[논문리뷰] ACL-Verbatim: hallucination-free question answering for research
링크: 논문 PDF로 바로 열기
메타데이터
저자: Gábor Recski, Szilveszter Tóth, Nadia Verdha, István Boros, Ádám Kovács
1. Key Terms & Definitions (핵심 용어 및 정의)
- VerbatimRAG: 생성적(Generative) 답변 대신 원본 문서의 텍스트 span을 그대로 추출하여 제공함으로써 환각(Hallucination)을 원천 차단하는 Extractive Question Answering 프레임워크입니다.
- Silver Supervision: 사람의 수동 라벨링 비용을 줄이기 위해, 강력한 LLM(Teacher)을 사용하여 자동으로 생성하고 정제한 데이터셋으로 모델을 학습시키는 기법입니다.
- ModernBERT: 긴 문맥 처리에 최적화된 최신 Encoder 모델로, 본 논문에서는 8,192 토큰의 컨텍스트를 처리하며 정보 추출(Extraction) 태스크의 백본으로 활용됩니다.
- Word-level F1: 추출된 텍스트 span이 정답과 얼마나 일치하는지를 단어 단위로 정밀하게 평가하는 핵심 지표입니다.
2. Motivation & Problem Statement (연구 배경 및 문제 정의)
본 논문은 현대적인 Retrieval-Augmented Generation (RAG) 시스템이 근본적으로 지니고 있는 환각(Hallucination) 및 답변의 불투명성 문제를 해결하고자 합니다. 기존 LLM 기반 RAG는 문서를 참조하더라도 모델 내부 지식과 혼합되어 부정확하거나 무의미한 답변을 생성할 위험이 큽니다. 특히 학술 연구 분야처럼 정확한 근거 확인이 필수적인 도메인에서 이러한 특성은 신뢰성을 크게 저해합니다. 저자들은 기존의 추상적 답변 생성 방식을 지양하고, 신뢰 가능한 VerbatimRAG 접근법을 도입하여 연구 논문에서 정보를 정확하게 추출하는 시스템을 구현하고자 합니다 [Figure 2].
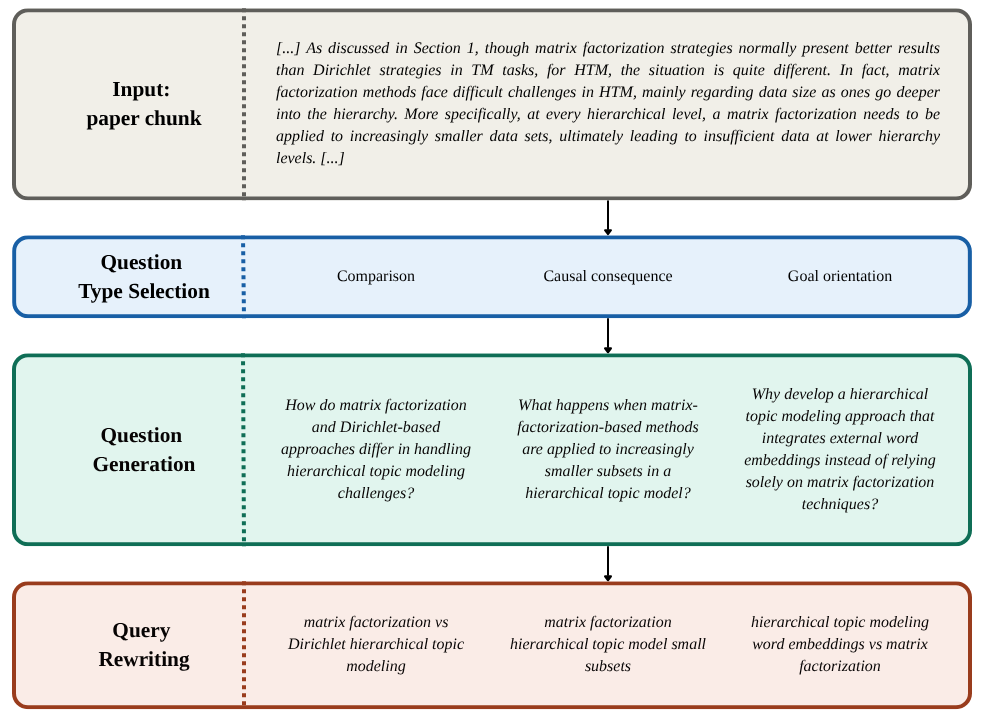
Figure 2 — 합성 질문 생성 파이프라인
3. Method & Key Results (제안 방법론 및 핵심 결과)
본 연구는 ACL Anthology에 포함된 10만 건 이상의 연구 논문을 Docling으로 전처리하고, 이를 인덱싱하여 질문에 대한 핵심 텍스트 span을 직접 추출하는 파이프라인을 제안합니다 [Figure 1]. 저자들은 ScIRGen 방법론을 확장하여 합성 질문을 생성하고, 이를 통해 확보한 Silver Supervision으로 ModernBERT 기반의 효율적인 학생 모델(150M 파라미터)을 파인튜닝하였습니다. 실험 결과, 제안된 acl-verbatim-modernbert 모델은 53.63%의 Word-level F1을 기록하며, 훨씬 큰 규모의 LLM 모델들(GLM-5 등)과 기존의 하이라이팅 베이스라인(Zilliz, Provence)을 유의미한 차이로 압도하였습니다 [Table 1]. 특히, 본 모델은 관련 없는 청크에 대해 추출을 억제하는 정밀도(Precision) 측면에서 탁월한 성능을 보였습니다.

Figure 1 — PDF의 마크다운 변환 예시
4. Conclusion & Impact (결론 및 시사점)
본 논문은 연구 논문과 같은 전문적인 지식 도메인에서 VerbatimRAG를 성공적으로 적용하여 환각 없는 정보 추출 시스템을 구현하였습니다. 연구 결과, 작고 특화된 인코더 아키텍처가 대규모 언어 모델보다 효율적이고 정교하게 정보를 추출할 수 있음을 입증하였습니다. 이 연구는 신뢰성이 중요한 법률, 의학, 학술 검색 시스템 구축을 위한 실용적인 청사진을 제시하며, 향후 더 넓은 도메인으로의 확장 가능성을 열어주었습니다.
⚠️ 알림: 이 리뷰는 AI로 작성되었습니다.
관련 포스트
- [논문리뷰] VaseMuseum: Digital Intelligent Museum for Ancient Greek Pottery
- [논문리뷰] Light-Omni: Reflex over Reasoning in Agentic Video Understanding with Long-Term Memory
- [논문리뷰] Bibby AI: An Editor-Native Agentic Platform for Academic Research, Writing, and Publishing
- [논문리뷰] The Hitchhiker's Guide to Agentic AI: From Foundations to Systems
- [논문리뷰] RL-Index: Reinforcement Learning for Retrieval Index Reasoning
Review 의 다른글
- 이전글 [논문리뷰] A Matter of TASTE: Improving Coverage and Difficulty of Agent Benchmarks
- 현재글 : [논문리뷰] ACL-Verbatim: hallucination-free question answering for research
- 다음글 [논문리뷰] Adapting Multilingual Embedding Models to Turkish via Cross-Lingual Tokenizer Surgery and Offline Distillation
댓글