[논문리뷰] FineVerify: Scaling Test-Time Compute with Fine-Grained Self-Verification for Agentic Search
링크: 논문 PDF로 바로 열기
메타데이터
저자: James Xu Zhao, Hui Chen, Bryan Hooi, See-Kiong Ng
1. Key Terms & Definitions (핵심 용어 및 정의)
- Agentic Search: LLM 에이전트가 여러 단계에 걸쳐 스스로 쿼리를 생성하고, 웹을 탐색하며, 정보를 합성하여 복잡한 질문에 답하는 체계적인 정보 탐색 과정입니다.
- Test-Time Compute: 모델의 추론 단계에서 샘플링 횟수나 검증 과정을 늘려 연산 자원을 추가 투입함으로써 최종 응답의 정확도를 향상하는 전략입니다.
- Fine-Grained Verification: 전체 질문을 여러 개의 checkable sub-questions로 분해하여 각 항목에 대해 개별적인 증거 기반 검증(supported, not_found, contradicted)을 수행하는 방법론입니다.
- Selection Accuracy: 후보군(candidate pool) 내에 최소 하나 이상의 정답이 존재할 때, 특정 선택 방식이 얼마나 신뢰성 있게 해당 정답을 골라낼 수 있는지를 측정하는 지표입니다.
2. Motivation & Problem Statement (연구 배경 및 문제 정의)
본 논문은 기존의 Agentic Search 모델들이 겪는 정답의 희소성 문제와 기존 Test-Time Compute scaling 기법들이 가진 신뢰성 한계를 해결하고자 합니다. 기존 방식인 Majority Voting이나 Best-of-N은 정답이 아닌 오답(distractors)이 더 빈번하게 등장할 경우 성능이 저하되거나, 모델의 자기보고식 신뢰도 점수(self-reported confidence)에 과도하게 의존하여 성능이 안정적이지 못합니다. 특히 에이전트가 다루는 복잡한 다중 조건 질문에서는 전체 후보에 대해 단일 점수(single global score)를 매기는 방식이 노이즈가 많고 비교가 어렵다는 근본적인 문제가 있습니다. 이를 해결하기 위해 저자들은 질문을 분해하여 다수의 간단한 로컬 판단으로 변환하는 새로운 프레임워크인 FINEVERIFY를 제안합니다.
3. Method & Key Results (제안 방법론 및 핵심 결과)
FINEVERIFY는 입력을 checkable sub-questions로 분해하고, 각 후보 답변을 이 sub-questions에 대해 개별적으로 검증하여 생성된 evidence-grounded verification score를 바탕으로 최종 답안을 선택하는 프레임워크입니다. 이 방식은 rule-based scoring을 사용하여 판단의 투명성을 높이고, 특정 서브 질문이 충족되지 않으면 감점하는 방식으로 모델이 생성한 여러 후보 중 가장 논리적으로 타당한 답안을 식별합니다. 실험 결과, GPT-5-mini 모델의 경우 BrowseComp-Plus에서 4개의 샘플만으로 Pass@1 대비 8.2점의 정확도 향상을 기록했습니다 [Table 1]. 또한, 샘플 수를 12개로 늘렸을 때 GPT-5-mini는 기존 프런티어 모델인 GPT-5를 능가하는 성능을 보였습니다 [Figure 1]. Gemini-3-flash 역시 FINEVERIFY를 적용했을 때 평균 정확도가 71.3%에서 76.9%로 5.6점 상승하며 표준 scaling baselines을 압도하는 성과를 거두었습니다 [Table 1].
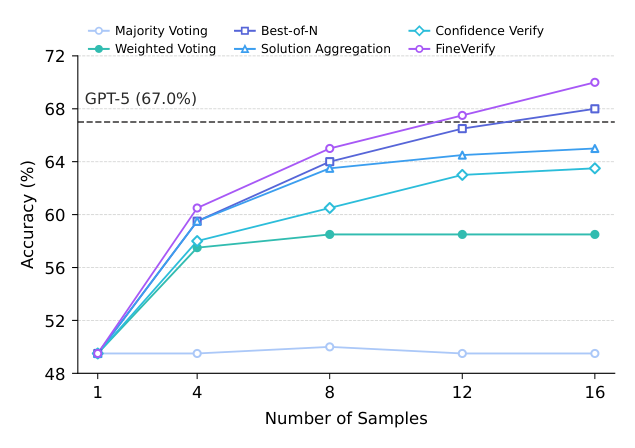
Figure 1 — 샘플링 횟수 증가에 따른 모델 성능 향상 추이를 보여주는 핵심 그래프
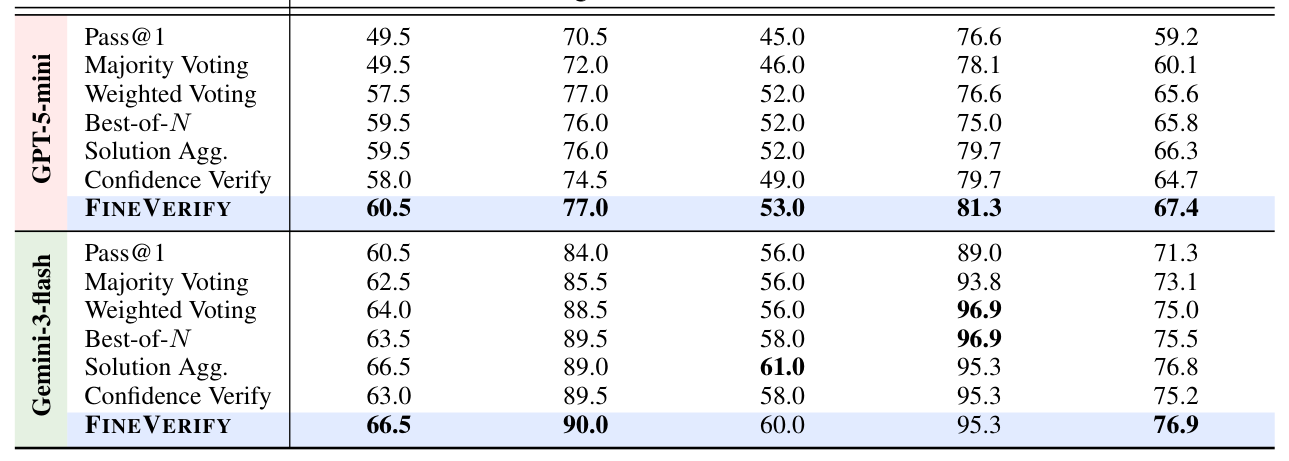
Table 1 — 제안 모델과 기존 baselines 간의 정확도 비교를 나타내는 핵심 결과표
4. Conclusion & Impact (결론 및 시사점)
FINEVERIFY는 에이전트의 테스트 타임 연산 자원을 단순 반복이 아닌 정밀한 증거 기반 검증으로 변환하여 훨씬 효율적으로 정확도를 개선할 수 있음을 입증했습니다. 특히 모델의 성능 향상뿐만 아니라, 검증 과정에서 생성되는 해석 가능한 trace를 통해 벤치마크 데이터셋의 오류를 감지하고 수정하는 Benchmark Auditing 도구로서의 유용성도 확인되었습니다. 이 연구는 복잡한 정보 탐색 작업에서 에이전트의 신뢰성과 투명성을 높이는 실용적인 경로를 제시하며, 향후 더 정교한 에이전트 설계 및 평가 시스템의 토대가 될 것으로 기대됩니다.
⚠️ 알림: 이 리뷰는 AI로 작성되었습니다.
관련 포스트
Review 의 다른글
- 이전글 [논문리뷰] EVA01: Unified Native 3D Understanding and Generation via Mixture-of-Transformers
- 현재글 : [논문리뷰] FineVerify: Scaling Test-Time Compute with Fine-Grained Self-Verification for Agentic Search
- 다음글 [논문리뷰] HakushoBench: A Japanese Chart and Table VQA Benchmark from Governmental White Papers
댓글