[논문리뷰] Not All Disagreement Is Learnable: Token Teachability in On-Policy Distillation
링크: 논문 PDF로 바로 열기
메타데이터
저자: Yuanyi Wang, Su Lu, Yanggan Gu, Pengkai Wang, Yifan Yang, Zhaoyi Yan, Congkai Xie, Jianmin Wu, Hongxia Yang et al.
1. Key Terms & Definitions (핵심 용어 및 정의)
- OPD (On-policy Distillation): 학생 모델이 자신의 rollouts에서 생성한 컨텍스트를 활용하여 교사(Teacher) 모델의 토큰 단위 확률 분포를 모방하도록 학습하는 기법입니다.
- Fixed-Context Diagnostic: 학생이 생성한 컨텍스트를 고정(Freeze)한 상태에서, 교사와 학생 모델의 KL-divergence 감소량을 측정하여 특정 토큰이 모델 학습에 얼마나 실질적인 기여를 하는지 진단하는 평가 프로토콜입니다.
- Token Teachability: 교사의 확률 질량(Mass)이 학생의 로컬 확률 분포(Top-KK 지원 범위)와 얼마나 정렬되어 있는지를 나타내는 지표로, 교사의 교정 신호가 학생에게 흡수될 수 있는 정도를 의미합니다.
- Learnable Disagreement ($D_t^L$): 교사가 학생의 Top-KK 후보군 내에 보정 질량을 배치하여, 학생이 학습 가능한 방향으로 KL 격차를 줄이는 유용한 불일치 상태입니다.
- Incompatible Disagreement ($D_t^I$): 교사가 학생의 현재 지원 범위를 벗어난 영역에 불일치 질량을 두어, KL 격차는 크지만 실제 모델 개선 효과는 낮은 비효율적인 불일치 상태입니다.
2. Motivation & Problem Statement (연구 배경 및 문제 정의)
본 논문은 기존의 Selective OPD 기법들이 단순히 토큰의 불확실성(Entropy)이나 교사-학생 간의 불일치(Divergence)만을 토큰 선택 기준으로 삼는 한계를 해결하고자 합니다. 기존 연구들은 불일치가 큰 토큰이 학습에 유리하다고 가정하지만, 실제로는 교사가 제시하는 보정 신호가 학생 모델의 현재 상태와 호환되지 않는 경우가 많습니다 [Figure 1]. 이러한 '호환되지 않는 불일치(Incompatible Disagreement)'는 높은 KL 격차를 발생시키지만 학습 효과는 떨어뜨리는 노이즈로 작용합니다. 따라서 저자들은 어떤 교사의 신호가 학생에게 실제로 '학습 가능한(Teachable)' 것인지 진단하고, 이를 기반으로 효율적인 토큰 선택 전략을 수립해야 할 필요성을 제기합니다.
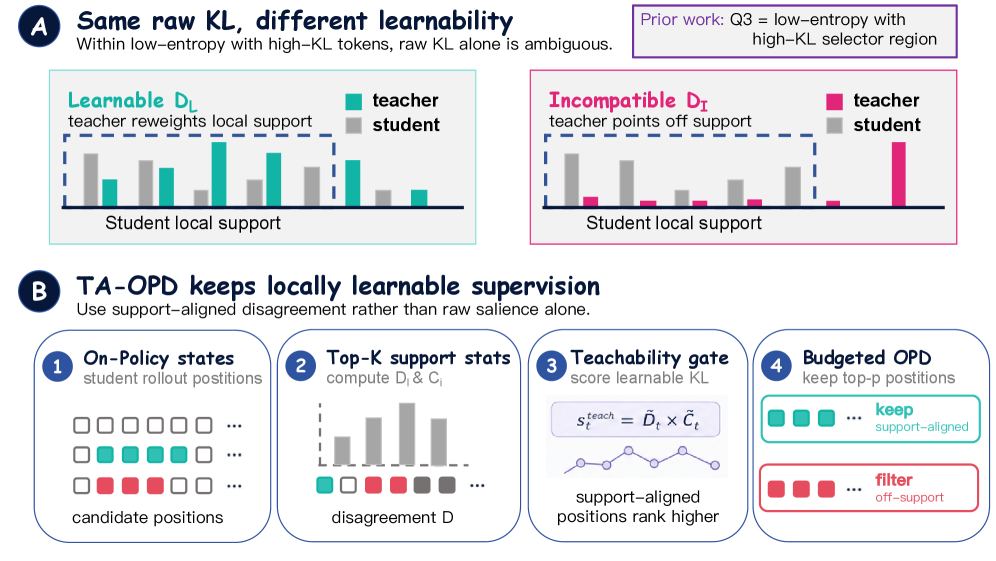
Figure 1 — 토큰 학습 가능성 개념도 및 TA-OPD 파이프라인
3. Method & Key Results (제안 방법론 및 핵심 결과)
본 논문은 토큰의 학습 가능성을 수치화한 TA-OPD (Teachability-Aware OPD) 프레임워크를 제안합니다 [Figure 1]. 저자들은 로컬 지원 범위 내에서의 교사-학생 일치도를 계산하여 Teachability Score를 산출하고, 이를 바탕으로 불필요한 노이즈를 제거한 뒤 높은 학습 가치를 지닌 토큰만을 선별하여 OPD Loss를 적용합니다 [Figure 2]. 이 방법론은 별도의 보상 모델(Reward Model)이나 검증기(Verifier) 없이도 모델 자체의 확률 분포 정보만으로 수행 가능한 경량 기법입니다 [Figure 1].
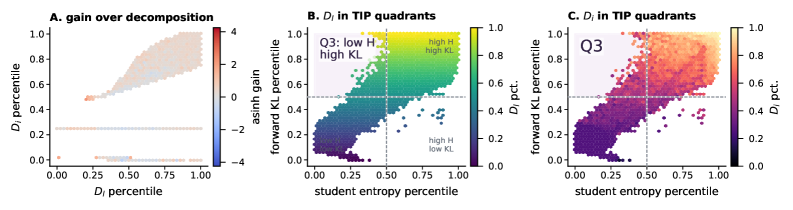
Figure 2 — 로컬 지원 범위 분해 및 학습 가능성 비교
실험 결과, TA-OPD는 Qwen3 및 Qwen2.5 설정에서 전체 토큰 학습 대비 5%의 토큰만 사용하고도 성능을 유지하거나 상회하는 결과를 보였습니다 [Table 3]. 정량적으로는 기존 Entropy 및 Divergence 기반 선택 기법들보다 고정된 컨텍스트 환경에서 더 높은 KL 감소율과 학습 효율을 입증하였습니다 [Table 2]. 또한, TA-OPD는 10%의 예산 제약 조건하에서 다양한 벤치마크(AIME, GPQA-Diamond, IFEval 등) 평균 점수에서 기존 TIP 대비 뛰어난 성능 우위를 기록하였습니다 [Table 3, Table 4].
4. Conclusion & Impact (결론 및 시사점)
본 논문은 OPD의 효율성이 단순히 촘촘한 토큰 supervision에 달려 있는 것이 아니라, 교사가 제공하는 신호의 '로컬 호환성'에 있음을 입증하였습니다. Token Teachability라는 개념을 통해 기존의 무분별한 selective distillation 기법을 학습 가치 중심의 프레임워크로 재정의하였으며, 이는 모델 경량화 및 효율적인 정렬(Alignment) 분야에 중요한 시사점을 제공합니다. 본 연구는 LLM 학습 시 컴퓨팅 자원의 낭비를 줄이면서도 실질적인 성능 향상을 도모할 수 있는 실용적인 토큰 선택 가이드라인을 제시합니다.
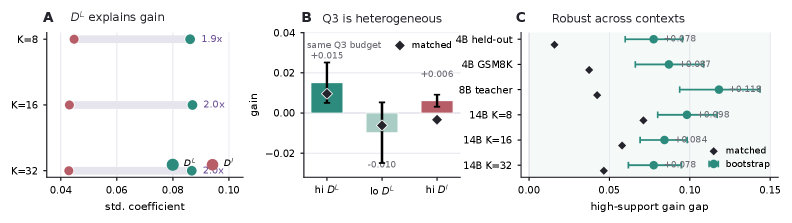
Figure 3 — 고정 컨텍스트 기반 학습 가능성 실증
⚠️ 알림: 이 리뷰는 AI로 작성되었습니다.
관련 포스트
Review 의 다른글
- 이전글 [논문리뷰] Memory-Bound but Not Bandwidth-Limited: The Physical AI Inference Gap in Batch-1 LLM Decode
- 현재글 : [논문리뷰] Not All Disagreement Is Learnable: Token Teachability in On-Policy Distillation
- 다음글 [논문리뷰] One Click per Cell Type Suffices: Training-free Group Interaction for Cell Instance Segmentation
댓글