[논문리뷰] 3DCodeBench: Benchmarking Agentic Procedural 3D Modeling Via Code
링크: 논문 PDF로 바로 열기
메타데이터
저자: Yipeng Gao, Lei Shu, Genzhi Ye, Xi Xiong, Ameesh Makadia, Meiqi Guo, Laurent Itti, Jindong Chen
1. Key Terms & Definitions (핵심 용어 및 정의)
- Procedural 3D Modeling: 미리 정의된 수동 메쉬 생성이 아닌, 코드를 통해 3D 기하학적 구조와 매개변수를 동적으로 생성하는 방식입니다.
- 3DCodeBench: 212개의 카테고리와 26K개의 데이터셋으로 구성된 VLM 기반의 Procedural 3D 모델링 생성 성능 평가용 벤치마크 프레임워크입니다.
- 3DCodeArena: 생성된 3D 결과물에 대한 Pairwise Human Preference를 수집하여 모델의 품질을 Elo Rating으로 측정하는 플랫폼입니다.
- Agentic Refinement: 모델이 단일 생성(Single-shot)에 그치지 않고, 실행 오류 로그나 Visual Self-Critique를 통해 코드를 반복 수정하며 최종 산출물을 완성하는 과정입니다.
2. Motivation & Problem Statement (연구 배경 및 문제 정의)
본 논문은 현대 3D 생성 분야에서 Procedural Code 생성을 통한 모델링의 중요성이 커지고 있으나, 이를 객관적으로 평가할 수 있는 표준화된 벤치마크가 부재하다는 문제점을 해결하고자 합니다 [Figure 1]. 기존 연구들은 데이터셋의 부족, 3D 모델의 기하학적 복잡도 결여, 반복적인 설계 과정을 반영하지 못한 단회성 평가 방식에 국한되어 있었습니다. 특히, 현재의 VLM들은 복잡한 API 구문을 다루거나 물리적으로 타당한 구조를 생성하는 데 어려움을 겪고 있습니다. 저자들은 이러한 한계를 극복하기 위해 에이전트 기반의 데이터 구축 파이프라인과 다단계 평가 체계를 제안합니다.
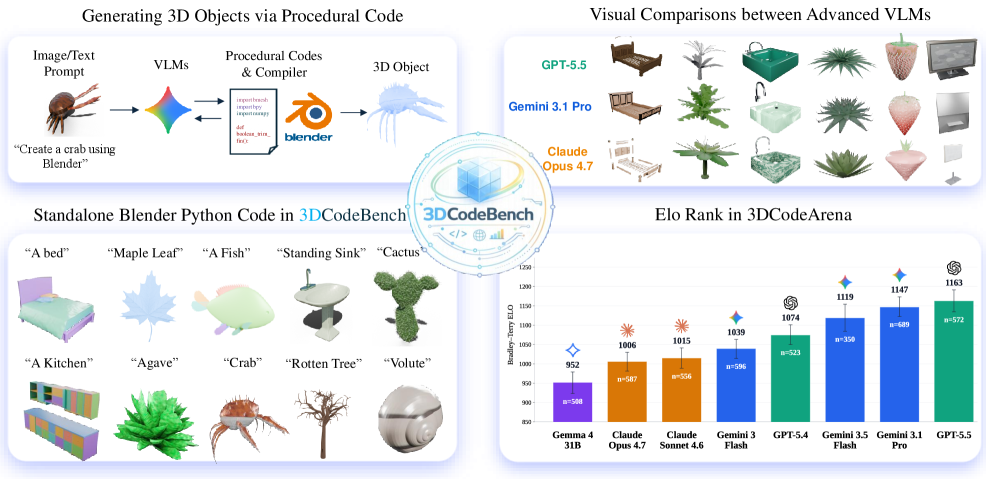
Figure 1 — 3DCodeBench 아키텍처 개요
3. Method & Key Results (제안 방법론 및 핵심 결과)
저자들은 Infinigen 기반의 3D 모델링 워크플로우를 VLM이 수행하도록 하는 자동화된 데이터 큐레이션 파이프라인을 구축하였습니다 [Figure 2]. 해당 파이프라인은 Skill Library와 Experience Library를 활용하여 API 오류를 수정하고 시각적 품질을 반복적으로 개선합니다. 12개의 최신 VLM을 평가한 결과, SigLIP-2 및 DINOv3 지표가 인간의 선호도와 가장 높은 상관관계를 보였으며, 이는 자동화된 평가의 타당성을 입증합니다 [Figure 4]. 실험적으로 Multi-turn Refinement를 도입했을 때 전체 모델의 Executability가 단일 생성 대비 평균 27.2%p 향상되는 등 성능 우위를 확인하였습니다 [Table 1]. 또한, 추론 과정에서의 Thinking Budget 증가는 경량화된 모델에서 특히 효과적이며, 전반적인 성능 개선의 핵심 동력이 됨을 증명하였습니다.
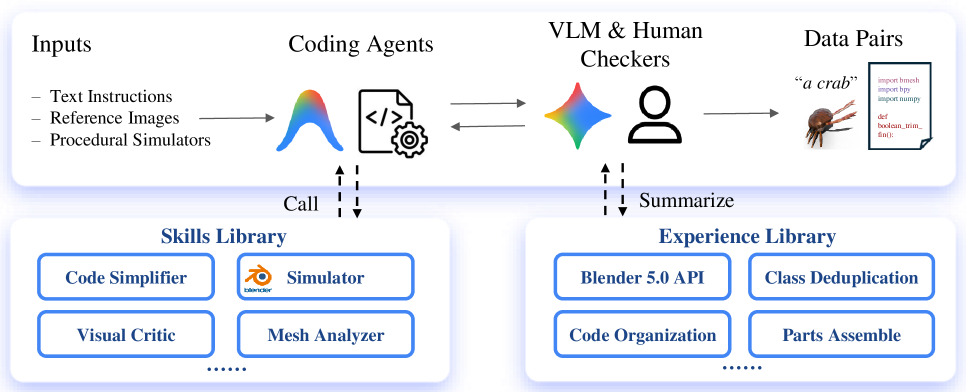
Figure 2 — 에이전트 데이터 큐레이션 파이프라인
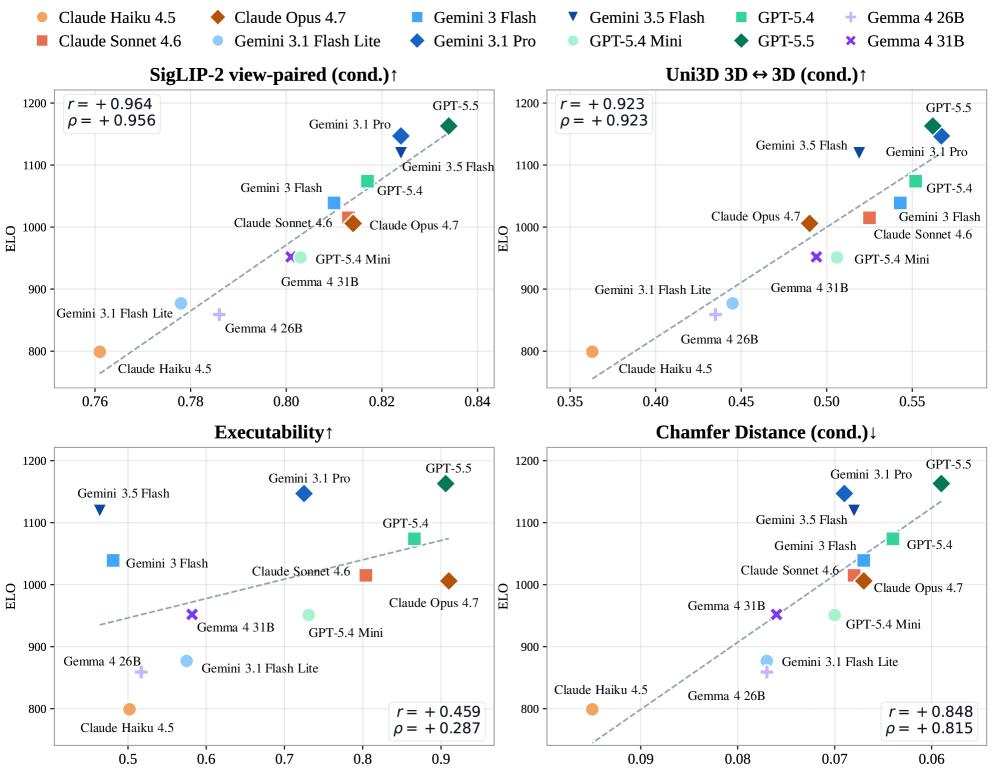
Figure 4 — 자동 지표와 인간 선호도 상관관계
4. Conclusion & Impact (결론 및 시사점)
본 연구는 3D 모델링 분야에서 VLM이 Procedural Code를 작성하는 능력을 체계적으로 측정한 최초의 대규모 벤치마크인 3DCodeBench를 제시합니다. 연구 결과, 코드 실행 가능성(Executability)은 에이전트 기반의 반복적 수정을 통해 높은 수준으로 도달할 수 있으나, 구조적 결함이나 물리적 타당성 문제는 여전히 해결해야 할 과제로 남아있습니다. 이 벤치마크와 3DCodeArena 플랫폼은 향후 고품질 3D 콘텐츠를 자율적으로 생성하는 에이전트 모델의 발전 방향을 제시하며, 3D 생성 및 디자인 자동화 연구에 중요한 토대를 제공할 것입니다.
⚠️ 알림: 이 리뷰는 AI로 작성되었습니다.
관련 포스트
- [논문리뷰] DataComp-VLM: Improved Open Datasets for Vision-Language Models
- [논문리뷰] AnyGroundBench: A Specialized-Domain Benchmark for Video Grounding in Vision-Language Models
- [논문리뷰] PaintBench: Deterministic Evaluation of Precise Visual Editing
- [논문리뷰] RoboStressBench: Benchmarking VLM Robustness to Physical Visual Stress in Embodied Scenes
- [논문리뷰] π-Bench: Evaluating Proactive Personal Assistant Agents in Long-Horizon Workflows
Review 의 다른글
- 이전글 [논문리뷰] iVGR: Internalizing Visually Grounded Reasoning for MLLMs with Reinforcement Learning
- 현재글 : [논문리뷰] 3DCodeBench: Benchmarking Agentic Procedural 3D Modeling Via Code
- 다음글 [논문리뷰] A Matter of TASTE: Improving Coverage and Difficulty of Agent Benchmarks
댓글