[논문리뷰] Less is More: Early Stopping Rollout for On-Policy Distillation
링크: 논문 PDF로 바로 열기
메타데이터
저자: Zhou Ziheng, Jiaqi Li, Huacong Tang, Ying Nian Wu, Demetri Terzopoulos, et al.
## 1. Key Terms & Definitions (핵심 용어 및 정의)
- OPD (On-Policy Distillation): 학생 모델이 스스로 생성한 Rollout을 교사 모델(Teacher)이 평가하여, 그 점수를 바탕으로 학습하는 지식 증류 패러다임입니다.
- Off-policy Teacher Decay: 학생이 생성한 Rollout이 길어질수록 문맥이 교사 모델의 분포에서 벗어나게 되며, 이로 인해 교사가 정확한 수정 신호를 제공하지 못하고 단순히 다음 토큰을 예측하는 방식으로 퇴화하는 현상입니다.
- ESR (Early Stopping Rollout): 교사의 왜곡된 신호를 방지하기 위해, 학생의 Rollout 생성 길이를 첫 N개의 토큰으로 제한하여 해당 구간 내에서만 손실(Loss)을 계산하는 방법론입니다.
- Cascading Alignment: ESR을 통해 초기 토큰만 학습하더라도, 모델의 이후 토큰에 대한 KL Divergence가 자동으로 감소하며 전역적인 정렬이 발생하는 현상입니다.
- Sub-mode Commitment: 학습 과정에서 교사가 지원하는 여러 모드 중 특정 모드에 집중하도록 함으로써, 학생 모델이 교사의 평균적인 행동을 단순히 모방하는 것을 넘어 성능을 뛰어넘게 되는 현상입니다.
## 2. Motivation & Problem Statement (연구 배경 및 문제 정의) 본 논문은 기존 OPD 방식에서 발생하는 Off-policy Teacher Decay 문제를 해결하기 위해 제안되었습니다 [Figure 1]. 저자들은 학생이 긴 Rollout을 생성할수록 해당 문맥이 교사 모델에게는 Off-policy 상태가 되어, 교사가 정확한 교정 신호를 제공하지 못하고 단순한 문장 완성(Auto-completion) 모델로 퇴화함을 확인했습니다. 기존의 전체 시퀀스 기반 학습은 이러한 신뢰할 수 없는 후반부 토큰까지 강제로 학습에 포함하여 증류 효율과 안정성을 저해한다는 한계가 있습니다 [Figure 1].
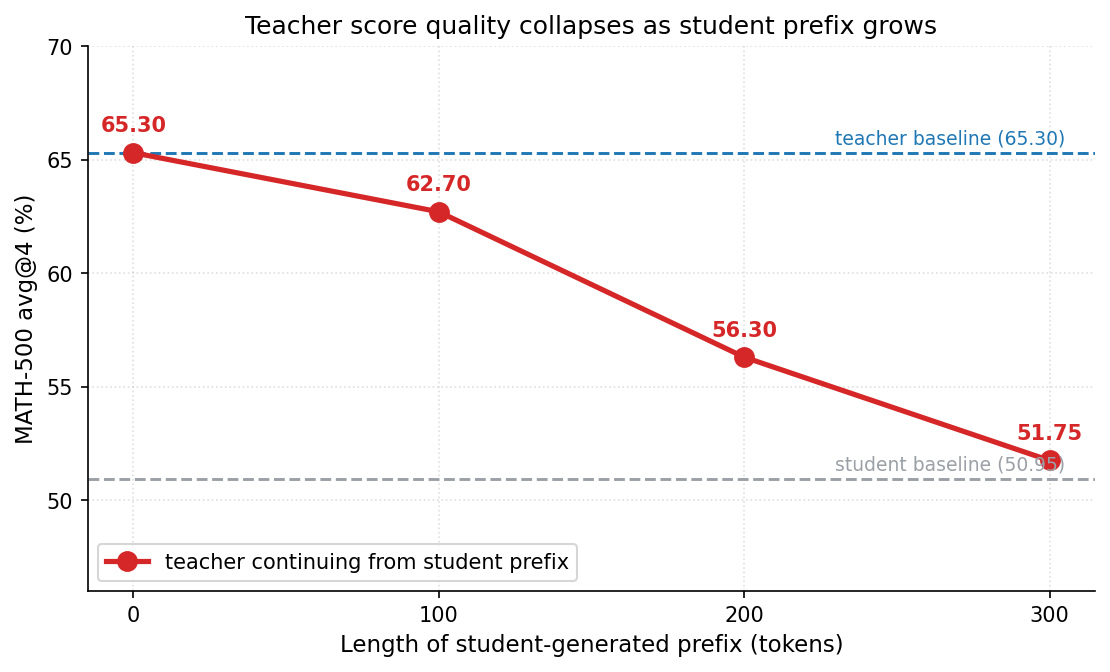
Figure 1 — Off-policy Teacher Decay 및 N sweep 성능
## 3. Method & Key Results (제안 방법론 및 핵심 결과) 본 논문은 학생의 Rollout을 초기 N개의 응답 토큰으로 제한하고 해당 구간에서만 Reverse KL Divergence를 계산하는 ESR을 제안합니다 [Figure 1]. 이 방법은 별도의 복잡한 수정 없이 학습 루프 내에서 단 한 줄의 코드 변경만으로 구현 가능합니다. 실험 결과, ESR은 다양한 모델 크기, 태스크(Math, Code, Function Calling), 그리고 학습 체계(LoRA, FFT)에서 기존 OPD를 능가하는 성능을 보였습니다 [Table 1], [Table 2]. 특히, ESR은 OPD 대비 GPU 연산 속도를 최대 24배 향상시키고, 피크 메모리 사용량을 약 4배 절감하는 높은 효율성을 입증했습니다 [Table 3]. 또한 Cascading Alignment를 통해 직접 학습하지 않은 후반부 토큰까지 정렬 효과가 전달됨을 확인하였으며, Sub-mode Commitment를 통해 학생 모델이 교사의 성능을 상회하는 결과를 도출했습니다 [Figure 2], [Figure 3].
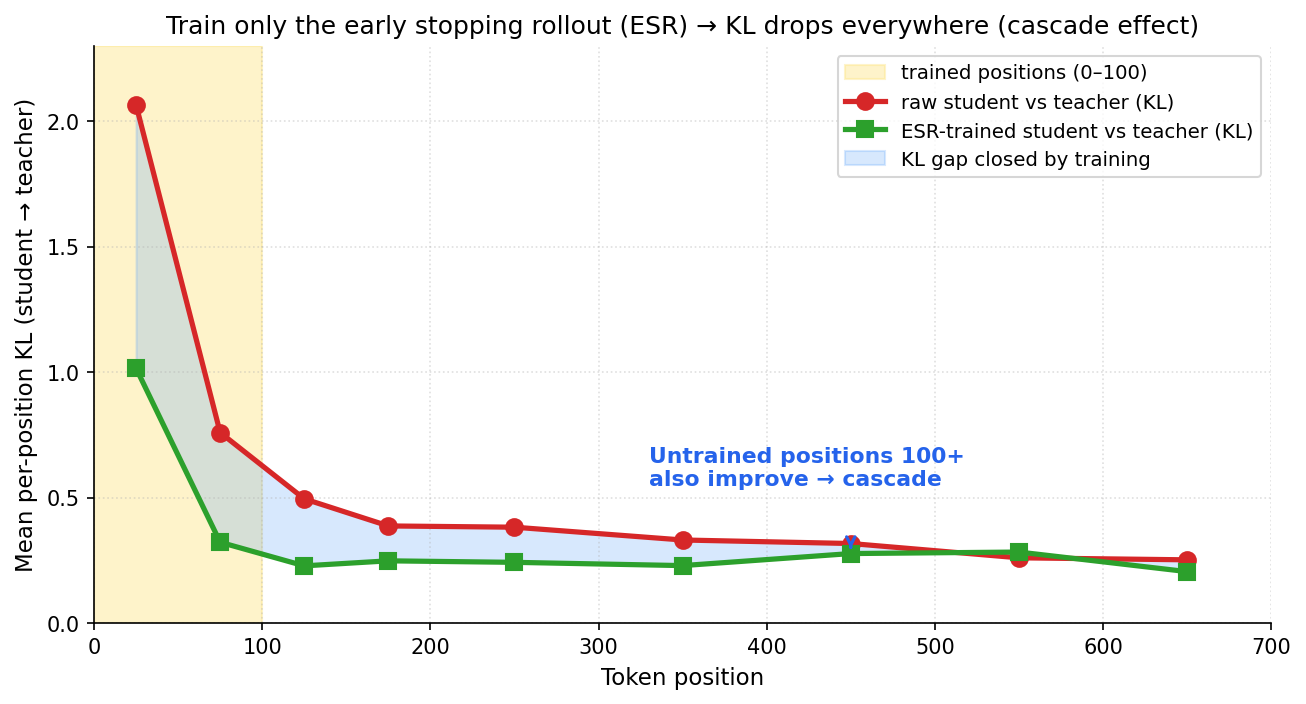
Figure 2 — Cascading Alignment 효과
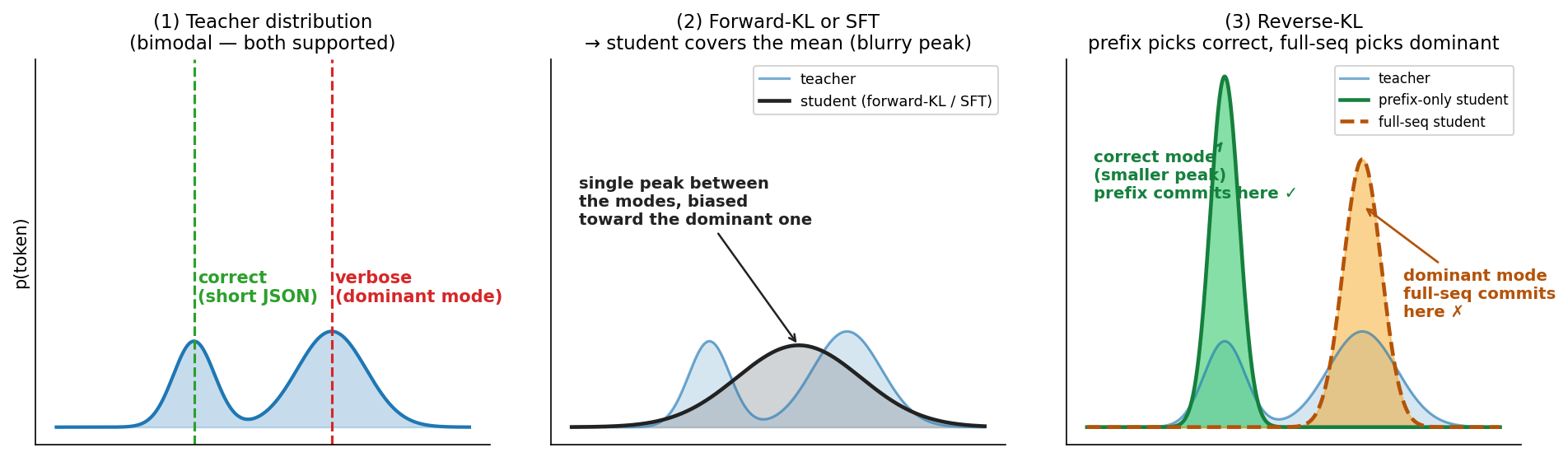
Figure 3 — Sub-mode Commitment 메커니즘
## 4. Conclusion & Impact (결론 및 시사점) 본 논문은 ESR이 OPD의 고질적인 문제인 Off-policy Teacher Decay를 완화하고 학습의 안정성과 효율성을 극대화하는 효과적인 기법임을 입증했습니다. 연구진은 위치(Position) 기반의 토큰 선택이 단순히 KL Divergence나 Entropy와 같은 지표로 치환될 수 없는 독립적인 핵심 차원임을 밝혀냈습니다 [Figure 4]. 이 연구는 LLM 지식 증류 분야에서 모델 정렬을 위한 최적의 학습 범위를 재정의하며, 향후 더 적은 자원으로 효율적이고 강력한 학생 모델을 구축하려는 학계 및 산업계 연구에 중요한 방법론적 토대를 제공합니다.
⚠️ 알림: 이 리뷰는 AI로 작성되었습니다.
관련 포스트
Review 의 다른글
- 이전글 [논문리뷰] Learn from Weaknesses: Automated Domain Specialization for Small Computer-Use Agents
- 현재글 : [논문리뷰] Less is More: Early Stopping Rollout for On-Policy Distillation
- 다음글 [논문리뷰] LiveBrowseComp: Are Search Agents Searching, or Just Verifying What They Already Know?
댓글