[논문리뷰] Uniform Diffusion Models Revisited: Leave-One-Out Denoiser and Absorbing State Reformulation
링크: 논문 PDF로 바로 열기
저자: Samson Gourevitch, Yazid Janati, Dario Shariatian, et al.
1. Key Terms & Definitions (핵심 용어 및 정의)
- Uniform Diffusion Models (UDM): 데이터의 각 위치를 독립적으로 uniform 분포에서 샘플링된 토큰으로 치환하여 노이즈를 주입하는 이산 확산 모델입니다.
- Leave-one-out (LOO) Denoiser: 특정 위치 $\ell$의 토큰을 예측할 때, 해당 위치의 노이즈가 섞인 관측값을 제외한 나머지 모든 위치의 정보를 사용하는 예측 모델입니다.
- Bridge Plug-in Parameterization: 확산 모델의 역방향 전이(reverse transition)를 정의하기 위해 신경망의 출력을 직접 노이즈 제거 과정의 bridge 함수에 대입하는 기법입니다.
- Absorbing State Reformulation: 특정 토큰(마스크 등)을 흡수 상태로 설정하여 UDM의 결합 확률 법칙을 보존하면서도 샘플링 효율과 구조적 단순함을 개선한 재정의 모델입니다.
2. Motivation & Problem Statement (연구 배경 및 문제 정의)
본 논문은 UDM에서 사용되는 Bridge Plug-in 파라미터화가 표준적인 노이즈 제거 목표(denoising posterior)를 최적화하지 못한다는 구조적 불일치 문제를 해결합니다. 기존의 많은 UDM 연구들은 이 파라미터화가 denoising posterior를 학습한다고 가정했으나, 저자들은 이 ELBO가 실제로는 Leave-one-out posterior를 타겟팅하고 있음을 이론적으로 증명합니다. Masked Diffusion Models (MDM)에서는 이러한 차이가 은폐되어 있으나, UDM에서는 이로 인해 학습 성능의 저하와 정량적인 gap이 발생합니다. 본 연구는 이러한 파라미터화의 불일치를 규명하고, 이를 수정하여 UDM의 생성 품질을 개선하는 것을 목표로 합니다.
3. Method & Key Results (제안 방법론 및 핵심 결과)
본 연구는 Leave-one-out 파라미터화를 통해 UDM의 최적화 효율과 생성 성능을 극대화하는 새로운 훈련 타겟과 샘플링 전략을 제안합니다. 저자들은 Denoiser와 Leave-one-out 예측기, 그리고 score 간의 exact conversion 공식[11], [12]을 유도하여, 모델 아키텍처 변경 없이도 학습된 모델을 효율적으로 보정하거나 predictor-corrector 샘플러에 활용할 수 있게 했습니다. 또한, Absorbing State Uniform Diffusion Model (AUDM)과 Masked Uniform Diffusion Model (MUDM)을 설계하여, UDM의 marginals을 유지하면서도 MDM의 효율적인 구조를 도입했습니다[Table 1]. 대규모 언어 모델링(LM1B, OWT) 및 Sudoku 실험 결과, Leave-one-out 파라미터화는 일반적인 Denoiser 대비 일관되게 우수한 perplexity와 generative frontier를 보여주었습니다. 특히, AUDM은 기존 UDM의 marginals를 보존하면서도 여러 벤치마크 데이터셋에서 Masked Diffusion의 성능을 상회하거나 대등한 결과를 기록하였습니다.
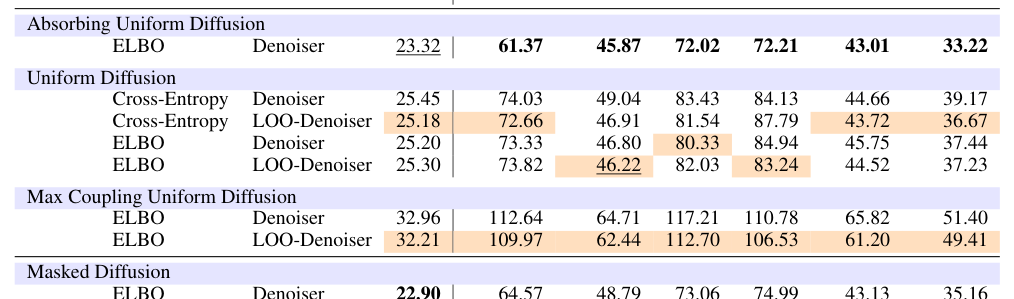
Table 1 — 다양한 모델 기법 및 학습 방식에 따른 언어 모델링 성능 비교를 보여주는 핵심 테이블
4. Conclusion & Impact (결론 및 시사점)
본 논문은 UDM의 성능 격차가 단순한 corruption marginals의 차이가 아닌, 학습 파라미터화와 샘플링 디자인에서 기인함을 규명하며, Leave-one-out 기반의 최적화가 필수적임을 제시합니다. 본 연구에서 제안한 파라미터 변환 및 흡수 상태 재정의 기법은 추가적인 학습 비용 없이도 모델의 추론 성능을 개선할 수 있는 강력한 도구를 제공합니다. 이는 향후 이산 확산 모델의 학습 구조를 설계함에 있어, 이론적 타당성을 갖춘 objective 선택과 파라미터화 전략의 중요성을 강조합니다.
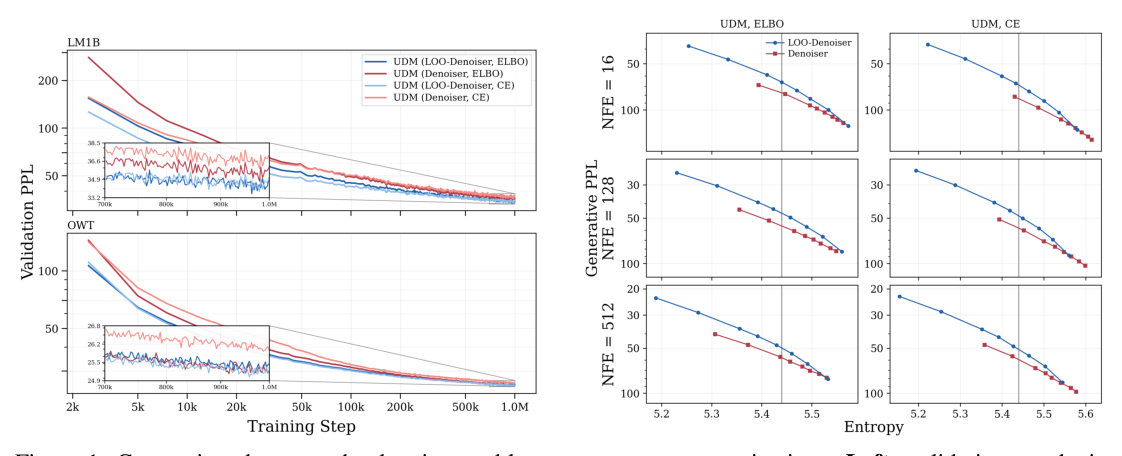
Figure 1 — Denoiser 대비 LOO 파라미터화가 훈련 중 perplexity 및 생성 성능(Gen-PPL)에서 우월함을 보여주는 그래프
⚠️ 알림: 이 리뷰는 AI로 작성되었습니다.
관련 포스트
- [논문리뷰] Discrete-WAM: Unified Discrete Vision-Action Token Editing for World-Policy Learning
- [논문리뷰] MMaDA-VLA: Large Diffusion Vision-Language-Action Model with Unified Multi-Modal Instruction and Generation
- [논문리뷰] LLaDA-o: An Effective and Length-Adaptive Omni Diffusion Model
- [논문리뷰] The Design Space of Tri-Modal Masked Diffusion Models
- [논문리뷰] MolHIT: Advancing Molecular-Graph Generation with Hierarchical Discrete Diffusion Models
Review 의 다른글
- 이전글 [논문리뷰] UniSteer: Text-Guided Flow Matching in Activation Space for Versatile LLM Steering
- 현재글 : [논문리뷰] Uniform Diffusion Models Revisited: Leave-One-Out Denoiser and Absorbing State Reformulation
- 다음글 [논문리뷰] Verifiable Rewards Beyond Math and Code: Lightweight Corpus-Grounded Process Supervision for Factual Question Answering
댓글