[논문리뷰] Verifiable Rewards Beyond Math and Code: Lightweight Corpus-Grounded Process Supervision for Factual Question Answering
링크: 논문 PDF로 바로 열기
메타데이터
저자: Shicheng Fan, Haochang Hao, Dehai Min, Weihao Liu, Philip S. Yu, Lu Cheng
1. Key Terms & Definitions (핵심 용어 및 정의)
- CorVer: Wikipedia co-occurrence 통계를 활용하여 문장 단위의 factual correctness를 평가하는 경량화된 process reward 프레임워크입니다.
- GRPO (Group Relative Policy Optimization): 명시적인 value model 없이 그룹 내 생성된 completion들의 보상을 정규화하여 정책을 업데이트하는 RL 알고리즘입니다.
- Infini-gram: 거대 규모의 텍스트 말뭉치에서 n-gram 빈도와 공기(co-occurrence) 통계를 효율적으로 조회하기 위한 인덱싱 엔진입니다.
- Process Supervision: 답변 전체의 정확도(outcome-level)뿐만 아니라, reasoning trace 내의 개별 문장이나 단계가 사실에 부합하는지 평가하는 기법입니다.
- Self-filter: RL 학습에 사용할 최적의 데이터를 선별하기 위해, raw 모델이 생성한 completion들의 정확도를 측정하여 난이도별(learning-zone)로 필터링하는 절차입니다.
2. Motivation & Problem Statement (연구 배경 및 문제 정의)
본 논문은 지식 집약적 QA 작업에서 LLM의 사실적 정확도를 높이기 위한 효율적인 보상 신호가 부족하다는 점을 문제로 지적합니다. 기존의 결과 단위(outcome-level) 보상은 세부적인 추론 과정의 오류를 판별하지 못하며, 최근의 문장 단위(process-level) 보상 방식들은 NLI verifier나 LLM judge를 사용하여 RL 학습 시 비용이 매우 높다는 한계가 있습니다 [Figure 1]. 특히 이러한 신경망 기반 verifier들은 모델의 매개변수적 지식에 의존하여 희귀 엔티티(rare-entity)에 대한 지식 공백을 공유하므로, 정작 모델이 신뢰할 수 있는 가이드가 필요한 상황에서 정보력이 떨어진다는 문제가 있습니다.
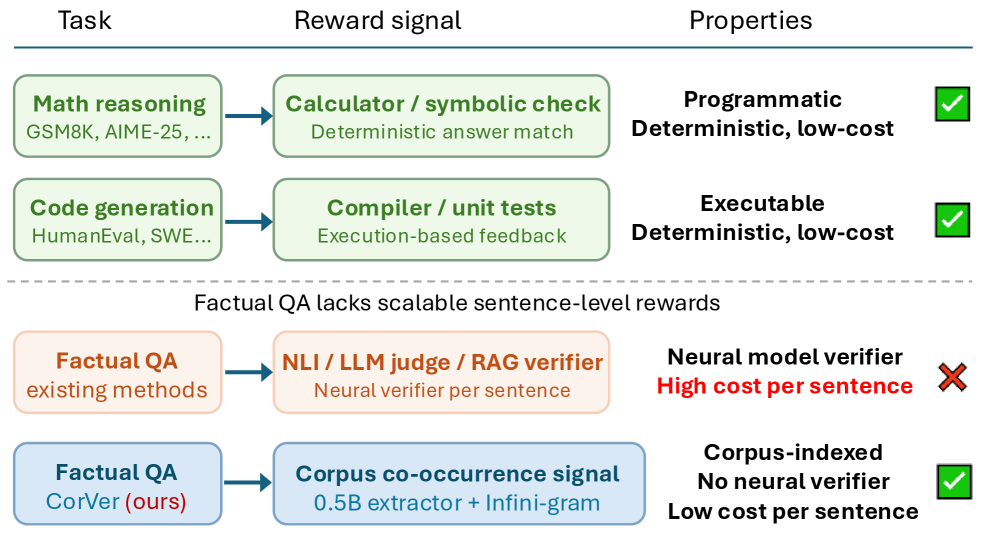
Figure 1 — 수학/코드와 사실적 QA의 보상 방식 비교
3. Method & Key Results (제안 방법론 및 핵심 결과)
본 논문은 신경망 기반의 verifier 없이 Wikipedia co-occurrence 통계를 이용하는 경량화된 보상 프레임워크인 CorVer를 제안합니다 [Figure 2]. CorVer는 생성된 문장에서 subject-object 쌍을 추출한 뒤, Infini-gram 인덱스를 사용하여 말뭉치 내 공기 횟수를 조회하고, 이를 기반으로 문장 단위의 보상을 할당합니다. 이 보상 신호는 토큰 단위의 이득(token-level advantage)으로 매핑되어 모델이 사실적 문장에 높은 점수를 부여하도록 학습시킵니다.
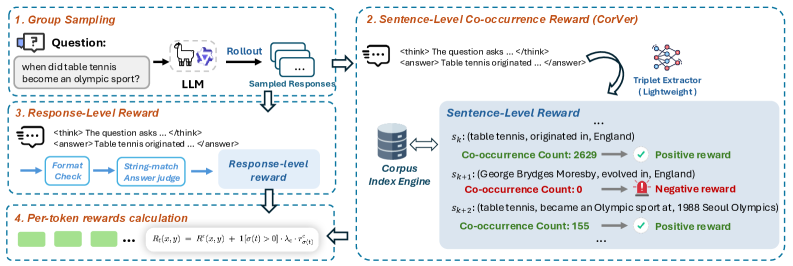
Figure 2 — CorVer의 파이프라인 아키텍처
주요 실험 결과는 다음과 같습니다:
- 3B부터 14B 규모의 6개 모델과 5개 QA 벤치마크에 걸쳐 CorVer는 모든 셀에서 Raw 모델 대비 성능 향상을 보였으며, TriviaQA에서 평균 +4.1 pp의 향상을 기록했습니다 [Figure 3].
- CorVer는 신경망 기반의 4개 baseline(FoRAG, RLFH, FSPO, KnowRL)보다 20개 셀 중 18개에서 우수한 성능을 보였으며, 학습 속도는 4.8배에서 8.4배 더 빨랐습니다 [Figure 4].
- 실험을 통해 Wikipedia 공기 횟수가 실제 문장의 사실적 정확도와 단조 증가(monotonically)하는 상관관계를 가짐을 증명하여 보상 신호의 신뢰성을 확인했습니다 [Figure 5].
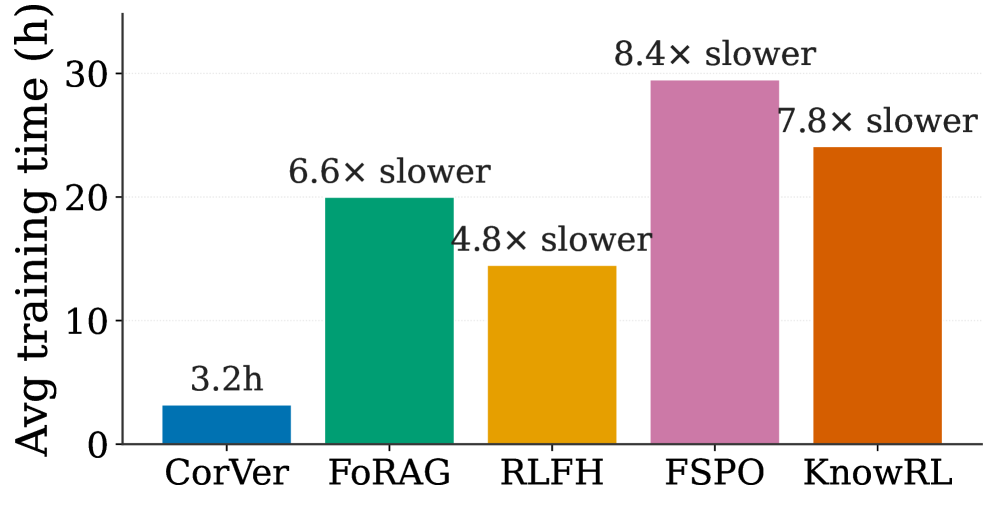
Figure 4 — 방법론별 학습 시간 비교
4. Conclusion & Impact (결론 및 시사점)
본 논문은 Corpus-grounded 신호를 통해 LLM의 사실적 정확도를 높이는 효율적인 process reward 설계 방향을 제시합니다. CorVer는 고비용의 신경망 verifier를 배제하고도 우수한 학습 효율성과 성능을 입증함으로써, 자원 제약이 있는 환경에서도 사실적 정렬(factual alignment)을 수행할 수 있는 실용적인 솔루션을 제공합니다. 이 연구는 향후 다양한 RL 파이프라인에서 경량화된 보상 신호를 결합하거나, 더 대규모의 웹 데이터셋으로 인덱스를 확장하는 연구의 기초가 될 것으로 기대됩니다.
⚠️ 알림: 이 리뷰는 AI로 작성되었습니다.
관련 포스트
- [논문리뷰] Agon: Competitive Cross-Model RL with Implicit Rival Grading of Reasoning
- [논문리뷰] Learning User Simulators with Turing Rewards
- [논문리뷰] N-GRPO: Embedding-Level Neighbor Mixing for Enhanced Policy Optimization
- [논문리뷰] WebGen-R1: Incentivizing Large Language Models to Generate Functional and Aesthetic Websites with Reinforcement Learning
- [논문리뷰] FIPO: Eliciting Deep Reasoning with Future-KL Influenced Policy Optimization
Review 의 다른글
- 이전글 [논문리뷰] Uniform Diffusion Models Revisited: Leave-One-Out Denoiser and Absorbing State Reformulation
- 현재글 : [논문리뷰] Verifiable Rewards Beyond Math and Code: Lightweight Corpus-Grounded Process Supervision for Factual Question Answering
- 다음글 [논문리뷰] When Cloud Agents Meet Device Agents: Lessons from Hybrid Multi-Agent Systems
댓글