[논문리뷰] A Matter of TASTE: Improving Coverage and Difficulty of Agent Benchmarks
링크: 논문 PDF로 바로 열기
메타데이터
저자: Tomer Keren, Nitay Calderon, Asaf Yehudai, Yotam Perlitz, Michal Shmueli-Scheuer, Roi Reichert
1. Key Terms & Definitions (핵심 용어 및 정의)
- TASTE: Tool Sequence Evolution을 기반으로 하여, 자동화된 방식으로 도전적이고 높은 Coverage를 가진 벤치마크 태스크를 생성하는 프레임워크입니다.
- $\tau^c$-Bench: TASTE를 사용하여 기존 벤치마크인 $\tau^2$-Bench의 세 가지 도메인(Airline, Retail, Telecom)을 확장하여 생성한, 더욱 어렵고 Coverage가 넓은 새로운 벤치마크 데이터셋입니다.
- Validity, Difficulty, Coverage: 툴 사용 에이전트 벤치마크가 갖추어야 할 3대 필수 요건으로, 각각 태스크의 자동 검증 가능성, 에이전트 간 변별력, 그리고 툴 사용 패턴의 다양성을 의미합니다.
- Weighted Edit Distance (WED): 도구 간의 의미적/기능적 유사성을 반영한 편집 거리로, 벤치마크 태스크 간의 구조적 차이를 정량화하기 위해 클러스터링에 활용됩니다.
2. Motivation & Problem Statement (연구 배경 및 문제 정의)
본 논문은 기존의 툴 사용 에이전트 벤치마크가 고정된 시나리오에 의존함에 따라 발생하는 심각한 포화(Saturation) 현상과 벤치마크 구축의 높은 노동 집약적 비용 문제를 해결하고자 합니다. 기존 벤치마크는 저자가 수동으로 작성한 좁은 범위의 시나리오만을 포함하기 때문에, 에이전트의 실질적인 태스크 해결 능력보다는 벤치마크 데이터에 대한 과적합을 유도할 위험이 있습니다. [Figure 1]은 TASTE가 이러한 태스크 생성 과정을 역전시켜, 툴 시퀀스를 직접 샘플링하고 구조화함으로써 보다 넓은 범위의 도구 조합을 다룰 수 있게 함을 보여줍니다. 결과적으로, 기존 벤치마크에서 거의 완벽한 성능을 보이는 모델들이 새로운 환경에서는 급격한 성능 저하를 겪는다는 점을 통해, 기존 평가 지표가 에이전트의 강건한 해결 능력을 측정하지 못하고 있음을 문제로 정의합니다.
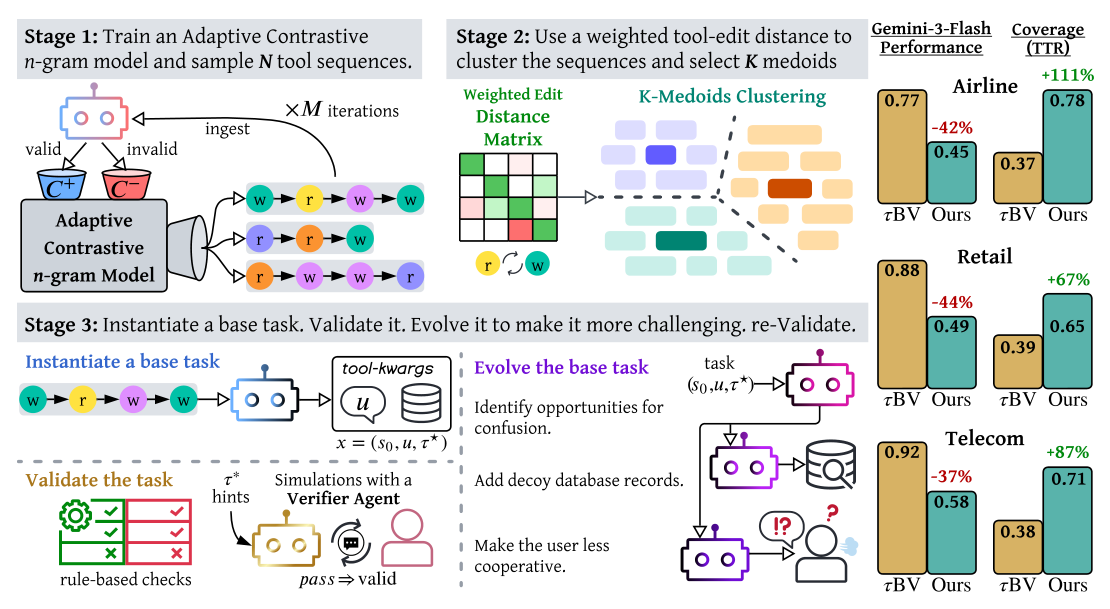
Figure 1 — TASTE의 3단계 파이프라인과 벤치마크 생성 과정을 보여주는 핵심 아키텍처 다이어그램
3. Method & Key Results (제안 방법론 및 핵심 결과)
본 연구는 도구 시퀀스의 직접 샘플링과 진화적 태스크 생성을 결합한 TASTE 파이프라인을 제안합니다. 이 방법론은 Adaptive Contrastive n-gram model을 통해 타당한 도구 시퀀스를 생성하고, K-medoids clustering과 Weighted Edit Distance를 사용하여 데이터의 다양성과 Coverage를 확보하며, 마지막으로 LLM을 통한 단계적 난이도 진화(Difficulty Evolution)를 통해 도전적인 태스크를 완성합니다. [Table 1]에 따르면, Gemini-3-Flash 모델의 경우 기존 $\tau^2$-Bench에서는 0.82-0.94의 높은 성능을 보였으나, 새롭게 생성된 $\tau^c$-Bench에서는 0.28-0.61로 성능이 급격히 저하되었습니다. 또한, 제안된 태스크는 고유 도구 조합(Unique tool combinations)의 수를 2배 이상 증가시켰으며, Type-Token Ratio(TTR)를 최대 111% 향상시켜 기존 벤치마크보다 훨씬 광범위하고 다양한 도구 활용 패턴을 평가할 수 있음을 입증하였습니다. [Figure 1]에서 볼 수 있듯, 모든 도메인에서 모델의 수행 성능은 기존 벤치마크(rBV) 대비 유의미하게 하락하여 태스크의 난이도가 성공적으로 높아졌음을 시사합니다.
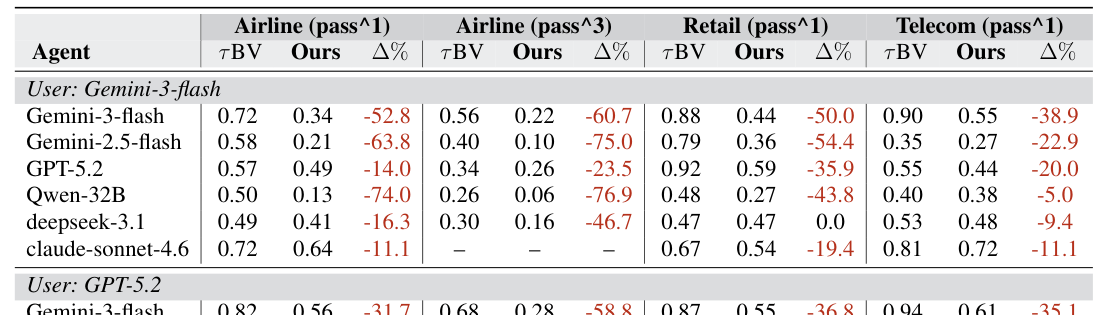
Table 1 — 기존 벤치마크 대비 모델들의 성능 하락을 보여주는 핵심 실험 결과 테이블
4. Conclusion & Impact (결론 및 시사점)
본 논문은 TASTE를 통해 자동화된 방식으로 난이도가 높고 Coverage가 넓은 툴 사용 에이전트 벤치마크 생성이 가능함을 보였습니다. 이는 향후 에이전트 평가가 수동 작성에 의존하지 않고 지속적으로 확장 가능한 방향으로 나아갈 수 있는 기반을 마련합니다. 본 연구 결과는 현재 최첨단 LLM 모델들조차 포화된 벤치마크 점수로 인해 실제 역량이 과대평가되고 있음을 시사하며, 더욱 강건한 에이전트 개발과 평가를 위한 새로운 방법론적 기준을 제시했다는 점에서 중요한 학계 및 산업적 가치를 지닙니다.
⚠️ 알림: 이 리뷰는 AI로 작성되었습니다.
관련 포스트
- [논문리뷰] FORT-Searcher: Synthesizing Shortcut-Resistant Search Tasks for Training Deep Search Agents
- [논문리뷰] Evoflux: Inference-Time Evolution of Executable Tool Workflows for Compact Agents
- [논문리뷰] Agent libOS: A Library-OS-Inspired Runtime for Long-Running, Capability-Controlled LLM Agents
- [논문리뷰] MineExplorer: Evaluating Open-World Exploration of MLLM Agents in Minecraft
- [논문리뷰] GTA-2: Benchmarking General Tool Agents from Atomic Tool-Use to Open-Ended Workflows
Review 의 다른글
- 이전글 [논문리뷰] 3DCodeBench: Benchmarking Agentic Procedural 3D Modeling Via Code
- 현재글 : [논문리뷰] A Matter of TASTE: Improving Coverage and Difficulty of Agent Benchmarks
- 다음글 [논문리뷰] ACL-Verbatim: hallucination-free question answering for research
댓글