[논문리뷰] Measuring the Depth of LLM Unlearning via Activation Patching
링크: 논문 PDF로 바로 열기
메타데이터
저자: Jaeung Lee, Dohyun Kim, Jaemin Jo
1. Key Terms & Definitions (핵심 용어 및 정의)
- UDS (Unlearning Depth Score): 모델의 내부 활성화 값을
Activation Patching하여 망각(Unlearning)의 기계적 깊이를 정량화하는 지표입니다. - Activation Patching: 특정 모델의 중간 계층(Hidden states)을 다른 모델의 해당 위치에 삽입하여 지식의 복구 가능성을 인과적으로 검증하는 기법입니다.
- Faithfulness: 모델 내부에 잔존하는 지식을 얼마나 정확하게 탐지하는지를 나타내는 지표입니다.
- Robustness: 모델의 양자화(Quantization)나 재학습(Relearning)과 같은 외부 간섭에도 평가 결과가 얼마나 안정적으로 유지되는지를 측정하는 지표입니다.
2. Motivation & Problem Statement (연구 배경 및 문제 정의)
본 논문은 기존의 Output-level 메트릭이 모델 내부의 잔존 지식을 탐지하는 데 한계가 있다는 문제점을 제기합니다. 최근 연구들은 화이트박스 접근법을 통해 모델 내부의 지식 잔존을 확인하고 있으나, 데이터셋이나 보조 학습에 의존하여 범용적인 비교 지표가 부재한 상황입니다. 저자들은 기존 연구들이 모델의 표면적 출력만 평가함으로써 실제 지식의 삭제 여부를 오판할 위험이 있다고 지적합니다 [Figure 1]. 이러한 문제를 해결하기 위해 저자들은 훈련 과정이 필요 없고, 데이터셋에 독립적이며, 인과적 분석이 가능한 UDS를 제안합니다.
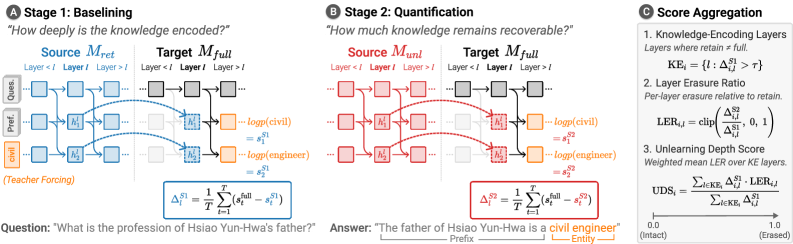
Figure 1 — UDS의 2단계 패칭 프로세스
3. Method & Key Results (제안 방법론 및 핵심 결과)
저자들이 제안하는 UDS는 두 단계의 Activation Patching 과정을 거칩니다. 첫 번째 단계(Baselining)에서는 Mret 모델의 활성화 값을 Mfull 모델에 패칭하여 지식을 인코딩하는 계층을 식별합니다. 두 번째 단계(Quantification)에서는 Munl 모델의 활성화 값을 동일하게 패칭하여 원래의 지식이 얼마나 잔존하는지를 0에서 1 사이의 점수로 정량화합니다 [Figure 1]. 150개의 망각 모델과 8개의 망각 기법을 포함한 20개 메트릭과의 메타 평가 결과, UDS는 가장 높은 Faithfulness (AUC-ROC 0.971)와 Robustness (HM 0.932)를 달성하였습니다 [Table 3]. 실험 결과, UDS는 Logit Lens와 같은 기존 화이트박스 기법보다 지식의 인과적 회복 가능성을 더 정확하게 포착하며, 다양한 모델 규모(1B, 3B, 8B)에서도 일관된 성능을 보였습니다 [Table 2].
4. Conclusion & Impact (결론 및 시사점)
본 연구는 UDS를 통해 LLM 망각 평가의 패러다임을 Output-level에서 인과적 Internal Representation 평가로 전환하였습니다. UDS는 기존 관측형 메트릭이 놓치기 쉬운 내부 잔존 지식을 효과적으로 탐지하며, 특히 망각 모델의 프라이버시 수준을 평가하는 표준적인 지표로 활용될 가능성을 제시합니다. 향후 연구자들은 이 메트릭을 통해 더욱 엄격하고 신뢰성 있는 AI 모델 안전성 평가 프레임워크를 구축할 수 있을 것으로 기대됩니다.
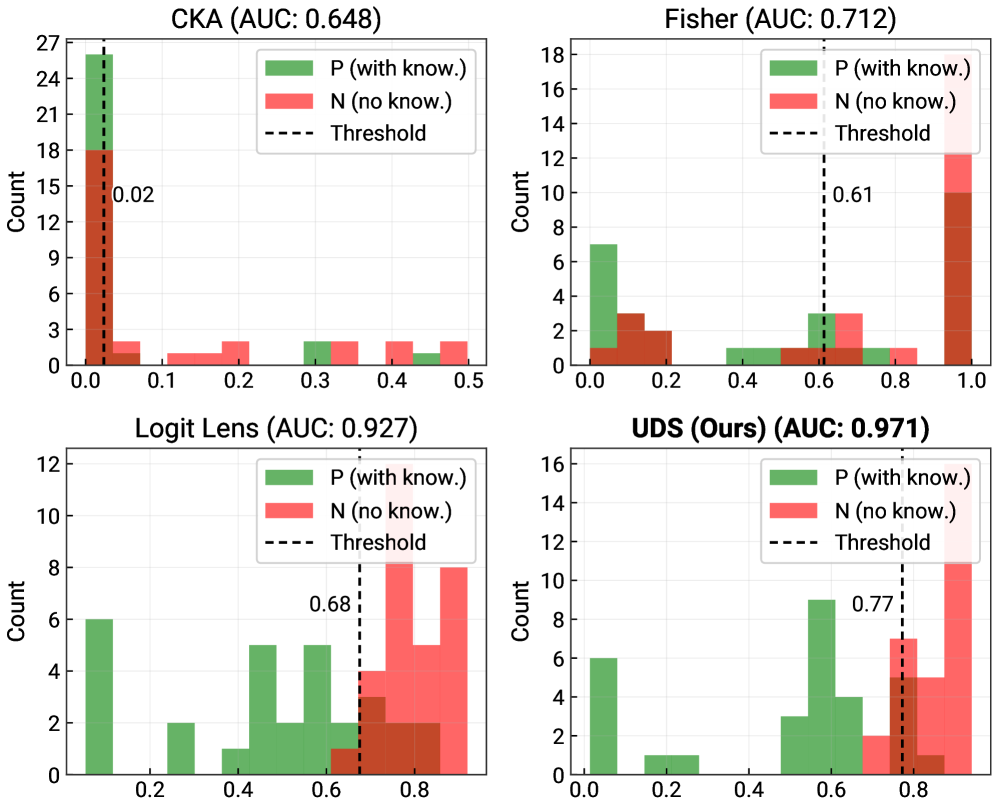
Figure 3 — 화이트박스 메트릭의 성능 비교
⚠️ 알림: 이 리뷰는 AI로 작성되었습니다.
관련 포스트
- [논문리뷰] RepSelect: Robust LLM Unlearning via Representation Selectivity
- [논문리뷰] RadAgent: A tool-using AI agent for stepwise interpretation of chest computed tomography
- [논문리뷰] On Robustness and Chain-of-Thought Consistency of RL-Finetuned VLMs
- [논문리뷰] Beyond Transcription: Mechanistic Interpretability in ASR
- [논문리뷰] NeuroCogMap Reveals Cognitive Organization of Large Language Models
Review 의 다른글
- 이전글 [논문리뷰] Masking Stale Observations Helps Search Agents -- Until It Doesn't: A Regime Map and Its Mechanism
- 현재글 : [논문리뷰] Measuring the Depth of LLM Unlearning via Activation Patching
- 다음글 [논문리뷰] MineExplorer: Evaluating Open-World Exploration of MLLM Agents in Minecraft
댓글