[논문리뷰] Learning User Simulators with Turing Rewards
링크: 논문 PDF로 바로 열기
메타데이터
저자: Yingshan Susan Wang, Cedegao E. Zhang, Linlu Qiu, Zexue He, Pengyuan Li, Alex Pentland, Roger P. Levy, Yoon Kim
1. Key Terms & Definitions (핵심 용어 및 정의)
- Turing-RL: Discriminative Turing reward를 활용하여 LLM 기반 사용자 시뮬레이터를 학습시키는 강화학습 프레임워크입니다.
- Turing Reward: LLM Judge가 생성된 응답과 실제 인간의 응답을 비교하여, 어느 쪽이 더 인간에 의해 작성되었는지 1~7점 척도로 평가한 점수 기반 보상입니다.
- GRPO (Group Relative Policy Optimization): 본 논문에서 정책을 최적화하기 위해 사용한 RL 알고리즘으로, 그룹 내 보상을 정규화하여 학습의 효율성을 높입니다.
- SFT (Supervised Fine-Tuning): RL 학습 전, Chain-of-Thought reasoning trace를 포함한 실제 사용자 응답 데이터로 모델을 초기화하는 Warm-start 단계입니다.
2. Motivation & Problem Statement (연구 배경 및 문제 정의)
본 논문은 기존의 사용자 시뮬레이터 학습 방식이 실제 인간의 행동을 충분히 모사하지 못하는 근본적인 한계를 해결하고자 합니다. 기존 연구들은 주로 Log-probability 최대화 또는 Ground truth 응답과의 단순 Similarity를 측정하는 방식에 의존해 왔습니다. 하지만 인간의 응답은 매우 다양하기 때문에, 단일한 Ground truth에 맞추는 방식은 인간 특유의 스타일이나 맥락 적응력을 완벽히 재현하기 어렵습니다. 저자들은 시뮬레이터가 인간의 응답과 구분할 수 없는(Indistinguishable) 특성을 갖추는 것이 목표이며, 이를 위해 Turing Test 원리를 학습 신호로 도입합니다 [Figure 1].
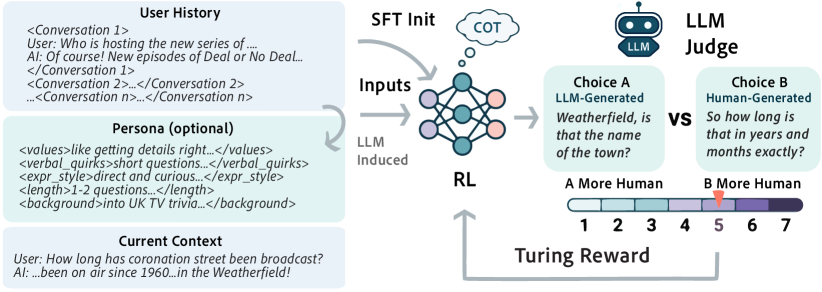
Figure 1 — Turing-RL 전체 아키텍처
3. Method & Key Results (제안 방법론 및 핵심 결과)
본 논문은 Turing-RL을 제안하며, LLM Judge가 생성된 응답과 실제 사용자 응답을 비교하여 더 인간 같은 것을 평가하는 Discriminative Turing Reward를 활용합니다. 모델은 SFT로 초기화된 후, GRPO를 통해 Turing reward를 최대화하는 방향으로 최적화됩니다 [Figure 1]. 실험 결과, Turing-RL은 Multi-turn chat(PRISM) 및 Reddit 토론 도메인 모두에서 기존의 Sim-RL(유사도 기반 보상) 및 Logprob-RL보다 우수한 Turing distinguishability 성능을 보였습니다 [Figure 2]. 특히, Turing-RL은 인간과 구분하기 어려운 높은 성능을 달성하면서도, Sim-RL과 대등한 수준의 Response similarity를 유지하여 내용 측면에서도 정밀함을 입증했습니다 [Figure 3]. 추가적으로, Turing-RL과 Sim-RL은 인간 참여 평가에서도 SFT-Init 모델 대비 통계적으로 유의미한 성능 향상을 보여주었습니다 [Table 1].

Figure 2 — 모델별 인간 유사성 비교
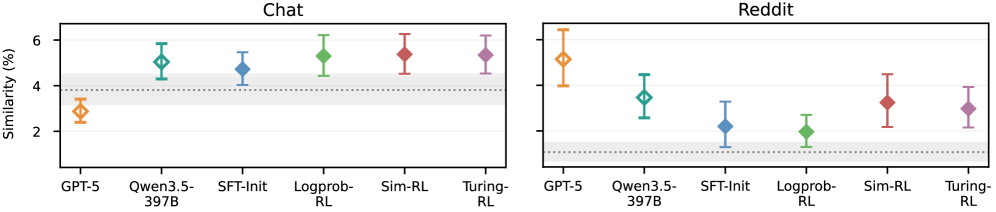
Figure 3 — Ground truth 응답 유사도
4. Conclusion & Impact (결론 및 시사점)
본 연구는 사용자 시뮬레이션 학습에 있어 Ground truth 모방보다 Indistinguishability 최적화가 더 효과적인 접근 방식임을 증명합니다. Turing-RL 프레임워크를 통해 학습된 모델은 인간과 더 유사한 응답을 생성하며, 이는 향후 에이전트 시스템 평가나 사회과학 연구를 위한 강력한 도구로 활용될 수 있습니다. 연구진은 이러한 기술이 임포스네이션(Impersonation) 등 악용될 가능성을 경고하며, 안전한 사용을 위한 워터마킹 및 생성 모델 탐지 기술의 병행 발전을 강조합니다. 본 연구는 LLM 기반 사용자 모델링 분야에서 새로운 평가 지표와 학습 패러다임을 제시했다는 점에서 중요한 학술적 의미를 가집니다.
⚠️ 알림: 이 리뷰는 AI로 작성되었습니다.
관련 포스트
- [논문리뷰] N-GRPO: Embedding-Level Neighbor Mixing for Enhanced Policy Optimization
- [논문리뷰] Verifiable Rewards Beyond Math and Code: Lightweight Corpus-Grounded Process Supervision for Factual Question Answering
- [논문리뷰] WebGen-R1: Incentivizing Large Language Models to Generate Functional and Aesthetic Websites with Reinforcement Learning
- [논문리뷰] FIPO: Eliciting Deep Reasoning with Future-KL Influenced Policy Optimization
- [논문리뷰] RetroAgent: From Solving to Evolving via Retrospective Dual Intrinsic Feedback
Review 의 다른글
- 이전글 [논문리뷰] LLM-Enabled NWDAF: A Step Toward AI-Native 6G Network Intelligence
- 현재글 : [논문리뷰] Learning User Simulators with Turing Rewards
- 다음글 [논문리뷰] Morpheus: A Morphology-Aware Neural Tokenizer and Word Embedder for Turkish
댓글