[논문리뷰] AURA: Action-Gated Memory for Robot Policies at Constant VRAM
링크: 논문 PDF로 바로 열기
Part 1: 요약 본문
메타데이터
저자: Josef Chen
1. Key Terms & Definitions (핵심 용어 및 정의)
- AURA-Mem: 로봇 정책을 위해 설계된 bounded fast-weight 기반의 메모리 아키텍처로, 학습된 게이트를 통해 액션과 관련된 중요한 정보만 선별적으로 저장합니다.
- Action-Utility Gate: 특정 Observation이 다음 액션 예측에 실질적인 변화를 줄 때만 메모리 업데이트를 수행하도록 결정하는 learned gate입니다.
- O(1) VRAM: 에피소드 길이에 관계없이 고정된 메모리 크기를 유지하여, 장시간 운용 시 메모리 사용량이 선형적으로 증가하는 기존 KV-cache의 한계를 극복합니다.
- Action-IB (Action-Information Bottleneck): 액션 시퀀스와 메모리 상태 간의 정보량을 최적화하여, 메모리 업데이트 횟수를 최소화하면서도 액션 정확도를 유지하도록 학습하는 목적 함수입니다.
- Fast-Weight: 신경망의 가중치를 입력 데이터에 따라 실시간으로 수정하는 기술로, 본 논문에서는 이 가중치 행렬 자체가 압축된 메모리 역할을 수행합니다.
2. Motivation & Problem Statement (연구 배경 및 문제 정의)
로봇 에이전트가 끊김 없이 지속적으로 동작하는 환경에서 기존의 Transformer KV-cache 방식은 에피소드 길이에 따라 메모리 요구량이 선형적으로 증가하여 에지 하드웨어의 메모리 대역폭을 심각하게 제한합니다. 특히, 고가의 HBM(High Bandwidth Memory)이 부족한 환경에서 불필요한 메모리 쓰기 작업은 컴퓨팅 성능보다 하드웨어 효율성을 저하시키는 결정적인 요인이 됩니다. 저자들은 단순한 과거 데이터 저장이나 무분별한 캐시 압축이 아닌, 현재 액션을 결정하는 데 필요한 핵심 정보를 선별하여 일정한 VRAM 내에서 효율적으로 관리해야 할 필요성을 제기합니다 [Figure 1].
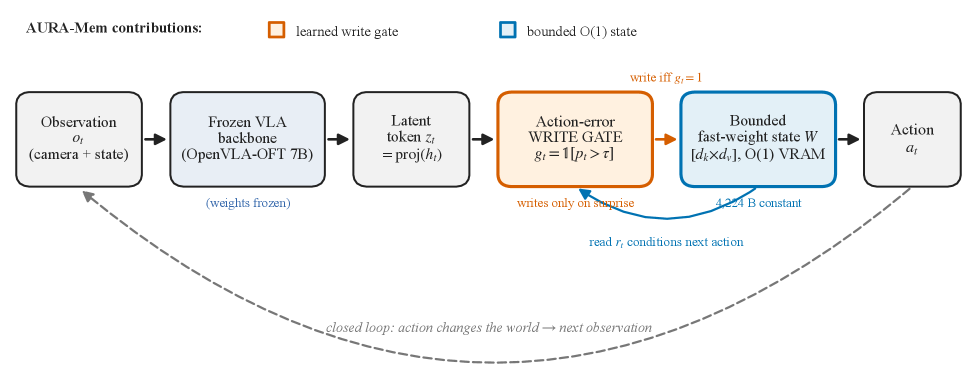
Figure 1 — AURA-Mem 전체 아키텍처
3. Method & Key Results (제안 방법론 및 핵심 결과)
본 논문은 Frozen VLA(Vision-Language-Action) 백본 모델 위에 AURA-Mem을 결합하여, 액션 예측 에러를 기반으로 메모리 쓰기를 제어하는 효율적인 프레임워크를 제안합니다. AURA-Mem은 Action-Utility Gate를 통해 예측 에러가 발생한 시점에만 메모리 쓰기를 수행하며, 쓰지 않는 구간에서는 기존의 메모리 상태를 그대로 유지하여 메모리 대역폭 소모를 최소화합니다 [Figure 2]. 주요 실험 결과, AURA-Mem은 제어 가능한 write-rate control을 통해 성능 손실 없이 기존 대비 4.98~9.19배 적은 메모리 쓰기 횟수를 달성하였습니다. 또한, 100,000 스텝의 장기 운용 시 기존 KV-cache 대비 메모리 점유율을 6,061배 감소시키면서도 동일한 수준의 액션 정확도를 보였습니다. 특히 LIBERO-Long 벤치마크 실험에서 OpenVLA-OFT 7B 모델과 결합했을 때, 7.0배 적은 메모리 쓰기만으로도 ungated 베이스라인과 동등한 성공률(0.233)을 기록하며 구조적 우위를 입증하였습니다.
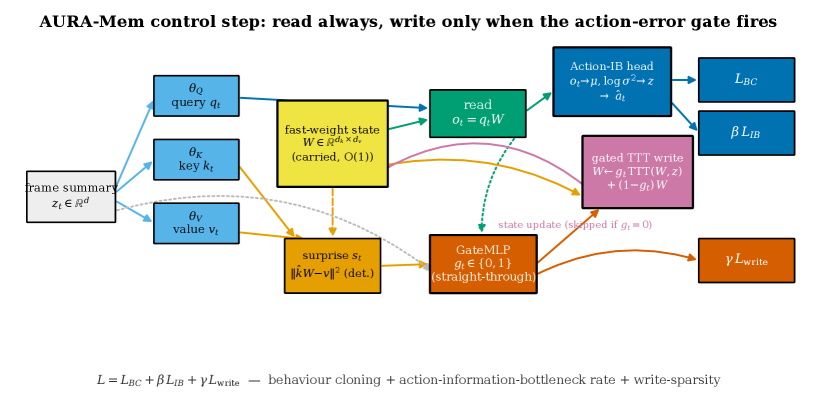
Figure 2 — AURA-Mem 단일 제어 스텝 데이터 경로
4. Conclusion & Impact (결론 및 시사점)
본 연구는 로봇 정책의 장기 운용 시 발생하는 '메모리 벽(Memory Wall)' 문제를 해결하기 위해, 액션 기반의 선별적 메모리 저장 방식인 AURA-Mem을 성공적으로 제시하였습니다. 이 방법론은 학습된 게이트를 활용하여 메모리 쓰기 대역폭을 획기적으로 줄임으로써 에지 하드웨어에서의 로봇 배치 효율성을 극대화합니다. 향후 학계 및 산업계에서 장기적인 작업을 수행하는 embodied AI 모델 설계 시, 불필요한 메모리 리소스 소모를 방지하는 표준적인 아키텍처로서 기여할 것으로 기대됩니다.
⚠️ 알림: 이 리뷰는 AI로 작성되었습니다.
관련 포스트
- [논문리뷰] Visual Para-Thinker++: A Single-Policy Multi-Agent Framework for Visual Reasoning
- [논문리뷰] Attention Amnesia in Hybrid LLMs: When CoT Fine-Tuning Breaks Long-Range Recall, and How to Fix It
- [논문리뷰] SpatialWorld: Benchmarking Interactive Spatial Reasoning of Multimodal Agents in Real-World Tasks
- [논문리뷰] Compress-Distill: Reasoning Trace Compression for Efficient Knowledge Distillation
- [논문리뷰] Video2LoRA: Parametric Video Internalization for Vision-Language Models
Review 의 다른글
- 이전글 [논문리뷰] A Multi-AI-agent Framework Enabling End-to-end Finite Element Analysis for Solid Mechanics Problems
- 현재글 : [논문리뷰] AURA: Action-Gated Memory for Robot Policies at Constant VRAM
- 다음글 [논문리뷰] Adaptive Auto-Harness: Sustained Self-Improvement for Agentic System Deployment on Open-Ended Task Streams
댓글