[논문리뷰] dMoE: dLLMs with Learnable Block Experts
링크: 논문 PDF로 바로 열기
메타데이터
저자: Sicheng Feng, Zigeng Chen, Gongfan Fang, Xinyin Ma, Xinchao Wang
1. Key Terms & Definitions (핵심 용어 및 정의)
- dLLM (Diffusion Large Language Models): 기존 autoregressive 모델과 달리 확산 과정을 통해 텍스트를 생성하며, 토큰 단위의 병렬적 정제(parallel refinement)를 지원하는 모델 아키텍처입니다.
- MoE (Mixture-of-Experts): 전체 모델 파라미터는 거대하지만, 입력 데이터에 대해 활성화되는 파라미터는 일부분으로 제한하여 모델 용량을 확장하고 효율성을 높이는 sparse 아키텍처입니다.
- Unique Activated Experts: 단일 forward pass(블록) 내에서 활성화되는 고유한 전문가의 총 개수로, 이 수치가 높을수록 메모리 로드 및 inference latency가 급격히 증가합니다.
- Block Diffusion Decoding: 여러 토큰을 하나의 블록으로 묶어 동시에 denoising 하는 디코딩 방식으로, dLLM에서 주로 사용되는 효율적인 생성 기법입니다.
- Top-P Criterion (Block-level): Aggregate 된 블록 수준의 전문가 점수를 기반으로 cumulative probability threshold를 적용하여 최적의 전문가 coreset을 선별하는 동적 라우팅 기법입니다.
2. Motivation & Problem Statement (연구 배경 및 문제 정의)
본 논문은 MoE 기반 dLLM에서 블록 병렬 디코딩(block parallel decoding) 시 발생하는 과도한 전문가 활성화 문제를 해결하여 inference 효율성을 높이는 것을 목적으로 합니다. 기존의 MoE 아키텍처는 토큰 단위로 전문가를 선택하는데, dLLM은 단일 forward pass에서 여러 토큰을 동시에 처리하므로 결과적으로 매우 많은 수의 고유한 전문가가 활성화되어 메모리 병목 현상을 유발합니다 [Figure 2]. 이러한 메모리 병목은 모델의 end-to-end latency를 결정짓는 핵심 요인이 되며, 기존의 전문가 pruning이나 단순한 선택 방식으로는 성능 저하 없이 이 문제를 해결하기 어렵습니다. 따라서 본 연구는 성능 손실을 최소화하면서도 고유하게 활성화되는 전문가 수를 공격적으로 줄일 수 있는 새로운 라우팅 프레임워크를 제안합니다.
3. Method & Key Results (제안 방법론 및 핵심 결과)
본 논문은 토큰 단위의 전문가 점수를 집계(aggregation)하여 블록 수준의 전문가 점수를 생성하고, 이를 통해 효율적인 전문가 coreset을 결정하는 dMoE를 제안합니다 [Figure 4]. 우선 각 토큰의 라우팅 점수를 더하여 block-level expert scores를 산출하며, 저자들은 이 점수가 전문가의 중요도를 효과적으로 반영함을 확인하였습니다 [Figure 3]. 이후 제안된 top-p criterion을 통해 동적으로 고유 전문가 활성화를 제한함으로써 denoising 단계나 블록별 특성에 유연하게 대응합니다 [Figure 4]. 실험 결과, dMoE는 LLaDA2.0-mini 모델에서 고유 활성화 전문가 수를 평균 69.5개에서 14.6개로 약 79% 감소시켰으며, 기존 성능의 99.11%를 유지하는 성과를 보였습니다 [Table 2]. 또한 메모리 사용량을 최대 79.84% 절감하였고, 1.14×에서 1.66×의 end-to-end latency speedup을 달성하여 실질적인 추론 속도 개선을 입증하였습니다 [Figure 5].
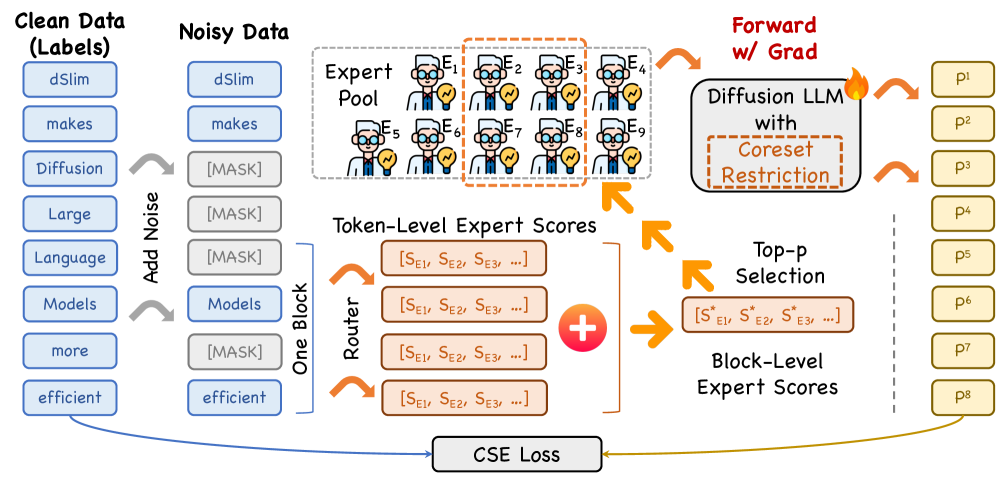
Figure 4 — dMoE의 전체 아키텍처
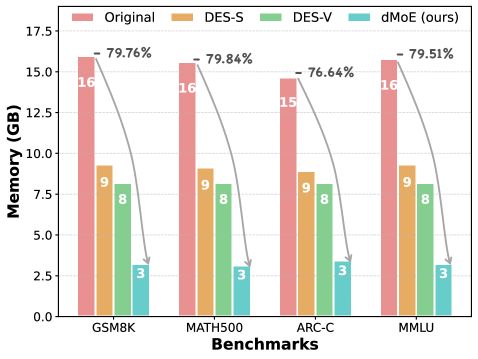
Figure 5 — 메모리 및 latency 비교
4. Conclusion & Impact (결론 및 시사점)
본 연구는 MoE dLLM에서 블록 수준의 전문가 라우팅 전략인 dMoE를 통해 메모리 집약적인 추론 문제를 효과적으로 해결하였습니다. 실험을 통해 성능 저하 없는 공격적인 전문가 압축이 가능함을 증명하였으며, 이는 대규모 모델을 자원 제한적인 환경에 배포하는 데 큰 기여를 합니다. 이 연구는 dLLM 분야에서 효율적인 모델 설계의 기반을 마련하였으며, 향후 다양한 모달리티와 확장된 아키텍처로의 적용 가능성을 제시합니다.
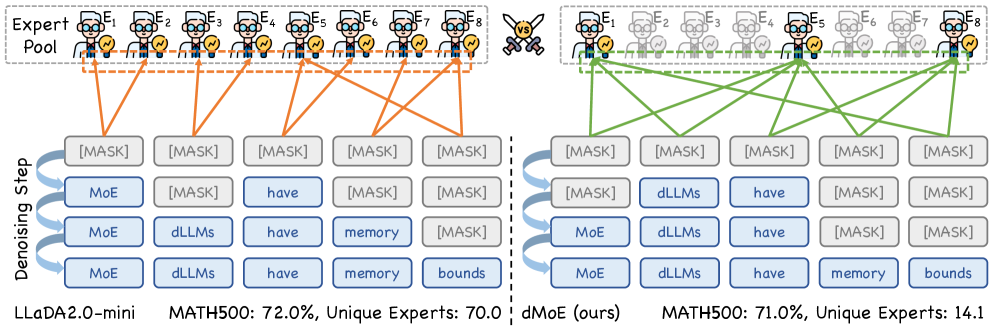
Figure 1 — 기존 MoE와 dMoE 비교
⚠️ 알림: 이 리뷰는 AI로 작성되었습니다.
관련 포스트
- [논문리뷰] LoPA: Scaling dLLM Inference via Lookahead Parallel Decoding
- [논문리뷰] Loop the Loopies!
- [논문리뷰] A Sovereign, Open-Source Foundation Model for German and English
- [논문리뷰] Scaling Mixture-of-Experts Video Pretraining for Embodied Intelligence
- [논문리뷰] Nemotron-Labs-Diffusion: A Tri-Mode Language Model Unifying Autoregressive, Diffusion, and Self-Speculation Decoding
Review 의 다른글
- 이전글 [논문리뷰] When Confidence Misleads: Suffix Anchoring and Anchor-Proximity Confidence Modulation for Diffusion Language Models
- 현재글 : [논문리뷰] dMoE: dLLMs with Learnable Block Experts
- 다음글 [논문리뷰] iVGR: Internalizing Visually Grounded Reasoning for MLLMs with Reinforcement Learning
댓글