[논문리뷰] PEEK: Picking Essential frames via Efficient Knowledge distillation
링크: 논문 PDF로 바로 열기
메타데이터
저자: Killian Steunou, Anas Filali Razzouki, Khalil Guetari, Mounîm A. El-Yacoubi, Yannis Tevissen
1. Key Terms & Definitions (핵심 용어 및 정의)
- PEEK (Picking Essential frames via Efficient Knowledge distillation): 캡션 조건부 프레임 관련성 지식을 경량 템포럴 모델로 증류(distillation)하여 시각 정보만으로 핵심 프레임을 선택하는 프레임워크입니다.
- Oracle Teacher: SigLIP 2와 같은 강력한 비전-언어 모델을 활용하여, 비디오 프레임과 실제 캡션(ground-truth caption) 간의 관련성을 스코어링하여 학습 타겟을 생성하는 진단 도구입니다.
- Stratified Argmax: 비디오 세그먼트를 k개의 동일한 시간 윈도우로 분할하고, 각 윈도우 내에서 가장 높은 관련성 점수를 가진 프레임을 선택하는 추론 전략입니다.
- Query-free Selector: 추론 단계에서 텍스트 입력이나 캡션 생성 없이, 오직 비디오 프레임의 시각적 특징(visual embeddings)만을 기반으로 프레임을 선택하는 모듈입니다.
2. Motivation & Problem Statement (연구 배경 및 문제 정의)
본 논문은 현대의 Vision-Language Models (VLMs)가 비디오 이해를 위해 제한된 수의 프레임만을 처리할 수 있다는 병목 문제를 해결하는 데 목적이 있습니다. 기존의 Uniform sampling은 계산 비용은 낮으나 비디오의 정보 밀도를 반영하지 못하는 '콘텐츠 맹목(content-blind)'적인 한계를 지닙니다. 반면, 최근 제안된 적응형 샘플링 방식들은 계산 비용이 매우 높거나 쿼리 의존적인 방식을 사용하여 실시간성 확보에 어려움이 있습니다. 이를 극복하기 위해 저자들은 캡션 기반의 관련성 정보를 증류하여, 추론 시에는 시각 정보만으로도 핵심적인 프레임을 효율적으로 선택할 수 있는 PEEK를 제안합니다 [Figure 1].
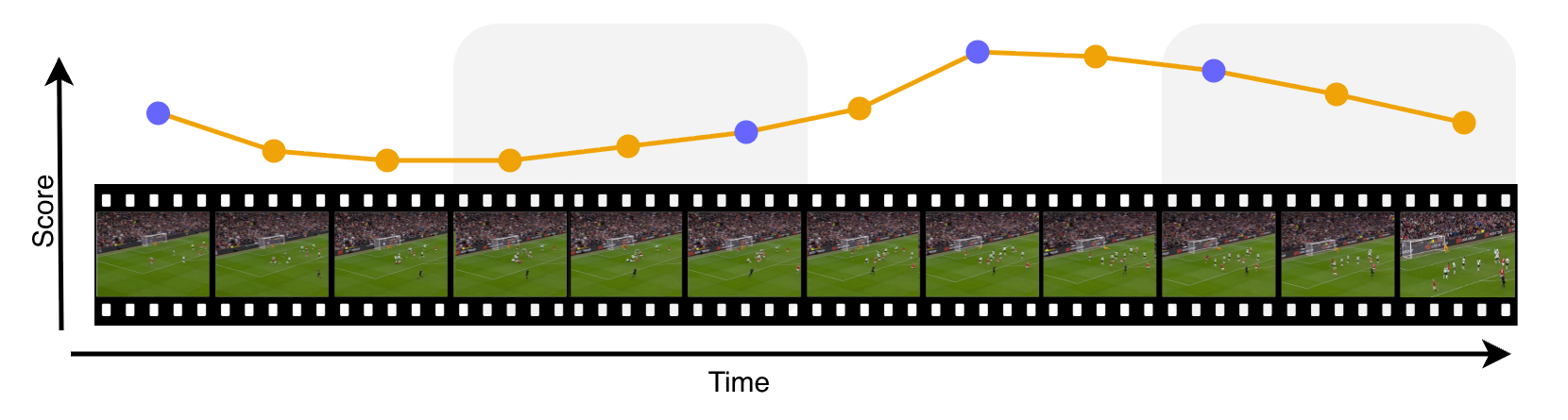
Figure 1 — PEEK 전체 프레임워크 아키텍처
3. Method & Key Results (제안 방법론 및 핵심 결과)
PEEK는 2단계 증류 프레임워크를 기반으로 하며, 1단계에서는 SigLIP 2 Teacher가 실제 캡션을 사용하여 각 프레임의 관련성을 스코어링하고, 2단계에서는 이 정보를 학습 가능한 경량 Transformer 모델(약 13.1M 파라미터)이 학습합니다 [Figure 1]. 학습 시에는 ListMLE 손실 함수를 사용하여 순위 결정(ranking) 문제를 최적화하며, 추론 시에는 텍스트 정보 없이 시각적 임베딩만을 입력받아 Stratified argmax 정책으로 프레임을 선택합니다 [Figure 1]. 실험 결과, ActivityNet Captions 및 MSR-VTT 데이터셋에서 PEEK는 k=1인 저예산 프레임 설정에서 기존 방식 대비 일관되게 가장 우수한 CIDEr 점수를 달성했습니다 [Table 2, Table 3]. 특히 효율성 측면에서 PEEK는 전체 캡션 생성 시간에 불과 5.2%의 오버헤드만을 추가하여, CSTA(65.4%)나 MaxInfo(211.9%)와 비교했을 때 압도적인 경량성을 입증했습니다 [Table 4].
4. Conclusion & Impact (결론 및 시사점)
본 논문은 캡션 기반의 관련성 지식을 시각적 모델로 효과적으로 증류함으로써, 추론 단계에서 쿼리 독립적인 고효율 프레임 선택이 가능함을 증명했습니다. PEEK는 특히 적은 프레임 수로 높은 품질의 캡션을 생성해야 하는 비디오 이해 태스크에서 강력한 성능과 효율성을 제공합니다. 이 연구는 비디오 모델의 추론 비용을 절감하는 동시에 성능을 유지하는 실용적인 경로를 제시하며, 향후 다양한 비디오 이해 응용 분야에서 핵심적인 전처리 모듈로 활용될 것으로 기대됩니다.
⚠️ 알림: 이 리뷰는 AI로 작성되었습니다.
관련 포스트
- [논문리뷰] LLMs4All: A Review on Large Language Models for Research and Applications in Academic Disciplines
- [논문리뷰] xHC: Expanded Hyper-Connections
- [논문리뷰] Xiaomi-Robotics-1: Scaling Vision-Language-Action Models with over 100K Hours of Real-World Trajectories
- [논문리뷰] When Does Muon Help Agentic Reinforcement Learning?
- [논문리뷰] VideoRAE: Taming Video Foundation Models for Generative Modeling via Representation Autoencoders
Review 의 다른글
- 이전글 [논문리뷰] OpenSkillEval: Automatically Auditing the Open Skill Ecosystem for LLM Agents
- 현재글 : [논문리뷰] PEEK: Picking Essential frames via Efficient Knowledge distillation
- 다음글 [논문리뷰] Recovering Policy-Induced Errors: Benchmarking and Trajectory Synthesis for Robust GUI Agents
댓글