[논문리뷰] Discrete-WAM: Unified Discrete Vision-Action Token Editing for World-Policy Learning
링크: 논문 PDF로 바로 열기
메타데이터
저자: Ziyang Yao, Haochen Liu, Yuncheng Jiang, Zeyu Zhu, Zibin Guo, Jingru Wang, Tianle Liu, Jianwei Cui, Kuiyuan Yang, Hongwei Xie, Jingwei Zhao, Guang Chen, Hangjun Ye
1. Key Terms & Definitions (핵심 용어 및 정의)
- Discrete-WAM: 시각적 관측값, 행동(Action), 의사결정(Decision) 토큰을 동일한 이산(Discrete) 잠재 공간에서 처리하여 인과적 추론을 수행하는 통합 프레임워크.
- Token Editing: 노이즈가 섞인 토큰 시퀀스를 입력받아, 정해진 문맥(Context) 하에서 깨끗한(Clean) 타겟 토큰으로 정제하는 Discrete Diffusion 기반의 생성 방식.
- World-Policy Modeling: 미래의 시각적 상태(World)와 행동(Policy)을 개별적인 객체가 아닌, 하나의 생성 과정 안에서 상호 의존적인 변수로 모델링하는 방식.
- Hierarchical Decision-Planning: 고수준의 Decision Skeleton(의사결정)을 먼저 예측하고, 이를 바탕으로 저수준의 Action Token을 생성하여 행동의 일관성을 유지하는 계층적 정책 구조.
- Soft-Label Interpolation: 연속적인 가속도(Acceleration) 값을 이산적인 행동 어휘(Action Vocabulary)로 변환할 때 발생하는 양자화 오차를 줄이기 위해, 주변 프로토타입 간의 가중치를 사용하는 기법.
2. Motivation & Problem Statement (연구 배경 및 문제 정의)
본 논문은 기존 자율주행 시스템이 행동 조건부 동역학(Action-conditioned dynamics)을 명시적으로 모델링하지 못하고, 단순한 Direct State-to-Action Mapping에 의존한다는 근본적인 한계를 해결하고자 한다 [Figure 1]. 기존 모델들은 연속적인 잠재 공간에서 작동하여 데이터의 연속성은 보장하지만, 인과적 추론이나 반사실적(Counterfactual) 분석에 필수적인 명시적 의미론적 구성력(Compositional Semantics)이 부족하다. 또한, 세계 모델과 정책 학습이 별도의 모듈로 분리되어 있어, 관측값과 행동, 그리고 그로 인해 발생하는 미래 상태 간의 일관된 인과적 대응 관계를 확보하기 어렵다. 이에 저자들은 이산적인 토큰 인터페이스를 통해 세계 상태와 정책을 통합적으로 생성하는 새로운 접근 방식을 제안한다.
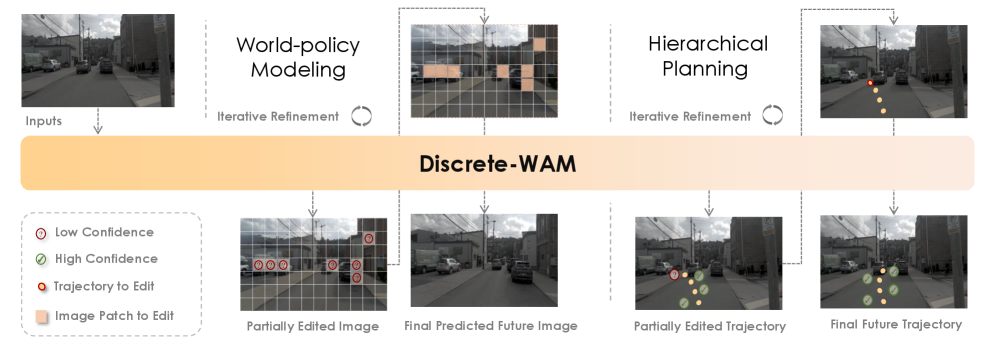
Figure 1 — Discrete-WAM 전체 개요
3. Method & Key Results (제안 방법론 및 핵심 결과)
Discrete-WAM은 시각적 관측값, 의사결정, 행동을 공통된 이산 토큰 공간으로 투영하여 Transformer 기반의 통합 생성 모델로 학습한다 [Figure 2]. 핵심 방법론인 Unified Pretraining은 1) 세계 모델링(미래 시각 상태 예측), 2) 세계-정책 모델링(행동 및 상태 동시 예측), 3) 정책 모델링(의사결정 조건부 행동 생성)이라는 세 가지 태스크를 하나의 Discrete Diffusion 프레임워크 안에서 결합한다 [Figure 3]. 행동 예측 시에는 Hierarchical Decision-Planning을 도입하여 고수준의 maneuver intent를 먼저 확정함으로써, 모드 붕괴(Mode collapse)를 방지하고 시간적 일관성을 확보한다. 실험 결과, 본 모델은 대규모 자율주행 벤치마크에서 기존 End-to-End 베이스라인 대비 계획(Planning) 성능 면에서 우위를 점하였다. 특히, Soft-Label Interpolation을 통해 연속 제어값의 재구성 오차를 최소화하였으며, Counterfactual Reasoning과 안전성 평가(Safety-aware evaluation) 등 복합적인 생성 능력을 입증하였다.
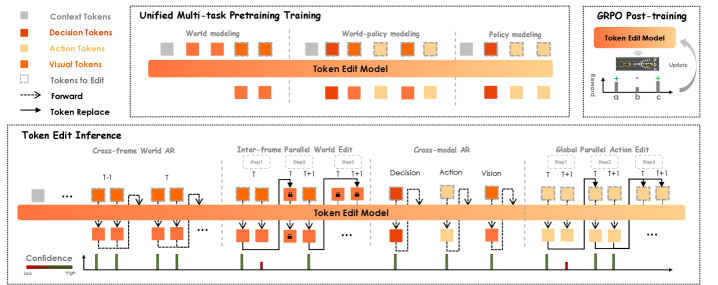
Figure 2 — 모델 아키텍처
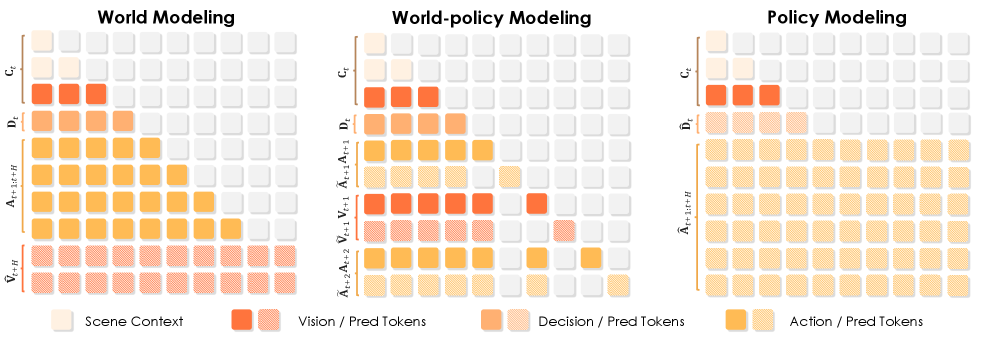
Figure 3 — 태스크별 어텐션 마스킹
4. Conclusion & Impact (결론 및 시사점)
Discrete-WAM은 자율주행의 핵심을 단순한 반응형 모방 학습에서 의사결정 기반의 세계 모델링으로 전환하는 구조적 프레임워크를 제시한다. 통합된 이산 토큰 인터페이스와 다중 태스크 학습을 통해 관측값과 행동 사이의 인과적 관계를 명확히 함으로써, 더욱 신뢰 가능한 Embodied Intelligence의 기반을 마련했다. 이 연구는 향후 복잡한 상호작용 환경에서 자율주행 시스템이 대안적 미래를 시뮬레이션하고 반사실적으로 추론할 수 있는 능력을 강화하는 데 중요한 기여를 할 것으로 기대된다.
⚠️ 알림: 이 리뷰는 AI로 작성되었습니다.
관련 포스트
- [논문리뷰] MMaDA-VLA: Large Diffusion Vision-Language-Action Model with Unified Multi-Modal Instruction and Generation
- [논문리뷰] UniUGP: Unifying Understanding, Generation, and Planing For End-to-end Autonomous Driving
- [논문리뷰] Rethinking Driving World Model as Synthetic Data Generator for Perception Tasks
- [논문리뷰] Discrete Diffusion for Reflective Vision-Language-Action Models in Autonomous Driving
- [논문리뷰] Genie Envisioner: A Unified World Foundation Platform for Robotic Manipulation
Review 의 다른글
- 이전글 [논문리뷰] Complexity-Balanced Diffusion Splitting
- 현재글 : [논문리뷰] Discrete-WAM: Unified Discrete Vision-Action Token Editing for World-Policy Learning
- 다음글 [논문리뷰] Dream.exe: Can Video Generation Models Dream Executable Robot Manipulation?
댓글