[논문리뷰] DRIFT: Decoupled Rollouts and Importance-Weighted Fine-Tuning for Efficient Multi-Turn Optimization
링크: 논문 PDF로 바로 열기
메타데이터
저자: Jian Mu, Tianyi Lin, Chengwei Qin, Zhongxiang Dai, Yao Shu
1. Key Terms & Definitions (핵심 용어 및 정의)
- DRIFT (Decoupled Rollouts and Importance-Weighted Fine-Tuning): 본 논문에서 제안하는 프레임워크로, KL-regularized RL 목표를 importance-weighted SFT로 변환하여 효율적인 다중 턴 최적화를 달성하는 방법론입니다.
- Rollout: 정책에 따라 환경과 상호작용하며 생성된 일련의 대화 경로(trajectory)를 의미하며, 기존 online RL에서는 이 과정의 비용이 최적화의 주요 병목 현상이었습니다.
- Importance Weighting: reference policy로부터 샘플링된 데이터를 optimal distribution에 맞춰 재가중치(weight)를 부여하여, 명시적인 온라인 상호작용 없이도 최적화 목표를 달성하게 하는 수학적 기법입니다.
- Terminal-Step Retention: 효율적인 학습을 위해 전체 대화 경로 대신, 마지막 응답 단계의 데이터와 가중치만을 사용하여 모델을 업데이트하는 최적화 전략입니다.
2. Motivation & Problem Statement (연구 배경 및 문제 정의)
본 연구는 다중 턴 상호작용 환경에서 LLM을 효율적으로 최적화해야 하는 과제를 해결합니다. 기존 online RL 방법론은 다중 턴 역학을 효과적으로 학습할 수 있으나, 업데이트마다 전체 대화 경로를 생성해야 하는 높은 계산 비용(rollout cost)으로 인해 실용성이 낮습니다 [Figure 1]. 반면, SFT는 학습 효율성은 높지만 데이터 분포 변화와 행동 붕괴(behavioral collapse) 문제로 인해 정교한 수정 정책을 학습하는 데 한계가 있습니다. 이러한 효율성과 효과성 사이의 딜레마를 극복하기 위해, 본 논문은 비용이 많이 드는 rollout 과정을 최적화 과정으로부터 완전히 분리하는 새로운 접근 방식을 제안합니다.

Figure 1 — 다중 턴 상호작용 과정
3. Method & Key Results (제안 방법론 및 핵심 결과)
본 논문은 KL-regularized RL 목표가 importance-weighted supervised learning과 수학적으로 등가임을 입증하고, 이를 구현한 DRIFT 프레임워크를 제안합니다 [Figure 2]. DRIFT는 두 단계로 구성되는데, 첫 번째 단계는 고정된 reference policy를 사용하여 오프라인에서 대화 경로를 샘플링하고 가중치를 계산하는 것이며, 두 번째 단계는 이 가중치를 적용한 weighted SFT를 통해 모델을 업데이트하는 것입니다 [Figure 2]. 이론적으로 이 가중치는 보상(return)의 지수 함수와 정규화 항의 비율로 도출되며, 이는 모델이 고성능 경로에 더 많은 확률 질량을 할당하도록 유도합니다 [Figure 3]. 실험 결과, DRIFT는 다양한 수학적 및 일반 추론 벤치마크에서 기존 online RL 베이스라인과 대등하거나 능가하는 성능을 보였습니다 [Table 1]. 특히, 턴 수가 증가하더라도 SFT와 유사한 낮은 계산 복잡도를 유지하며 높은 학습 효율성을 기록했습니다 [Figure 6].
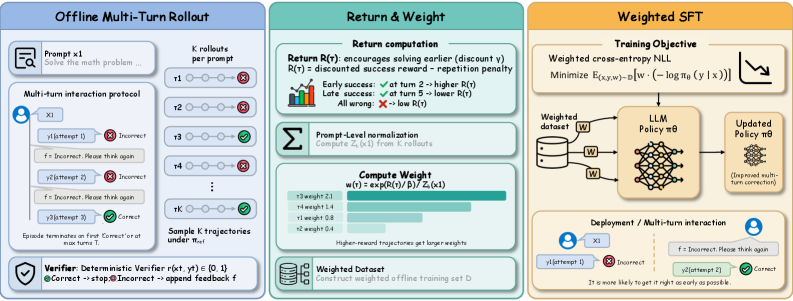
Figure 2 — DRIFT 프레임워크 개요
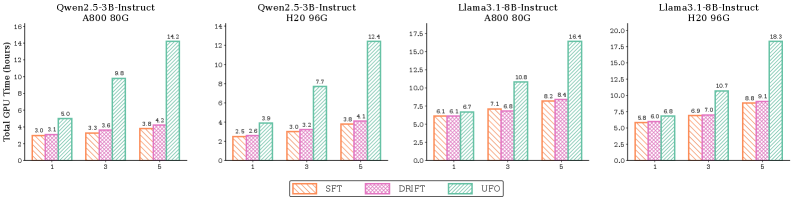
Figure 6 — 학습 효율성 비교
4. Conclusion & Impact (결론 및 시사점)
본 논문은 DRIFT를 통해 다중 턴 최적화의 난제였던 높은 비용 문제를 해결하고, RL의 목표를 효과적인 SFT로 구현할 수 있음을 입증했습니다. 이 연구는 단순히 계산 효율성을 높이는 것을 넘어, 다중 턴 상호작용 환경에서 모델의 오류 수정 능력을 안정적으로 향상시킬 수 있는 실용적인 프레임워크를 제공합니다. 향후 LLM의 에이전트화 및 복잡한 대화 시스템 설계에 있어 정교한 온라인 RL의 대안으로서 중요한 기여를 할 것으로 기대됩니다.
⚠️ 알림: 이 리뷰는 AI로 작성되었습니다.
관련 포스트
- [논문리뷰] UP: Unbounded Positive Asymmetric Optimization for Breaking the Exploration-Stability Dilemma
- [논문리뷰] ProAct: Agentic Lookahead in Interactive Environments
- [논문리뷰] Language-based Trial and Error Falls Behind in the Era of Experience
- [논문리뷰] ASPO: Asymmetric Importance Sampling Policy Optimization
- [논문리뷰] Benefits and Pitfalls of Reinforcement Learning for Language Model Planning: A Theoretical Perspective
Review 의 다른글
- 이전글 [논문리뷰] Count Anything
- 현재글 : [논문리뷰] DRIFT: Decoupled Rollouts and Importance-Weighted Fine-Tuning for Efficient Multi-Turn Optimization
- 다음글 [논문리뷰] DecMem: Towards Minute-Long Consistent World Generation with Decoupled Memory
댓글