[논문리뷰] Comprehensive Benchmarking of Long-Form Speech Generation in Diverse Scenarios
링크: 논문 PDF로 바로 열기
저자: Changhao Pan, Rui Yang, Han Wang, et al.
1. Key Terms & Definitions (핵심 용어 및 정의)
- SwanBench-Speech: Long-form speech 및 dialog generation 모델의 성능을 체계적으로 평가하기 위해 설계된 포괄적인 벤치마크 프레임워크입니다.
- Acoustics, Semantics, Expressiveness: 벤치마크가 평가하고자 하는 3가지 핵심 도전 과제로, 음향 품질, 언어적 정확성, 감정적 표현력을 각각 지칭합니다.
- Expressive Hierarchy: 문장 단위를 넘어선 단락(paragraph) 수준의 감정적 변화와 발성 동역학을 평가하는 지표입니다.
- LALMs (Large Audio-Language Models): 본 논문에서 제안한 자동화된 평가 프로토콜을 수행하기 위해 사용된, 높은 인간 정렬도를 가진 대규모 오디오-언어 모델입니다.
2. Motivation & Problem Statement (연구 배경 및 문제 정의)
본 논문은 Long-form speech generation 분야의 시스템적 평가가 체계적이지 못하다는 문제를 해결하기 위해 제안되었다. 기존 연구들은 제한된 도메인이나 단일 화자 설정에 머물러 있어, 실제 복잡한 하위 응용 프로그램과의 괴리가 존재한다. 또한 기존의 문장 단위 평가 지표들은 긴 텍스트 문맥에서의 일관성이나 응집력을 충분히 반영하지 못하며, 휴먼 평가의 높은 비용과 확장성 문제로 인해 표준화된 자동화 프로토콜이 결여되어 있다. 이에 저자들은 1,101개의 샘플을 포함하는 포괄적인 벤치마크인 SwanBench-Speech를 제안하며, 7가지 세분화된 지표를 통해 이를 극복하고자 한다 [Figure 1].
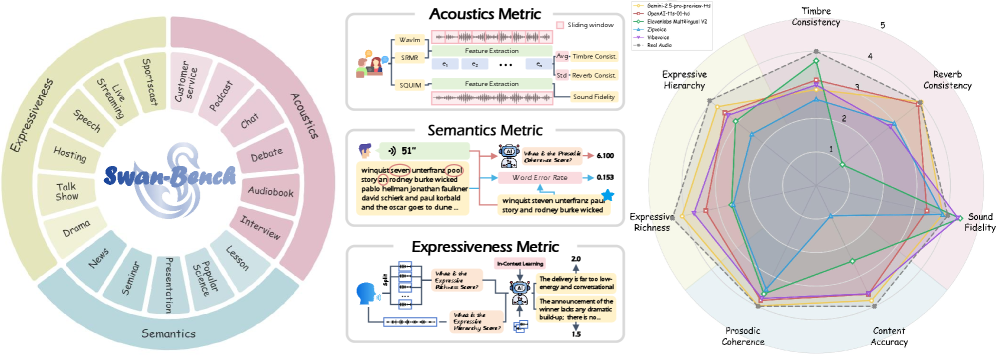
Figure 1 — SwanBench-Speech 아키텍처
3. Method & Key Results (제안 방법론 및 핵심 결과)
저자들은 17개의 하위 음성 생성 시나리오를 바탕으로 Acoustics, Semantics, Expressiveness라는 3개 축을 정의하고 이를 평가하기 위한 7가지 objective metric을 수립했다. 데이터 구축을 위해 웹 크롤링, LLM 생성을 활용하였으며, 의미적 중복 제거, 품질 평가, 윤리적 필터링을 거쳐 데이터의 신뢰성을 확보했다 [Figure 2]. 실험 결과, 최신 모델들은 Fidelity나 Accuracy 측면에서는 인간의 녹음 수준에 도달했으나, Reverb Consistency, Prosodic Coherence, Expressive Hierarchy 등 긴 문맥이 요구되는 영역에서는 여전히 상당한 격차가 존재함을 확인했다 [Table 2]. 특히 highly expressive 시나리오에서의 성능 저하가 두드러졌으며, AR(Autoregressive)과 NAR(Non-Autoregressive) 구조 간의 trade-off가 명확히 드러났다 [Figure 3]. 모델들은 특히 긴 시퀀스 길이에서 content accuracy 저하를 보이거나 표현력의 한계를 노출했으며, 이는 향후 Coarse-to-Fine Architecture 도입의 필요성을 시사한다 [Figure 4].
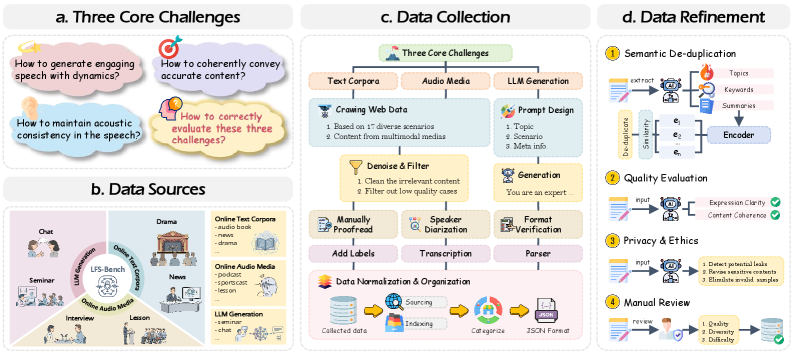
Figure 2 — 데이터 구축 및 정제 프로세스
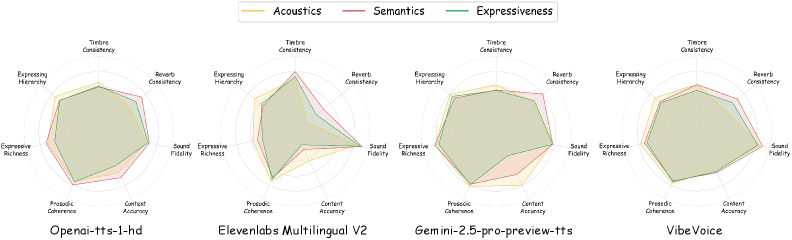
Figure 3 — 3대 핵심 과제 평가 결과
4. Conclusion & Impact (결론 및 시사점)
본 연구는 Long-form speech generation의 평가를 위한 standardized benchmark인 SwanBench-Speech를 통해 해당 분야의 평가 프로토콜을 정립했다. 연구진은 20개 이상의 모델을 벤치마킹하여 현재 생성 모델들의 기술적 한계를 구체적으로 제시하였으며, 이는 향후 더 견고하고 몰입감 있는 음성 생성 모델 개발을 위한 이정표가 될 것이다. 또한, 모델 아키텍처 개선뿐만 아니라 데이터의 품질과 시퀀스 연속성을 고려한 학습 전략이 차세대 모델 발전의 핵심임을 시사한다.
⚠️ 알림: 이 리뷰는 AI로 작성되었습니다.
관련 포스트
- [논문리뷰] QVal: Cheaply Evaluating Dense Supervision Signals for Long-Horizon LLM Agents
- [논문리뷰] CODA-BENCH: Can Code Agents Handle Data-Intensive Tasks?
- [논문리뷰] ViGoR-Bench: How Far Are Visual Generative Models From Zero-Shot Visual Reasoners?
- [논문리뷰] Omni-WorldBench: Towards a Comprehensive Interaction-Centric Evaluation for World Models
- [논문리뷰] AI Gamestore: Scalable, Open-Ended Evaluation of Machine General Intelligence with Human Games
Review 의 다른글
- 이전글 [논문리뷰] COLLEAGUE.SKILL: Automated AI Skill Generation via Expert Knowledge Distillation
- 현재글 : [논문리뷰] Comprehensive Benchmarking of Long-Form Speech Generation in Diverse Scenarios
- 다음글 [논문리뷰] Count Anything
댓글