[논문리뷰] Multi-Agent Computer Use
링크: 논문 PDF로 바로 열기
메타데이터
저자: Jing Yu Koh, Ruslan Salakhutdinov, Daniel Fried, et al.
1. Key Terms & Definitions (핵심 용어 및 정의)
- CUA (Computer Use Agent): GUI 환경에서 사용자와 상호작용하여 작업을 수행하는 대리자(agent)입니다.
- MACU (Multi-Agent Computer Use): 복잡한 장기 작업(long-horizon task)을 관리자 모델과 여러 subagent가 협력하여 해결하는 시스템 프레임워크입니다.
- DAG (Directed Acyclic Graph): MACU에서 작업의 의존성과 흐름을 정의하는 구조로, 관리자 모델이 subtask들을 배치하고 실행 순서를 제어하는 청사진 역할을 합니다.
- Manager: 전체 작업을 계획하고 DAG를 생성하며, subagent의 실행 결과에 따라 지속적으로 DAG를 수정(replanning)하는 중심 제어 모듈입니다.
2. Motivation & Problem Statement (연구 배경 및 문제 정의)
본 논문은 현대의 CUA들이 주로 단일 직렬 에이전트 방식으로 운용됨에 따라 복잡하고 긴 호흡의 작업에서 한계를 보인다는 점을 해결하고자 합니다. 기존 방식은 작업 분해, 병렬 실행, 새로운 정보에 기반한 재계획이 부족하여 긴 작업 수행 시 쉽게 정체되는 문제를 겪습니다. 또한, CUA가 작동하는 운영체제 환경은 부분적으로만 관찰 가능한(partially observable) 복잡한 환경이므로, 이를 단순한 직렬 처리로 해결하기에는 한계가 명확합니다. 따라서 연구진은 계획과 병렬 실행을 강조하는 MACU 프레임워크를 도입하여 이러한 비효율성을 극복하고자 합니다.
3. Method & Key Results (제안 방법론 및 핵심 결과)
본 연구는 관리자 모델이 전체 작업을 DAG 형태의 subtask로 분해하고, 이를 CUA subagent들이 병렬로 수행하는 MACU 구조를 제안합니다 [Figure 1]. 관리자는 실행 중인 subagent의 결과와 환경 변화를 모니터링하며 필요시 노드를 추가, 삭제, 수정하거나 경로를 재설정하는 재계획(replanning) 과정을 수행합니다. 주요 실험 결과, MACU는 단일 에이전트 베이스라인 대비 OSWorld에서 최대 4.7%, WebTailBench-v2에서 8.7%, 그리고 Odysseys에서 25.5%의 높은 성공률 개선을 달성했습니다 [Table 1]. 특히 Odysseys 벤치마크에서는 병렬 실행 효율성을 통해 작업 완료 시간을 약 1.5배 단축하는 성과를 보였으며, 이는 MACU가 긴 호흡의 복잡한 작업에서 우수한 확장성을 가짐을 입증합니다 [Figure 3].
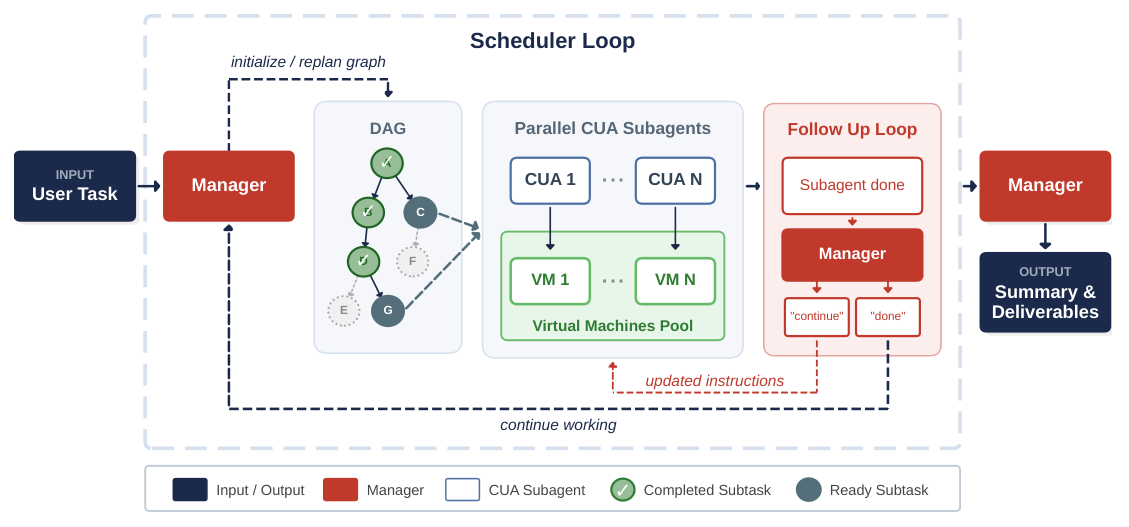
Figure 1 — MACU 시스템의 전체 구조와 관리자, subagent, DAG 간의 관계를 설명하는 핵심 다이어그램
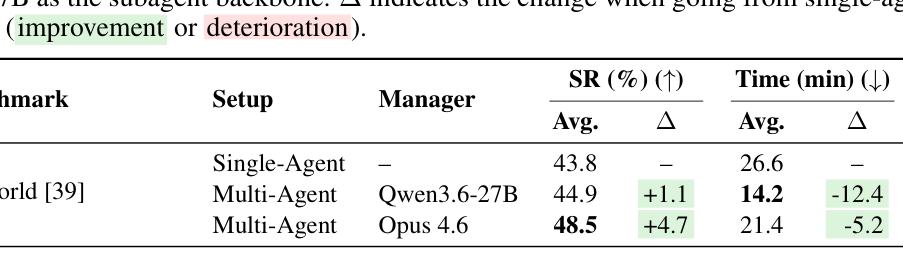
Table 1 — 제안된 MACU 시스템이 단일 에이전트 대비 성능 및 효율성 면에서 우수함을 보여주는 정량적 비교 데이터
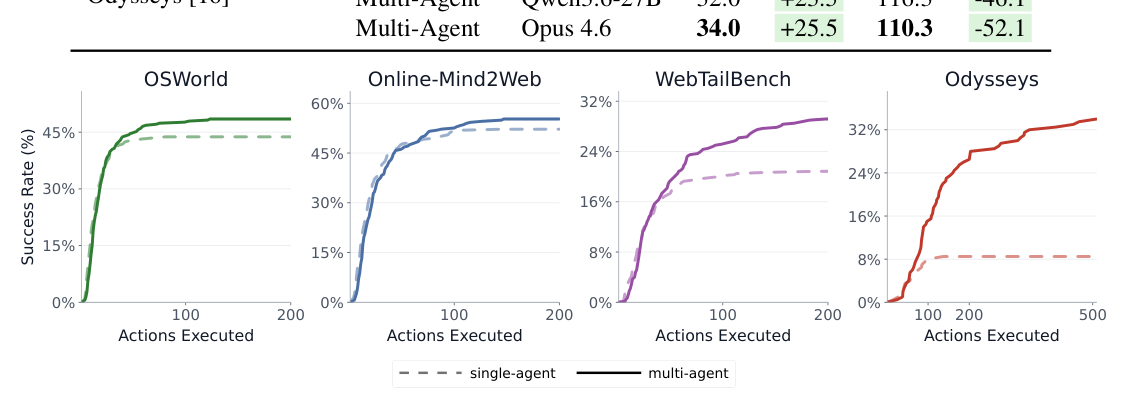
Figure 3 — 테스트 시간 동안의 컴퓨팅 자원 활용에 따른 성능 확장성(Scaling)을 보여주는 그래프
4. Conclusion & Impact (결론 및 시사점)
본 논문은 MACU 프레임워크가 복잡한 컴퓨터 사용 작업을 효과적으로 분해하고 조정함으로써 단일 직렬 에이전트의 한계를 뛰어넘을 수 있음을 보여줍니다. 이번 연구는 지속적인 재계획과 병렬적 실행이 에이전트의 생산성을 높이는 핵심 요소임을 강조하며, 향후 더 강력한 모델과의 결합을 통해 더 정교한 자율 에이전트 시스템을 구축하는 토대를 마련했습니다. 본 연구의 결과는 학계뿐만 아니라, 반복적인 소프트웨어 작업의 자동화를 꿈꾸는 산업계 전반에 걸쳐 컴퓨터 사용 대리자의 실용적 확장 가능성을 제시하고 있습니다.
⚠️ 알림: 이 리뷰는 AI로 작성되었습니다.
관련 포스트
- [논문리뷰] Orchestra-o1: Omnimodal Agent Orchestration
- [논문리뷰] WideSeek-R1: Exploring Width Scaling for Broad Information Seeking via Multi-Agent Reinforcement Learning
- [논문리뷰] Agon: Competitive Cross-Model RL with Implicit Rival Grading of Reasoning
- [논문리뷰] KnowAct-GUIClaw: Know Deeply, Act Perfectly, Personal GUI Assistant with Self-Evolving Memory and Skill
- [논문리뷰] Multi-Turn Agentic Scientific Literature Search via Workflow Induction
Review 의 다른글
- 이전글 [논문리뷰] MineExplorer: Evaluating Open-World Exploration of MLLM Agents in Minecraft
- 현재글 : [논문리뷰] Multi-Agent Computer Use
- 다음글 [논문리뷰] NITP: Next Implicit Token Prediction for LLM Pre-training
댓글