[논문리뷰] VLM3: Vision Language Models Are Native 3D Learners
링크: 논문 PDF로 바로 열기
메타데이터
저자: Zhipeng Cai, Zhuang Liu, Yunyang Xiong, Zechun Liu, Vikas Chandra, Yangyang Shi, et al.
1. Key Terms & Definitions (핵심 용어 및 정의)
- VLM^3^: 본 논문에서 제안하는 표준 VLM 기반의 3D 학습 프레임워크로, 복잡한 설계 없이 3D 이해를 수행하는 모델을 지칭함.
- Focal Length Unification: 입력 이미지의 초점 거리(focal length)를 1000픽셀로 통일하여 카메라 모호성(camera ambiguity) 문제를 해결하고 데이터 혼합 학습을 가능하게 하는 핵심 전처리 기법.
- Text-based Pixel Reference: 시각적 프롬프팅(visual prompting) 대신 픽셀 좌표를 텍스트 공간으로 정규화(normalized to [0, 2000))하여 입력하는 방식.
- Data Mixture & Scaling: 다양한 3D 작업 데이터셋을 데이터 크기에 기반하여 가중치를 부여하고 확장함으로써 모델의 성능을 향상시키는 핵심 학습 전략.
2. Motivation & Problem Statement (연구 배경 및 문제 정의)
본 논문은 표준 VLM이 복잡한 전용 설계 없이도 3D 이해를 수행할 수 있음을 증명하기 위해 수행되었다. 기존의 3D 이해 연구들은 전문가용 비전 모델(expert vision models)에 의존하며, 모델 아키텍처 변경, 복잡한 회귀 손실 함수(regression losses), 무거운 데이터 증강(heavy data augmentations) 등을 필수 요소로 간주해 왔다. 그러나 이러한 복잡성은 범용 모델의 확장성과 유연성을 저해하는 원인이 된다. 저자들은 표준 VLM이 이미 강력한 3D 학습 능력을 내재하고 있음을 입증하며, 기존의 복잡한 task-specific 설계가 사실상 불필요함을 밝히고자 한다 [Figure 1].
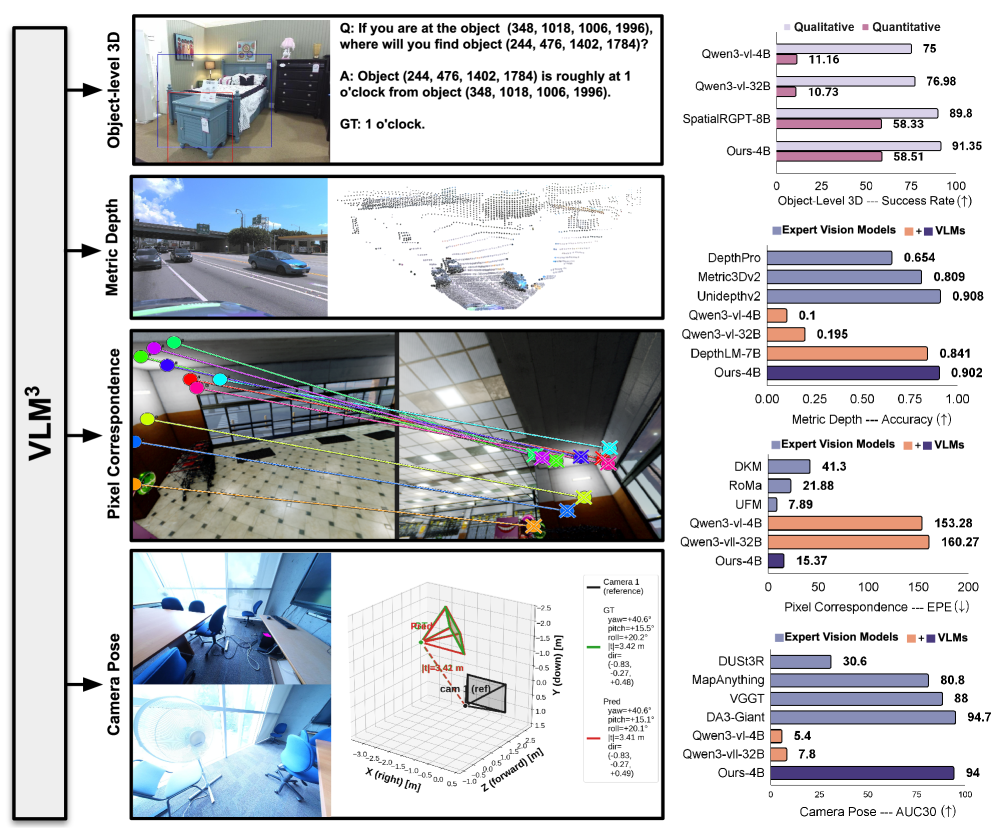
Figure 1 — VLM^3^ 프레임워크 개요
3. Method & Key Results (제안 방법론 및 핵심 결과)
본 연구는 Focal Length Unification, Text-based Pixel Reference, Data Mixture & Scaling의 세 가지 핵심 요소로 구성된 VLM^3^ 프레임워크를 제안한다 [Figure 2]. 이 방법론은 표준 VLM 아키텍처를 유지하면서도 텍스트 기반의 SFT(Supervised Fine-Tuning)만으로 다양한 3D 작업을 수행한다. 실험 결과, **VLM^3^**는 Depth Estimation에서 기존 DepthLM의 정확도를 0.84에서 0.9로 큰 폭으로 향상시켰으며, UnidepthV2 등 전문가 모델과 대등한 성능을 기록하였다 [Table 1, Table 2]. 또한 Camera Pose Estimation 작업에서도 AUC30° 기준 94.0%의 정확도를 달성하여 DA3-Giant와 같은 최상위 전문가 모델과 필적하는 성과를 보였다 [Table 2]. 정량적 지표뿐만 아니라 다양한 시각적 결과물에서도 **VLM^3^**의 범용적인 3D 이해 능력이 입증되었다 [Figure 3].
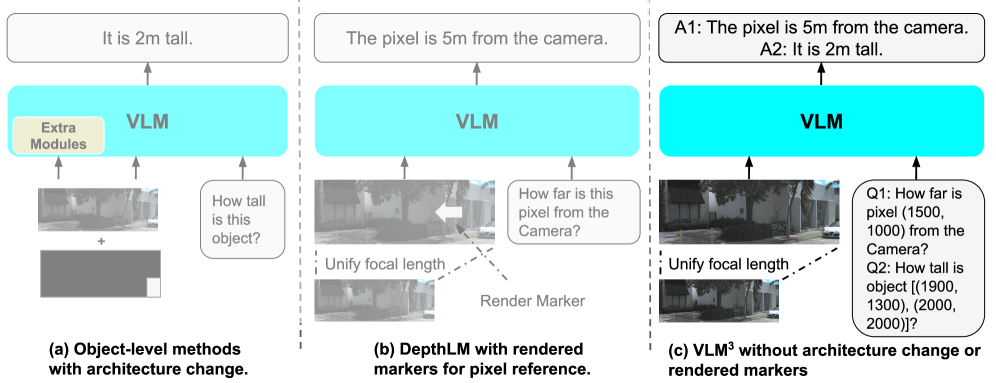
Figure 2 — VLM^3^ 모델 아키텍처

Figure 3 — 다양한 작업에서의 시각화
4. Conclusion & Impact (결론 및 시사점)
본 논문은 표준 VLM이 추가적인 특수 설계 없이도 효율적이고 확장 가능한 3D 학습이 가능한 'native 3D learner'임을 최초로 증명하였다. 이 연구는 기존의 복잡한 3D 비전 모델 설계 패러다임을 단순화함으로써, 범용 3D 파운데이션 모델 개발에 새로운 가능성을 제시한다. **VLM^3^**의 성공은 3D 인지 작업에서 모델의 아키텍처적 복잡성보다 데이터 전략과 학습 방식이 더 핵심적임을 시사하며, 향후 학계 및 산업계에서 보다 가볍고 확장성 있는 모델 설계의 근간이 될 것으로 기대된다.
⚠️ 알림: 이 리뷰는 AI로 작성되었습니다.
관련 포스트
- [논문리뷰] VisualClaw: A Real-Time, Personalized Agent for the Physical World
- [논문리뷰] Geometry-Aware Representation Denoising for Robust Multi-view 3D Reconstruction
- [논문리뷰] TideGS: Scalable Training of Over One Billion 3D Gaussian Splatting Primitives via Out-of-Core Optimization
- [논문리뷰] UniMesh: Unifying 3D Mesh Understanding and Generation
- [논문리뷰] GEBench: Benchmarking Image Generation Models as GUI Environments
Review 의 다른글
- 이전글 [논문리뷰] Trust-Region Behavior Blending for On-Policy Distillation
- 현재글 : [논문리뷰] VLM3: Vision Language Models Are Native 3D Learners
- 다음글 [논문리뷰] VisualThink-VLA: Visual Intermediate Reasoning for Effective and Low-Latency Vision-Language-Action Policies
댓글