[논문리뷰] Count Anything
링크: 논문 PDF로 바로 열기
저자: Mengqi Lei, Shuokun Cheng, Wei Bao, Shaoyi Du, Jun-Hai Yong, Siqi Li, Yue Gao
## 1. Key Terms & Definitions (핵심 용어 및 정의)
- CLOC: 본 연구에서 구축한 대규모 Cross-domain Object Counting 벤치마크 데이터셋으로, 220K개의 이미지와 619개의 카테고리, 15M개의 인스턴스를 포함함.
- RSC (Region-level Sparse Counter): DETR-like 아키텍처를 기반으로 sparse한 영역 제안을 통해 대형 및 희소 객체를 정확하게 탐지하는 카운터.
- PDC (Pixel-level Dense Counter): 고해상도 특징 맵 상에서 dense한 포인트 회귀를 수행하여 작고 밀집된 객체를 효과적으로 카운트하는 카운터.
- CCF (Complementary Count Fusion): RSC와 PDC의 결과를 결합하여 중복 예측을 억제하고 상호 보완적인 카운팅 결과를 산출하는 파라미터 프리 Fusion 기법.
- Point-centric supervision: 박스나 포인트 등 이기종 주석(heterogeneous annotations)을 통합하여 모델을 학습시키는 일관된 카운팅 supervision 전략.
## 2. Motivation & Problem Statement (연구 배경 및 문제 정의) 본 연구는 객체 카운팅 분야가 특정 도메인(군중, 차량, 세포 등)에 편향된 데이터셋과 모델로 인해 파편화되어 있다는 점을 핵심 문제로 정의한다. 기존 연구들은 일반화 성능이 낮고, 개별 도메인에 종속된 카운팅 모델은 다양한 스케일과 밀도 분포를 가진 현실 세계의 객체를 효과적으로 처리하지 못한다. 특히 밀도 맵(density map) 기반의 기존 방식들은 개별 인스턴스에 대한 해석 가능성이나 정확한 위치 정보 제공에 한계를 가진다. 따라서 연구진은 텍스트 가이드를 기반으로 다양한 도메인을 아우르며 인스턴스 단위의 해석 가능한 결과를 제공하는 일반주의 모델을 개발하고자 한다 [Figure 1].
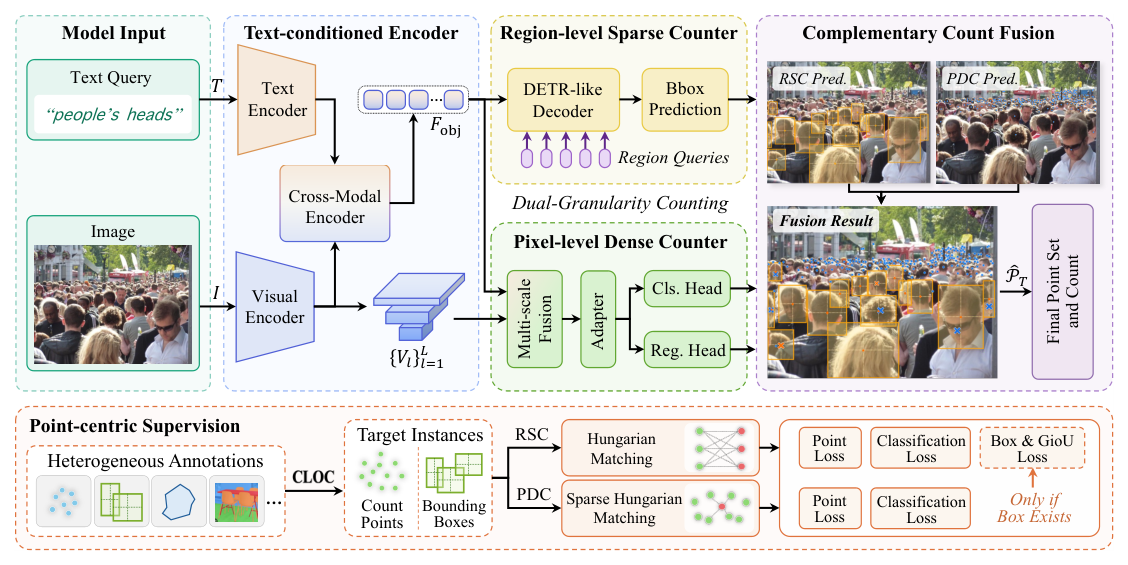
Figure 1 — 모델의 전반적인 프레임워크와 RSC/PDC 구조를 설명하는 핵심 다이어그램
## 3. Method & Key Results (제안 방법론 및 핵심 결과) 본 연구는 Count Anything이라 명명된 프레임워크를 제안하며, 이는 region-level의 RSC와 pixel-level의 PDC를 결합한 dual-granularity 인스턴스 열거 기법을 핵심으로 한다. Count Anything은 SAM3 기반의 Text-Conditioned Encoder를 사용하여 입력 이미지와 텍스트 쿼리를 정렬하고, 각 카운터가 처리하기 어려운 영역을 상호 보완하도록 설계되었다 [Figure 1]. 학습 시에는 포인트 중심의 supervision을 통해 다양한 어노테이션 포맷을 통합 관리하며, 추론 시에는 CCF를 통해 중복 카운트를 제거한다. 실험 결과, 제안 모델은 CLOC 벤치마크에서 기존의 open-world 카운팅 모델들을 큰 격차로 압도하는 성능을 보여주었다. [Table 1]에 따르면, Count Anything은 9.34의 MAE와 33.34의 RMSE를 달성하여 비교 대상 중 가장 우수한 카운팅 정확도를 증명하였다.
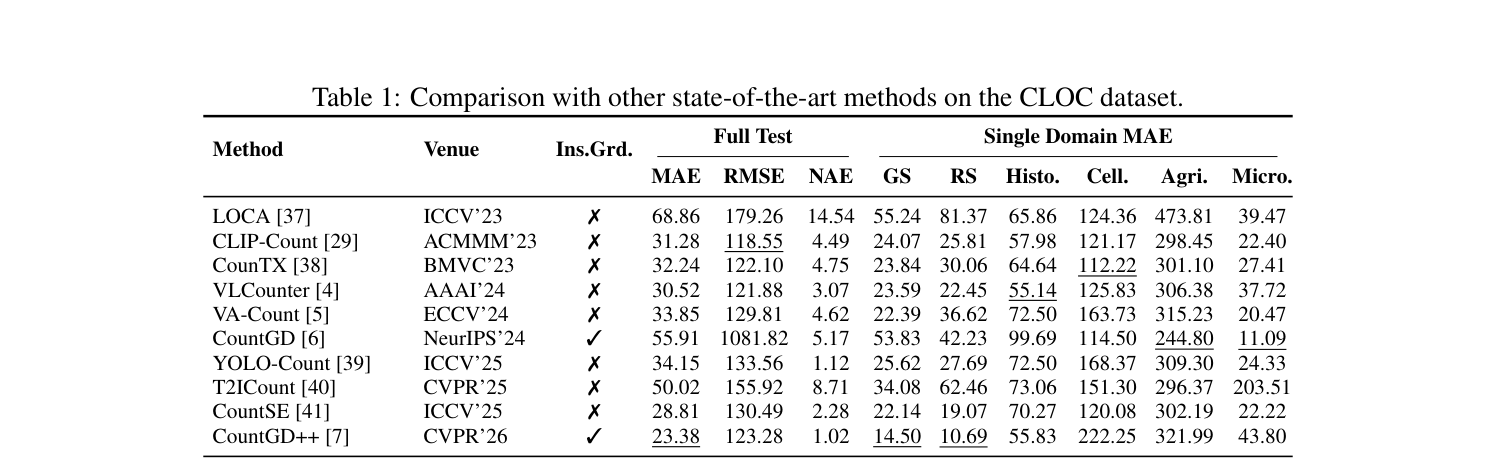
Table 1 — CLOC 데이터셋에서의 최신 모델들과의 성능 비교를 나타내는 핵심 결과표
## 4. Conclusion & Impact (결론 및 시사점) 본 논문은 대규모 데이터셋인 CLOC 구축과 이기종 도메인을 처리하는 Count Anything 모델을 통해 일반주의 객체 카운팅의 새로운 표준을 제시한다. 이 연구는 특정 도메인에 고착된 기존 카운팅 기술의 한계를 넘어섰다는 점에서 의미가 크며, 특히 해석 가능한 포인트 단위 인스턴스 예측 기법은 산업계의 다양한 카운팅 자동화 요구에 기여할 수 있다. 향후 멀티모달 대형 언어 모델과의 결합을 통한 더욱 고도화된 추론 능력의 확장이 기대된다.

Table 5 — 제안한 dual-granularity 구조와 퓨전 규칙의 유효성을 보여주는 핵심 ablation 결과표
⚠️ 알림: 이 리뷰는 AI로 작성되었습니다.
관련 포스트
- [논문리뷰] Memory Transfer Learning: How Memories are Transferred Across Domains in Coding Agents
- [논문리뷰] OneThinker: All-in-one Reasoning Model for Image and Video
- [논문리뷰] LLMs4All: A Review on Large Language Models for Research and Applications in Academic Disciplines
- [논문리뷰] Visual Representation Alignment for Multimodal Large Language Models
- [논문리뷰] xHC: Expanded Hyper-Connections
댓글