[논문리뷰] ESPO: Early-Stopping Proximal Policy Optimization
링크: 논문 PDF로 바로 열기
메타데이터
저자: Zihang Li, Rui Zhou, Yingcheng Shi, Wenhan Yu, Zhewen Tan, Zixiang Liu, Zeming Li, Binhua Li, Yongbin Li, Tong Yang, Jieping Ye
1. Key Terms & Definitions (핵심 용어 및 정의)
- Rollout Continuation Problem: 모델이 추론 과정 중 초기 단계에서 잘못된 결정을 내렸음에도 불구하고, 고정된 horizon까지 불필요한 토큰을 계속 생성하여 연산 자원을 낭비하고 학습 노이즈를 유발하는 현상.
- Surrogate Regret: 모델의
Logit분포를 활용하여 현재 sampled 토큰이 최적(greedy) 액션에서 얼마나 벗어났는지 수치화한 지표로, 실패를 감지하는 핵심 신호. - Value-gated Early Termination: 모델의
Critic이 예측한 미래 가치(Value)를 임계값으로 사용하여, 저가치 상태에서 누적된Regret이 특정 수준을 넘을 때 추론을 강제 종료하는 기법. - Terminal Failure Penalty: 강제 종료된 트레젝토리를 '흡수 실패 상태(Absorbing Failure State)'로 간주하여 음의
TD-error를 집중시키는 방식.
2. Motivation & Problem Statement (연구 배경 및 문제 정의)
본 논문은 LLM의 다단계 추론(Multi-step reasoning) 과정에서 발생하는 연산 비효율성과 잘못된 학습 신호 문제를 해결하기 위해 ESPO를 제안한다. 기존의 PPO 기반 강화학습은 일단 오류가 발생한 궤적에 대해서도 최대 호라이즌까지 생성을 강제하는데, 이는 모델이 보상을 받을 수 없는 토큰에 컴퓨팅 자원을 낭비하게 한다 [Figure 1]. 더욱이, 이러한 '실패 후 토큰(Post-failure tokens)'들은 Advantage 추정치를 오염시켜 모델이 실패 모드로부터 올바르게 학습하는 것을 방해한다. 기존 연구들은 인간의 추가 주석이나 복잡한 termination 모듈 학습을 요구하지만, ESPO는 기존 학습 파이프라인의 로그와 가치 함수만을 재사용하여 이러한 문제를 효율적으로 해결하고자 한다.
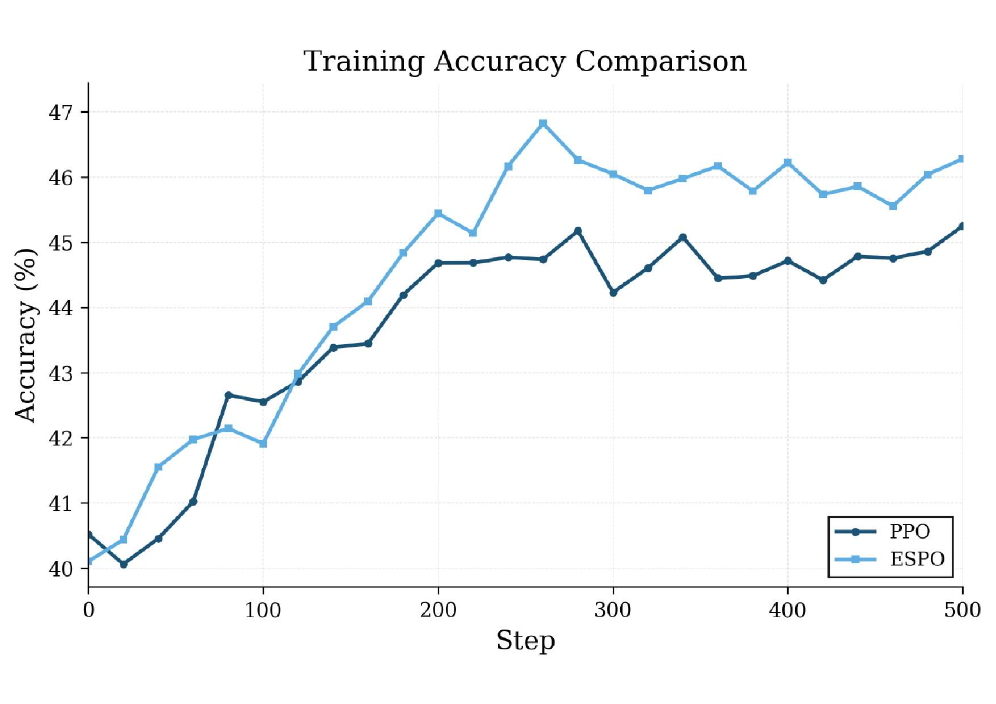
Figure 1 — ESPO의 성능 우위 및 토큰 절감 효과
3. Method & Key Results (제안 방법론 및 핵심 결과)
저자들은 정책의 내재적 로그 정보와 가치 함수의 가이드라인을 결합하여 실시간으로 추론 실패를 감지하는 ESPO를 제안한다. ESPO는 각 단계에서 Logit의 차이인 Stepwise deviation signal을 계산하고, 이를 EMA로 정규화한 뒤 누적하여 Value-gated 조건을 만족할 경우 즉시 roll-out을 중단한다 [Algorithm 1]. 실험 결과, DeepSeek-R1-Distill-Qwen-7B 모델을 사용한 평가에서 ESPO는 기존 PPO 대비 AIME 2024(46.28% vs 45.25%) 및 MATH-500(87.42% vs 85.43%) 등의 벤치마크에서 우수한 성능을 기록하였다 [Table 1]. 또한, 추론 과정에서 20% 이상의 토큰 연산량 절감을 달성하며 학습 효율성 면에서 월등한 우위를 점하였다 [Figure 1]. 이러한 정량적 성과는 단순히 추론 길이를 줄인 것이 아니라, 적절한 시점에 실패를 감지하여 고품질의 그래디언트 신호만을 학습에 활용한 결과로 해석된다.
4. Conclusion & Impact (결론 및 시사점)
ESPO는 LLM 강화학습에서 추론 궤적의 실패를 능동적으로 감지하고 종료함으로써 학습의 효율성과 정확도를 동시에 개선하는 프레임워크이다. 본 연구는 복잡한 추가 모델링 없이도 기존 Actor-Critic 아키텍처 내에서 즉시 적용 가능하다는 점에서 높은 범용성을 가진다. 연구진은 본 기법이 긴 추론 과정이 필요한 agentic 시스템이나 복합적인 수학적 문제 해결 모델의 학습 파이프라인을 최적화하는 데 핵심적인 기여를 할 것으로 기대한다. 향후 연구는 더욱 정교한 조기 종료 전략을 통해 초기에 잘못된 확신을 갖는(confidently wrong) 모델의 실패 케이스를 제어하는 방향으로 확장될 수 있다.
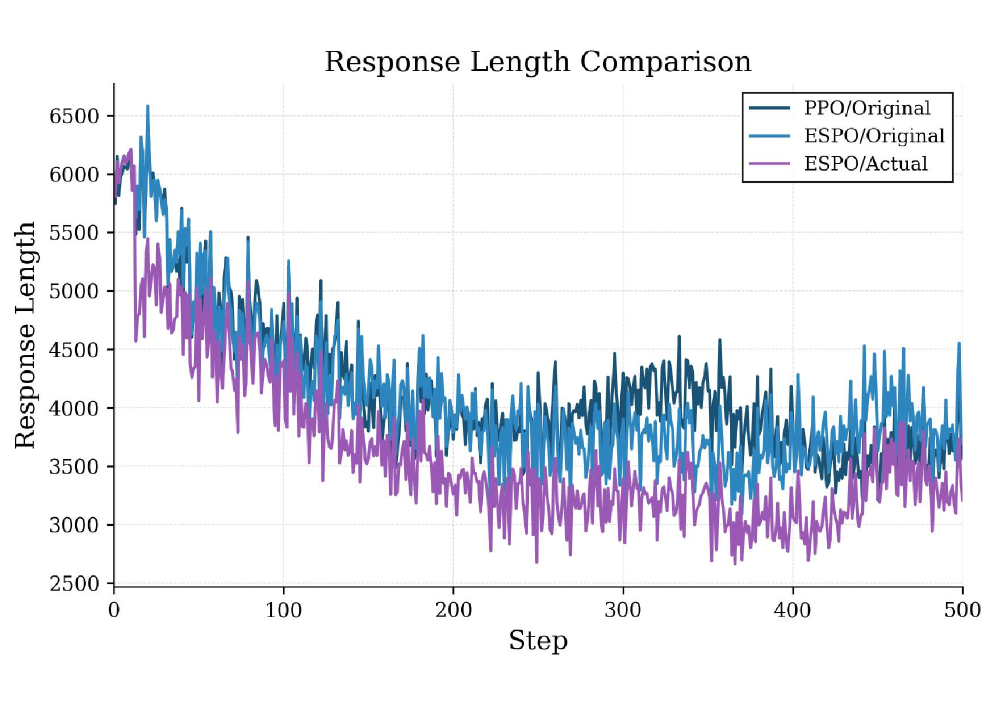
Figure 2 — ESPO 학습 다이내믹스 분석
⚠️ 알림: 이 리뷰는 AI로 작성되었습니다.
관련 포스트
- [논문리뷰] Agon: Competitive Cross-Model RL with Implicit Rival Grading of Reasoning
- [논문리뷰] Rethinking RL for LLM Reasoning: It's Sparse Policy Selection, Not Capability Learning
- [논문리뷰] Learning to Hint for Reinforcement Learning
- [논문리뷰] ThinkTwice: Jointly Optimizing Large Language Models for Reasoning and Self-Refinement
- [논문리뷰] Think Anywhere in Code Generation
Review 의 다른글
- 이전글 [논문리뷰] Domino: Decoupling Causal Modeling from Autoregressive Drafting in Speculative Decoding
- 현재글 : [논문리뷰] ESPO: Early-Stopping Proximal Policy Optimization
- 다음글 [논문리뷰] EVA01: Unified Native 3D Understanding and Generation via Mixture-of-Transformers
댓글