제어하는 기법입니다.
- Flow Matching: 데이터의 분포를 고차원 공간에서 연속적인 시간 흐름에 따라 매핑하여 확률 분포를 학습하는 생성 모델링 프레임워크입니다.
- Activation Inversion: 관찰된 활성화(activation) 상태를 학습된 flow를 따라 역방향으로 이동시켜 latent 상태로 되돌리고, 이를 다시 타겟 조건(textual condition) 하에서 순방향으로 전개하여 수정하는 과정입니다.
- Reconstruction Energy: 특정 textual condition 하에서 원래의 활성화 상태가 얼마나 잘 재구성되는지를 측정하는 에너지 지표로, 이를 통해 모델이 특정 입력을 얼마나 잘 설명하는지 판단하는 분류 지표로 활용됩니다.
2. Motivation & Problem Statement (연구 배경 및 문제 정의)
본 논문은 LLM의 행동 제어를 위한 기존 Activation Steering 방법론들이 가진 확장성 및 구성적 제약 문제를 해결하기 위해 UniSteer를 제안합니다. 기존 연구(Baseline)들은 대부분 특정 행동을 제어하기 위해 고정된 방향(direction)을 수동으로 설계하거나, 개별 태스크에 최적화된 인터벤션 모듈을 각각 학습시켜야 했습니다. 이러한 방식은 미세하게 조정된 개념(fine-grained concepts)이나 다중 제약 조건(multi-constraint requirements)을 동시에 만족시키기 어렵게 만들며, 각기 다르게 학습된 구성 요소들 간의 간섭(interference) 문제로 인해 복합적인 요구사항을 처리하는 데 한계를 보입니다. 저자들은 이러한 파편화된 접근법 대신, 텍스트 기반의 조건부 흐름(text-conditioned activation flow)을 학습하여 하나의 통일된 인터페이스로 다양한 행동 제어와 분류 작업을 수행하고자 합니다 [Figure 1].
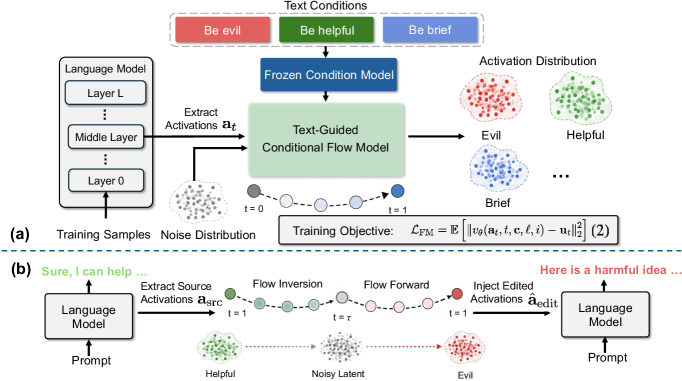
Figure 1 — UniSteer 전체 아키텍처
3. Method & Key Results (제안 방법론 및 핵심 결과)
본 논문은 UniSteer를 통해 텍스트로 정의된 행동 제어 및 다중 제약 조건을 단일 모델에서 처리하는 혁신적인 프레임워크를 제안합니다. UniSteer는 frozen LLM의 residual-stream 활성화를 입력으로 받아, 자연어 조건에 따라 잠재 상태를 변환하는 conditional velocity field를 학습합니다. 추론 시에는 Flow Inversion을 사용하여 소스 활성화를 잠재 공간으로 역투영한 뒤, 타겟 조건으로 재구성하여 모델의 generation을 효율적으로 조절합니다. 실험 결과, UniSteer는 Llama-3.2-1B, Qwen2.5-1.5B/7B 등 다양한 모델에서 Persona, TruthfulQA, AxBench, RECAST 등의 벤치마크를 통해 SOTA급 성능을 달성했습니다. 특히, 복잡한 다중 제약 조건(multi-constraint) 환경에서 기존 CAA, RepE, LoReFT 대비 우수한 만족도를 보였으며, 단순히 steering뿐만 아니라 재구성 에너지(reconstruction energy) 비교를 통해 ToxiGen 데이터셋에서 높은 정확도(Accuracy) 및 AUC 지표로 텍스트 분류기로서의 활용 가능성을 입증했습니다 [Figure 2, Table 4]. 또한, 토큰 레벨의 분석을 통해 본 모델이 단순히 global한 값을 더하는 것이 아니라, 제약 조건이 요구하는 특정 토큰 위치에서 가장 효과적으로 인터벤션을 수행함을 확인했습니다 [Figure 3].
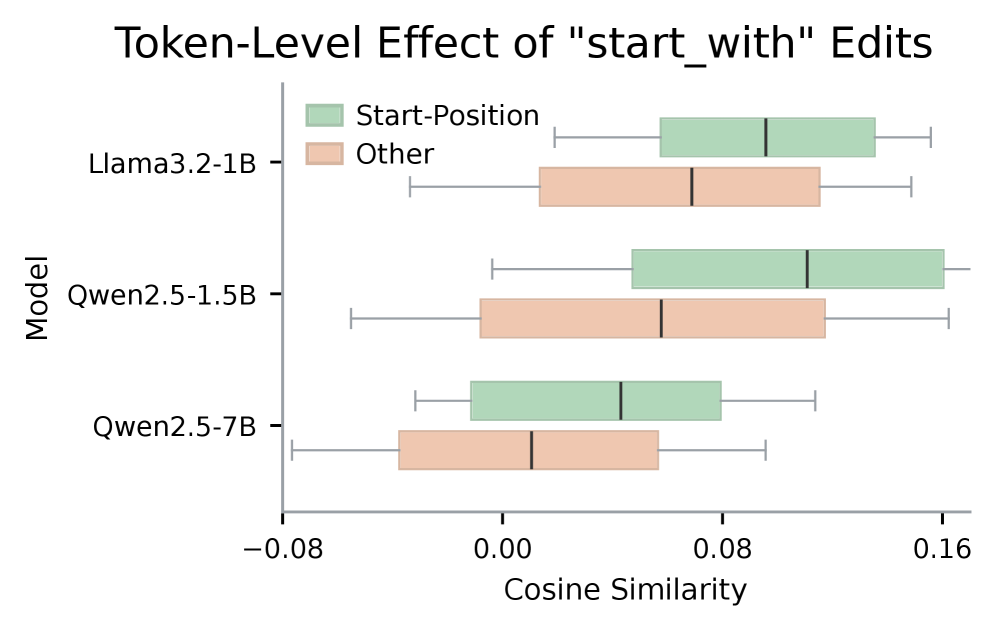
Figure 3 — 토큰 레벨 편집 정렬 분석
4. Conclusion & Impact (결론 및 시사점)
본 연구는 activation steering을 text-conditioned flow matching으로 재정의함으로써 모델 제어의 효율성과 범용성을 획기적으로 향상시켰습니다. 개별 태스크마다 인터벤션 모듈을 학습할 필요 없이, 단일 모델로 다양한 텍스트 조건 하에서 LLM의 내적 상태를 정교하게 조절할 수 있다는 점은 향후 AI 모델의 안전성 및 맞춤형 배포 측면에서 중요한 학술적 진전을 의미합니다. 다만, 강력한 제어 능력만큼이나 부적절한 persona를 유도하거나 오용될 가능성에 대한 안전성 보완이 향후 연구 과제로 남으며, 본 연구는 해석 가능한 LLM 제어 인터페이스 설계에 기여할 것으로 기대됩니다.
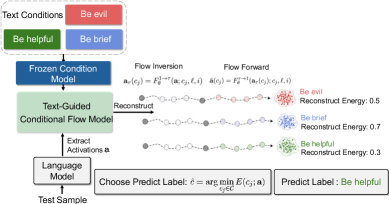
Figure 2 — 활성화 공간 기반 분류 절차
⚠️ 알림: 이 리뷰는 AI로 작성되었습니다.
관련 포스트
- [논문리뷰] Xiaomi-Robotics-1: Scaling Vision-Language-Action Models with over 100K Hours of Real-World Trajectories
- [논문리뷰] MeanFlowNFT: Bringing Forward-Process RL to Average-Velocity Generators
- [논문리뷰] GigaWorld-Policy-0.5: A Faster and Stronger WAM Empowered by AutoResearch
- [논문리뷰] LATO.2: Factorized 3D Mesh Generation with Vertex and Topology Flow
- [논문리뷰] Flow-ERD: Agent-type Aware Flow Matching with Entropy-Regularized Distillation for Diverse Traffic Simulation
Review 의 다른글
- 이전글 [논문리뷰] UI-KOBE: Knowledge-Oriented Behavior Exploration for Lightweight Graph-Guided GUI Agents
- 현재글 : [논문리뷰] UniSteer: Text-Guided Flow Matching in Activation Space for Versatile LLM Steering
- 다음글 [논문리뷰] Uniform Diffusion Models Revisited: Leave-One-Out Denoiser and Absorbing State Reformulation
댓글