[논문리뷰] TideGS: Scalable Training of Over One Billion 3D Gaussian Splatting Primitives via Out-of-Core Optimization
링크: 논문 PDF로 바로 열기
메타데이터
저자: Chonghao Zhong, Linfeng Shi, Hua Chen, Tiecheng Sun, Hao Zhao, Binhang Yuan, Chaojian Li
## 1. Key Terms & Definitions (핵심 용어 및 정의)
- 3DGS (3D Gaussian Splatting): anisotropic Gaussian primitive를 사용하여 고해상도 장면을 표현하고 실시간 렌더링을 지원하는 방식입니다.
- Out-of-Core Optimization: GPU VRAM 용량을 초과하는 대규모 데이터를 SSD와 CPU 캐시를 활용하여 처리하는 메모리 관리 기법입니다.
- Visibility-induced Sparsity: 전체 3DGS 모델 중 특정 시점에서 카메라에 보이는 가우시안 세트만이 렌더링 및 gradient 업데이트에 참여하는 현상을 의미합니다.
- Tide (Trajectory-Adaptive Differential Streaming): 연속적인 카메라 궤적에서 이전 시점의 작업 세트와 중복되는 부분을 재사용하고 incremental delta만 전송하는 스트리밍 최적화 기법입니다.
## 2. Motivation & Problem Statement (연구 배경 및 문제 정의) 본 논문은 billion-scale 3DGS training 시 발생하는 GPU VRAM 한계 문제를 해결하기 위해 TideGS를 제안합니다. 기존의 3DGS는 모델 파라미터가 증가함에 따라 메모리 수요가 선형적으로 증가하여, 24GB GPU 기준 약 1,100만 개의 가우시안으로 규모가 제한됩니다 [Figure 1]. 최신 기법들 또한 파라미터 Offloading을 시도하나, rasterization과 관련된 기하학적 데이터의 residency 요구사항으로 인해 1억 개 수준에서 한계에 직면합니다 [Table 1]. 이러한 메모리 병목 현상을 해소하고 대규모 환경에서 3DGS의 fidelity를 확보하기 위해서는, 고정된 VRAM을 영구적인 파라미터 저장소가 아닌 작업 세트 캐시로 전환하는 Out-of-Core 아키텍처가 필수적입니다 [Figure 2].
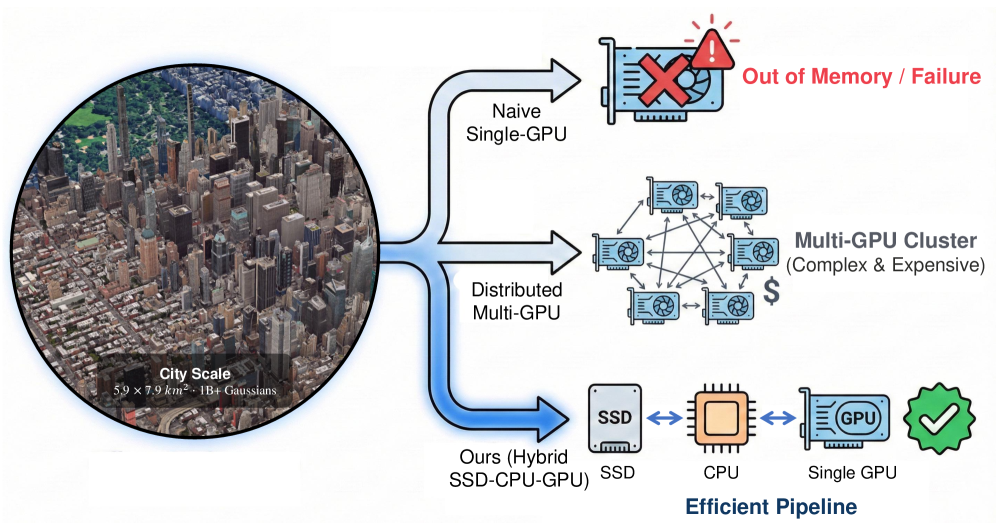
Figure 1 — TideGS의 계층적 VRAM 관리
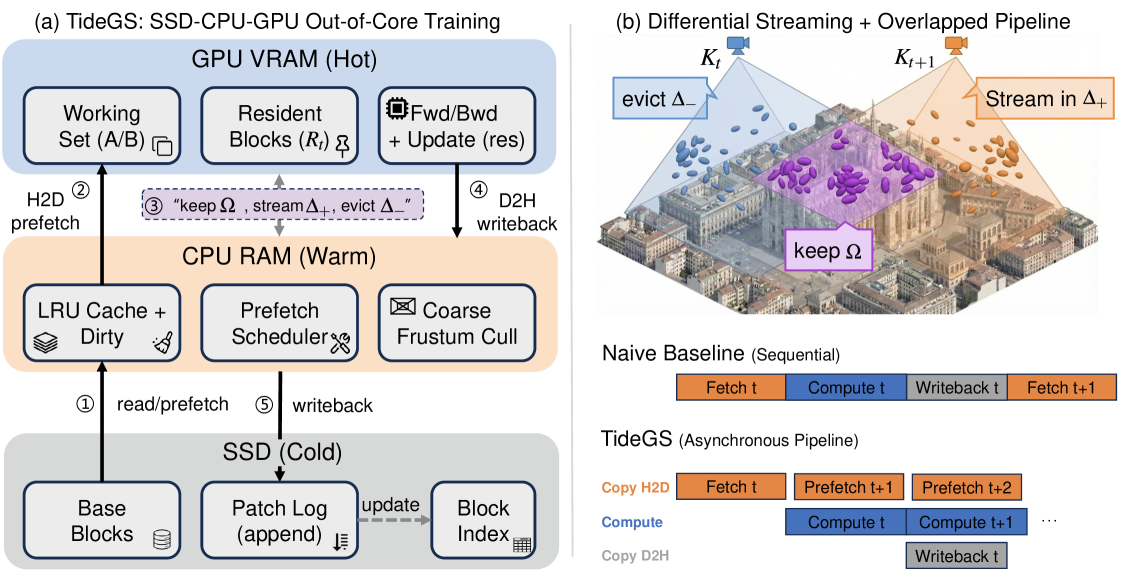
Figure 2 — TideGS 전체 파이프라인
## 3. Method & Key Results (제안 방법론 및 핵심 결과) 저자들은 SSD–CPU–GPU 계층을 활용하는 TideGS 프레임워크를 설계하였습니다. 첫째, Morton sorting을 통해 공간적 인접성을 보장하는 Block-virtualized geometry를 구성하고 CPU에서 frustum culling을 수행하여 필요한 block만 선별합니다 [Figure 3]. 둘째, Hierarchical asynchronous pipeline을 통해 SSD 읽기, CPU-to-GPU 데이터 이동, 그리고 GPU 연산을 중첩(overlap)시켜 I/O 지연을 숨깁니다. 셋째, Tide (Trajectory-Adaptive Differential Streaming) 기법을 통해 이전 시점과의 작업 세트 차이(diff)만을 전송하여 PCIe 대역폭 점유를 최적화합니다 [Figure 2]. 실험 결과, TideGS는 단일 24GB GPU에서 10억 개 이상의 가우시안을 성공적으로 학습시켰으며, 기존 베이스라인 대비 10배 높은 확장성을 달성하였습니다 [Table 4]. 또한, in-memory 설정에서도 15% 미만의 부가적인 오버헤드만을 기록하며 Native 3DGS와 동일한 수준의 reconstruction quality를 유지함을 입증하였습니다 [Table 2, Table 3].
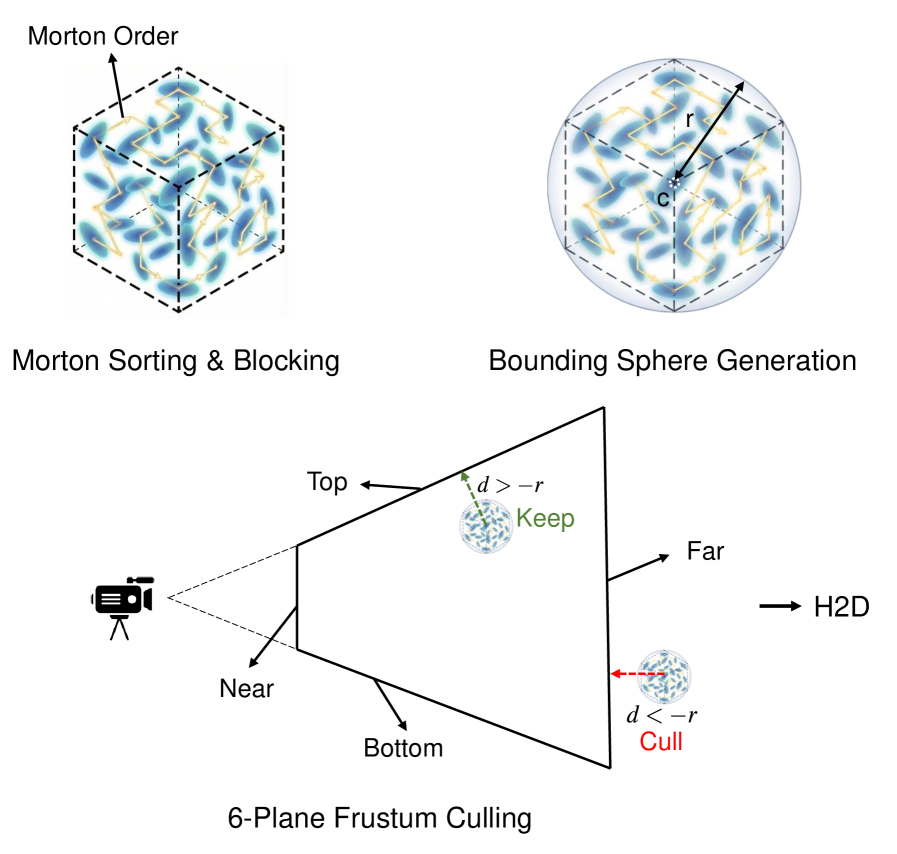
Figure 3 — 블록 가상화 및 가시성 필터링
## 4. Conclusion & Impact (결론 및 시사점) 본 논문은 3DGS의 sparse한 visibility와 trajectory locality를 결합한 Out-of-Core 학습 프레임워크를 통해, 단일 GPU 환경에서의 대규모 학습 한계를 돌파했습니다. TideGS는 billion-scale 3D 모델 학습을 가능케 함으로써, 학계 및 산업계에서 대규모 장면 재구성의 진입 장벽을 대폭 낮추었습니다. 연구 결과는 memory-bound 시스템 아키텍처가 현대 대규모 3D 모델링에서 얼마나 핵심적인 역할을 할 수 있는지를 시사하며, 향후 더욱 정밀하고 방대한 규모의 디지털 트윈 생성을 위한 기반 기술로 활용될 것으로 기대됩니다.
⚠️ 알림: 이 리뷰는 AI로 작성되었습니다.
관련 포스트
- [논문리뷰] AsySplat: Efficient Asymmetric 3D Gaussian Splatting for Long-Sequence Scene Modeling
- [논문리뷰] WildCity: A Real-World City-Scale Testbed for Rendering, Simulation, and Spatial Intelligence
- [논문리뷰] Image2Sim: Scaling Embodied Navigation via Generative Neural Simulator
- [논문리뷰] PixWorld: Unifying 3D Scene Generation and Reconstruction in Pixel Space
- [논문리뷰] Monte Carlo Energy Aggregation for Mobile 3D Gaussian Splatting
Review 의 다른글
- 이전글 [논문리뷰] Semantic Generative Tuning for Unified Multimodal Models
- 현재글 : [논문리뷰] TideGS: Scalable Training of Over One Billion 3D Gaussian Splatting Primitives via Out-of-Core Optimization
- 다음글 [논문리뷰] Video Models Can Reason with Verifiable Rewards
댓글