[논문리뷰] VisualThink-VLA: Visual Intermediate Reasoning for Effective and Low-Latency Vision-Language-Action Policies
링크: 논문 PDF로 바로 열기
메타데이터
저자: Mingjian Gao, Wenqiao Zhang, Yuqian Yuan, Yang Dai, Binhe Yu, Zheqi Lv, Haoyu Zheng, Jiaqi Zhu, Zhiqi Ge, Zixuan Wan, Siliang Tang, Yueting Zhuang
1. Key Terms & Definitions (핵심 용어 및 정의)
- VLA (Vision-Language-Action) Policy: 시각적 관측값과 언어 지시사항을 입력받아 로봇의 제어 동작을 직접 출력하는 모델입니다.
- Visual Intermediate Reasoning: 텍스트 형태의 Chain-of-Thought(CoT) 대신, 시각적 근거를 바탕으로 단계적 사고를 수행하여 행동을 결정하는 프레임워크입니다.
- Task-Adaptive Orchestration: 실시간 상황에 맞게 필요한 시각적 증거 채널을 선택적으로 활성화하여 불필요한 연산 부하를 줄이는 동적 라우팅 기법입니다.
- VisualEvidence-Kit: 정책 학습을 감독하고, 모델의 추론 근거를 시각화 및 검증하기 위한 데이터셋 및 분석 리소스 세트입니다.
2. Motivation & Problem Statement (연구 배경 및 문제 정의)
본 논문은 기존 VLA 모델들이 겪는 '정확도와 효율성'의 상충 관계를 해결하고자 한다. 텍스트 기반의 Chain-of-Thought은 로봇 제어에 필요한 시각적 정보와 동떨어져 있을 뿐만 아니라, autoregressive decoding으로 인해 실시간 제어(closed-loop control)를 위한 대기 시간(latency)을 과도하게 발생시킨다. 반면, dense한 시각적 부가 정보는 불필요한 정보가 간섭을 일으켜 오히려 성능을 저하시키는 결과를 초래한다. 따라서 저자들은 텍스트 기반이 아닌 '시각적 영역(visual space)'에서 최소화된 시각적 근거를 선택적으로 활용하는 경량화된 중간 추론 프레임워크를 제안한다 [Figure 1].
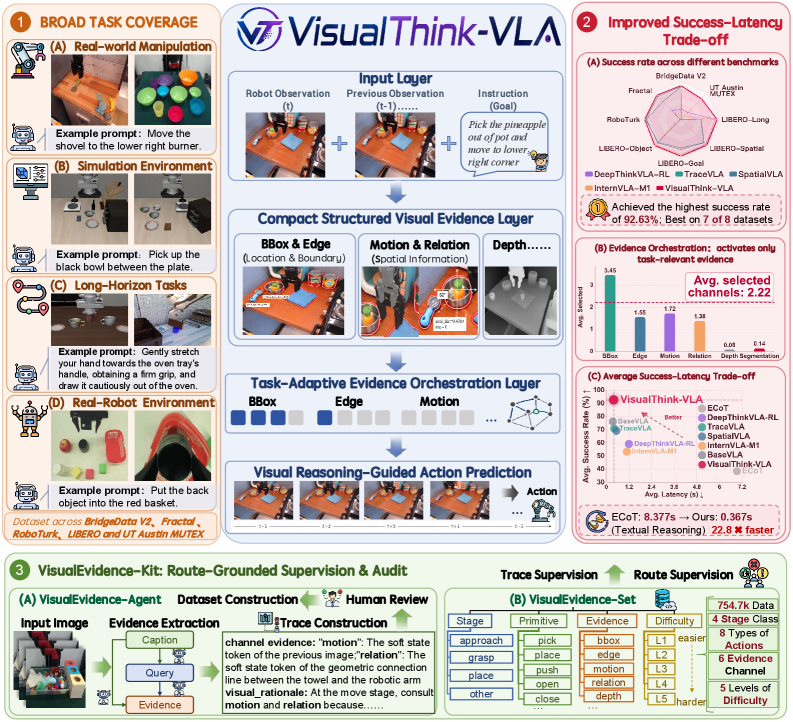
Figure 1 — VisualThink-VLA의 전체 프레임워크 개요
3. Method & Key Results (제안 방법론 및 핵심 결과)
본 논문은 VisualThink-VLA를 통해 frozen VLA backbone에 routed visual evidence를 주입하는 방식을 제안한다 [Figure 2]. 핵심 방법론은 6개의 후보 시각 채널(bbox, edge, motion, relation, depth, segment) 중 유효한 4개를 선별하고, task-adaptive router를 통해 매 단계 필요한 정보만 선택적으로 activation하는 sparse evidence routing이다. 또한, soft-hard collaborative masks와 dense teacher로부터의 logits distillation을 적용하여 sparse한 환경에서도 높은 성능을 유지한다. 실험 결과, BridgeData V2 벤치마크에서 기존 ECoT 방식의 8.377s step latency를 0.367s로 단축하며 약 22.8배의 속도 향상을 달성했다. 아울러 다수의 로봇 제어 벤치마크에서 BaseVLA 대비 우수한 success rate를 기록하며, real-world manipulation 및 장기 작업(long-horizon tasks)에서 효율적인 성공률을 입증하였다 [Table 2].
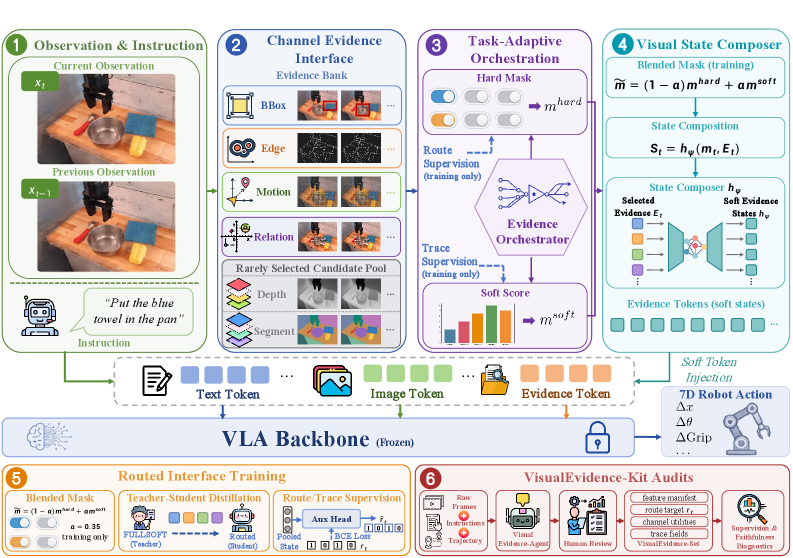
Figure 2 — VisualThink-VLA 파이프라인 구조
4. Conclusion & Impact (결론 및 시사점)
본 연구는 embodied control 환경에서 텍스트 기반 추론보다 시각적 근거 기반의 추론이 실시간성 및 효율성 측면에서 훨씬 우수함을 입증하였다. VisualThink-VLA는 기존 VLA 정책의 backbone을 변경하지 않고도 plug-and-play 형태의 시각적 추론 모듈을 도입할 수 있어 확장성이 뛰어나다. 제안된 VisualEvidence-Kit은 향후 VLA 모델의 의사결정 과정을 시각적으로 해석(audit)하고 검증하는 새로운 표준을 제시하며, 로봇 학습 분야에서 보다 신뢰성 있는 정책 설계를 가능하게 할 것으로 기대된다.
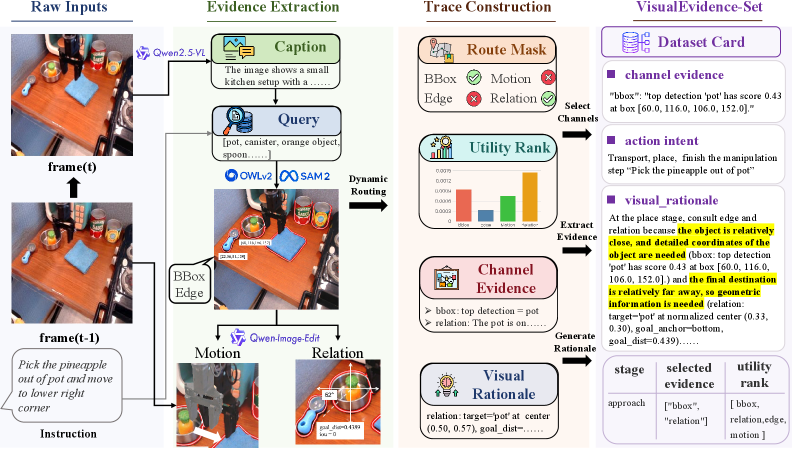
Figure 4 — VisualEvidence-Kit의 워크플로우
⚠️ 알림: 이 리뷰는 AI로 작성되었습니다.
관련 포스트
- [논문리뷰] Kairos: A Native World Model Stack for Physical AI
- [논문리뷰] LLMs4All: A Review on Large Language Models for Research and Applications in Academic Disciplines
- [논문리뷰] xHC: Expanded Hyper-Connections
- [논문리뷰] Xiaomi-Robotics-1: Scaling Vision-Language-Action Models with over 100K Hours of Real-World Trajectories
- [논문리뷰] When Does Muon Help Agentic Reinforcement Learning?
Review 의 다른글
- 이전글 [논문리뷰] VLM3: Vision Language Models Are Native 3D Learners
- 현재글 : [논문리뷰] VisualThink-VLA: Visual Intermediate Reasoning for Effective and Low-Latency Vision-Language-Action Policies
- 다음글 [논문리뷰] When Confidence Misleads: Suffix Anchoring and Anchor-Proximity Confidence Modulation for Diffusion Language Models
댓글