[논문리뷰] iVGR: Internalizing Visually Grounded Reasoning for MLLMs with Reinforcement Learning
링크: 논문 PDF로 바로 열기
메타데이터
저자: Chang-Bin Zhang, Yujie Zhong, Qiang Zhang, Kai Han
1. Key Terms & Definitions (핵심 용어 및 정의)
- Visually Grounded CoT: 추론 과정 중에 바운딩 박스(Bounding Box)와 같은 명시적인 시각적 위치 정보를 생성하여 모델의 추론을 고정(anchor)시키는 방식입니다.
- Textual CoT: 외부 위치 정보 없이 오직 자연어 추론만을 통해 답변을 도출하는 방식으로, 본 연구에서는 시각적 정보 처리 능력이 내재화된 형태를 지향합니다.
- Consistency Reward: Grounded stream에서 얻은 고품질의 시각적 추론 결과를 기반으로, Textual stream이 동일한 시각적 사실을 기술하도록 유도하여 지식을 전이하는 강화학습 보상 함수입니다.
- Dual-Stream Training: Grounded stream과 Textual stream을 동시에 학습시켜, 명시적 좌표 생성 없이도 시각적 정밀도가 높은 추론을 수행하게 하는 프레임워크입니다.
- Tool-Assisted Test-Time Scaling: 모델이 예측한 바운딩 박스를 활용해 외부 크롭(crop) 도구를 호출하고, 이를 통해 얻은 지역적 시각 정보를 다시 추론에 통합하여 성능을 극대화하는 추론 전략입니다.
2. Motivation & Problem Statement (연구 배경 및 문제 정의)
본 논문은 MLLM의 fine-grained perception을 향상하기 위해 도입된 Visually Grounded CoT가 오히려 추론 단계에서 성능 저하를 일으킬 수 있다는 문제점을 지적합니다. [Figure 1] 기존의 명시적 grounding 방식은 모델이 좌표를 생성하는 데 리소스를 낭비하게 하며, 부정확한 좌표 생성은 시각적 노이즈를 유발하여 최종 답변 정확도에 악영향을 미칩니다. [Figure 2] 연구자들은 추론 과정에서 명시적인 좌표 출력 없이도 시각적 위치 파악 능력이 Textual CoT에 내재화될 수 있음을 발견했습니다. 따라서 저자들은 명시적 grounding의 개입 없이도 정밀한 추론을 수행하는 새로운 프레임워크인 iVGR을 제안합니다.
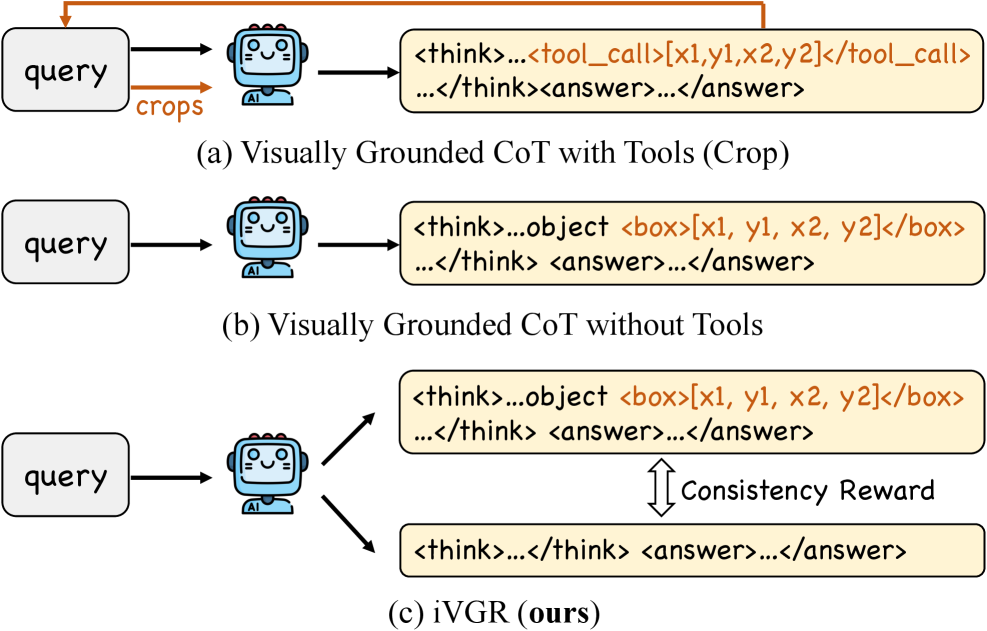
Figure 1 — 시각적 추론 패러다임 비교
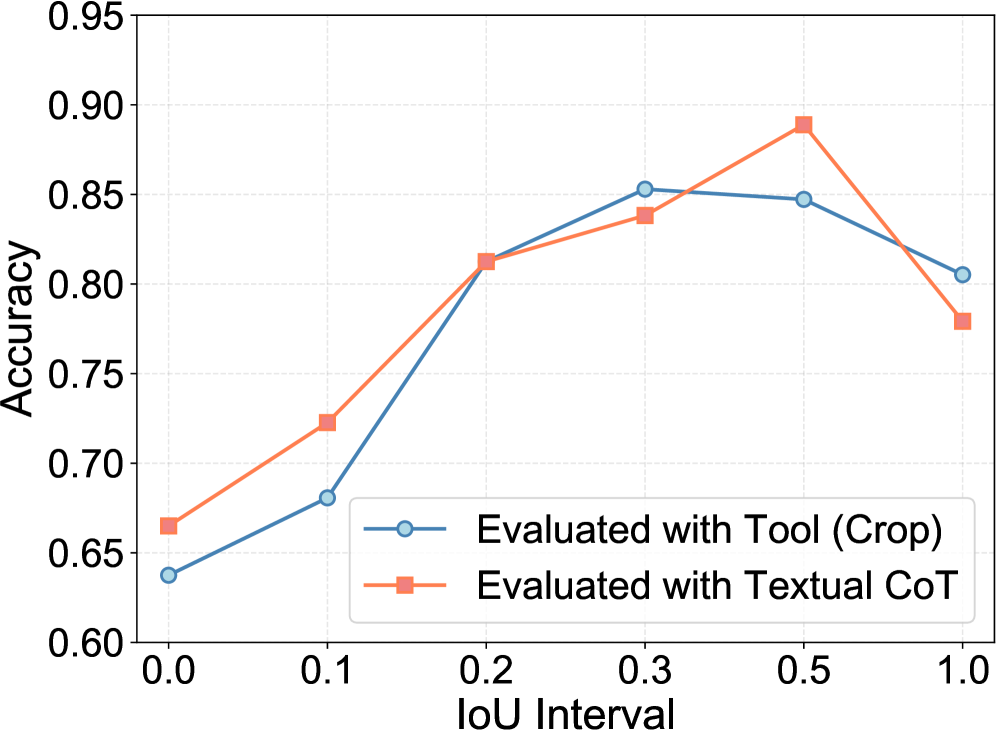
Figure 2 — 정확도와 localization 품질 관계
3. Method & Key Results (제안 방법론 및 핵심 결과)
iVGR은 강화학습 기반의 Dual-Stream Training을 통해 시각적 위치 파악 능력을 텍스트 추론 과정으로 전이합니다. [Figure 3] 모델은 Grounded stream과 Textual stream을 동시에 학습하며, 이때 Consistency Reward를 도입하여 Grounded stream의 고품질 추론 궤적을 Textual stream이 모방하도록 유도합니다. 이 과정에서 Rollout Archive를 유지하여 학습 중 최상의 시각적 지침을 제공함으로써 모델의 학습 안정성을 확보했습니다. 실험 결과, iVGR은 Qwen2.5-VL-7B 및 Qwen3-VL 모델에서 기존 baseline 대비 유의미한 성능 향상을 보였습니다. 특히 fine-grained VQA 지표인 V* 벤치마크에서 기존 대비 2.6% 향상된 성능을 기록했으며, [Table 2] Tool-Assisted Test-Time Scaling을 적용할 경우 HR4K와 같은 고해상도 지표에서 추가적인 성능 이득을 확보할 수 있음을 입증했습니다. [Table 4]
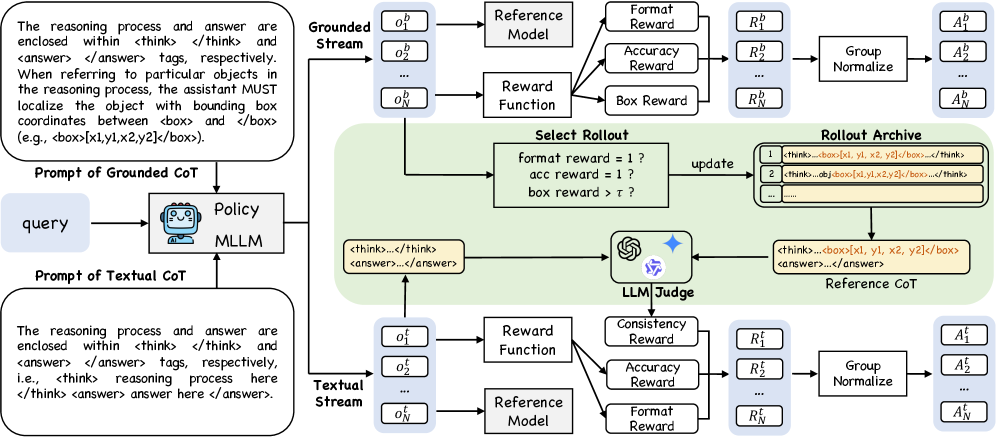
Figure 3 — iVGR 제안 방법론 아키텍처
4. Conclusion & Impact (결론 및 시사점)
본 연구는 Visually Grounded Reasoning 능력이 명시적인 좌표 출력 없이도 텍스트 추론 과정에 성공적으로 내재화될 수 있음을 증명했습니다. iVGR은 강화학습을 통해 복잡한 시각적 추론을 효율적으로 최적화하며, 필요시 도구와 연동하여 추론 성능을 확장할 수 있는 유연성을 제공합니다. 이 프레임워크는 MLLM이 시각적 정밀도를 유지하면서도 자연스러운 사고 과정을 수행하도록 만들어, 향후 고해상도 이미지 처리 및 정밀 추론이 필요한 산업계 및 학계 분야에서 큰 기여를 할 것으로 기대됩니다.
⚠️ 알림: 이 리뷰는 AI로 작성되었습니다.
관련 포스트
- [논문리뷰] Faithful GRPO: Improving Visual Spatial Reasoning in Multimodal Language Models via Constrained Policy Optimization
- [논문리뷰] Think Longer to Explore Deeper: Learn to Explore In-Context via Length-Incentivized Reinforcement Learning
- [논문리뷰] Video-Thinker: Sparking 'Thinking with Videos' via Reinforcement Learning
- [논문리뷰] EconProver: Towards More Economical Test-Time Scaling for Automated Theorem Proving
- [논문리뷰] MentalThink: Shaping Thoughts in Mental SVG World
Review 의 다른글
- 이전글 [논문리뷰] dMoE: dLLMs with Learnable Block Experts
- 현재글 : [논문리뷰] iVGR: Internalizing Visually Grounded Reasoning for MLLMs with Reinforcement Learning
- 다음글 [논문리뷰] 3DCodeBench: Benchmarking Agentic Procedural 3D Modeling Via Code
댓글