[논문리뷰] Decentralized Instruction Tuning: Conflict-Aware Splitting and Weight Merging
링크: 논문 PDF로 바로 열기
본 논문은 대규모 언어 모델(LLM) 및 멀티모달 모델의 instruction tuning 과정에서 발생하는 Gradient Interference와 통신 병목 현상을 해결하기 위해, 데이터셋 간 갈등을 사전에 파악하여 독립적으로 학습한 후 병합하는 MERIT (Merge-Ready Instruction Tuning) 프레임워크를 제안한다.
메타데이터
저자: Minsik Choi, Geewook Kim
1. Key Terms & Definitions (핵심 용어 및 정의)
- Merge-ready initialization: 모델들이 독립적으로 fine-tuning을 수행한 후에도 동일한 Flat Basin 내에 머물러 있어, 사후 병합(merging)이 모델 성능 저하 없이 가능한 최적화 상태의 시작점.
- Gradient Interference: 이질적인 데이터셋(heterogeneous mixture)으로 학습 시 발생하는 상충되는 그래디언트 업데이트로, 학습 속도를 저하시키고 모델 성능을 제약하는 현상.
- PCA-aligned Conflict Splitting: 데이터셋 수준의 그래디언트 갈등을 Principal Component Analysis (PCA)로 분해하여, 가장 갈등이 심한 고곡률(high-curvature) 방향을 따라 데이터셋을 분할하는 전략.
- Token-weighted Merging: 개별 브랜치에서 학습된 모델들을 병합할 때, 각 브랜치에 할당된 데이터의 토큰 수를 가중치로 활용하여 가중 평균(weighted averaging)을 수행하는 기법.
2. Motivation & Problem Statement (연구 배경 및 문제 정의)
본 연구는 대규모 instruction tuning에서 발생하는 Gradient Interference와 시스템 통신 병목이라는 두 가지 핵심 문제를 동시에 해결하고자 한다. 기존의 중앙 집중식(Centralized) 방식은 모든 데이터를 하나의 모델에 순차적으로 업데이트해야 하므로 대규모 클러스터에서의 빈번한 그래디언트 동기화가 필수적이며, 이질적인 데이터 간의 간섭으로 인해 최적의 학습 속도와 성능을 달성하기 어렵다 [Figure 1]. 이러한 한계는 이질적인 연산 환경이나 대역폭이 제한된 상황에서 큰 장애물이 된다. 따라서 저자들은 데이터셋을 독립적인 그룹으로 분할하여 병렬로 학습하고, 이를 파라미터 공간에서 한 번만 병합하는 새로운 접근 방식을 통해 통신 비용을 최소화하고 병목 현상을 타개하고자 한다.
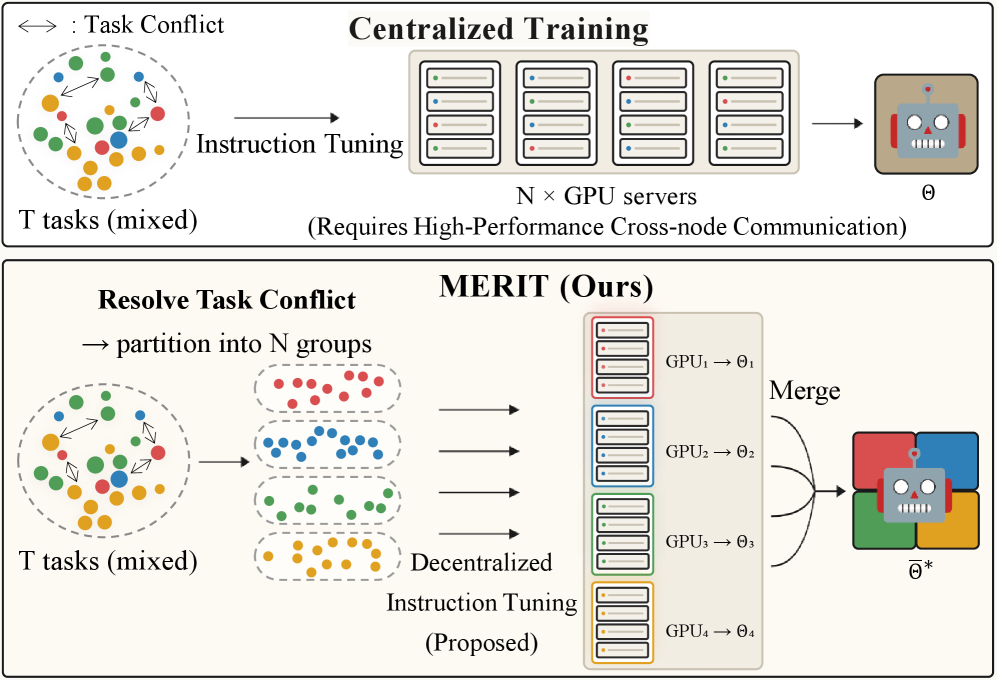
Figure 1 — 중앙 집중식 학습과 MERIT 비교
3. Method & Key Results (제안 방법론 및 핵심 결과)
저자들이 제안하는 MERIT는 먼저 소량의 캘리브레이션 데이터셋을 통해 데이터셋 수준의 그래디언트 갈등을 추정하고, PCA를 이용해 갈등이 큰 고곡률 축을 따라 데이터셋을 분할한다 [Figure 2]. 이후, 각 파티션은 통신 없이 독립적으로 fine-tuning을 수행하며, 최종적으로 모델 가중치를 Token-weighted Merging을 통해 결합한다. 이론적 분석에 따르면 병합 과정은 곡률 가중치 분산 감소(curvature-weighted variance reduction)를 유도하며, 제안된 PCA 분할은 이를 극대화한다. 실험 결과, Qwen2.5-VL-3B 모델에서 136개의 Vision-FLAN 태스크를 수행했을 때, 기존 Joint Training 대비 8개 벤치마크 평균 성능이 54.3에서 57.0으로 향상되는 성과를 거두었다. 또한, 7B 파라미터 모델과 176개 데이터 소스를 포함한 1.6M 예제 규모에서도 중앙 집중식 학습 성능을 상회하거나 대등한 수준을 유지하면서 학습 비용을 획기적으로 낮췄다.
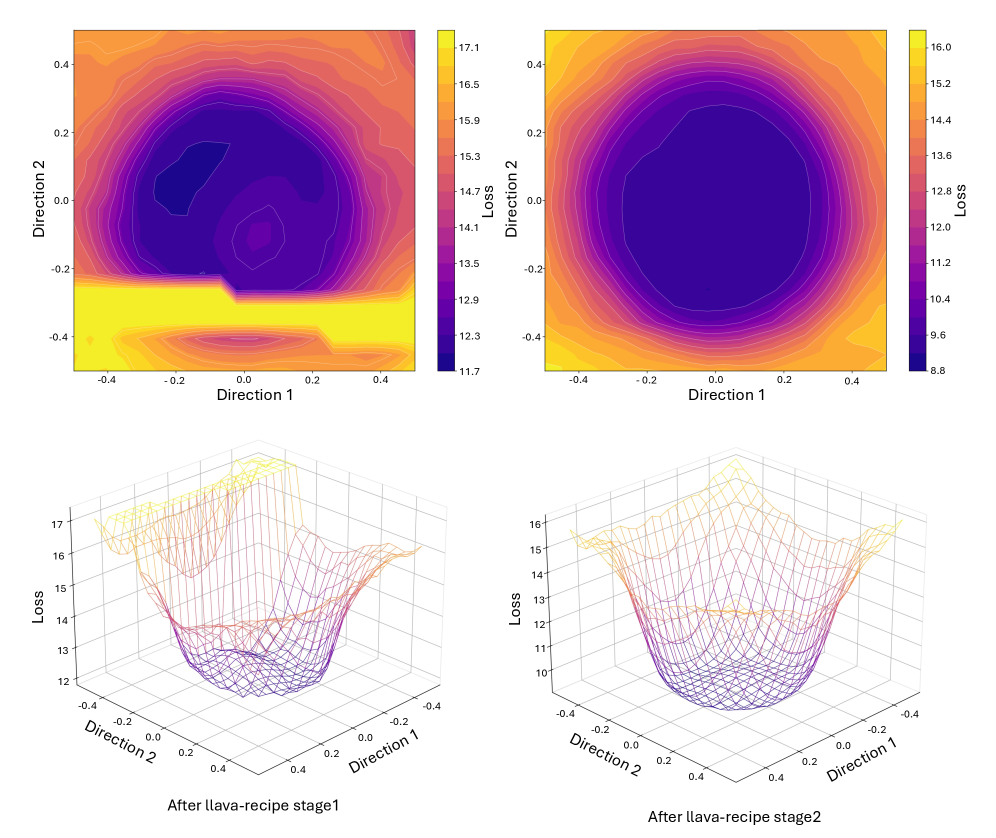
Figure 2 — 학습 전후의 로컬 손실 표면
4. Conclusion & Impact (결론 및 시사점)
본 논문은 decentralized instruction tuning을 위한 이론적 프레임워크와 실용적인 파이프라인인 MERIT를 성공적으로 구축하였다. 이 연구는 데이터셋 간의 갈등을 학습 전 단계에서 효율적으로 분해함으로써, 대규모 모델 학습에서 통신 비용을 제거하면서도 성능 향상을 도모할 수 있음을 입증하였다. 향후 본 연구는 이질적인 연산 자원을 사용하는 지오 분산형(geo-distributed) 환경이나 클라우드 스팟 인스턴스 환경에서 거대 모델 학습의 효율성을 극대화하는 표준 방법론으로 활용될 것으로 기대된다.
⚠️ 알림: 이 리뷰는 AI로 작성되었습니다.
관련 포스트
- [논문리뷰] What does RL improve for Visual Reasoning? A Frankenstein-Style Analysis
- [논문리뷰] Adapting Vision-Language Models for E-commerce Understanding at Scale
- [논문리뷰] EchoVLM: Dynamic Mixture-of-Experts Vision-Language Model for Universal Ultrasound Intelligence
- [논문리뷰] Hala Technical Report: Building Arabic-Centric Instruction & Translation Models at Scale
- [논문리뷰] VisCodex: Unified Multimodal Code Generation via Merging Vision and Coding Models
Review 의 다른글
- 이전글 [논문리뷰] ClawHub Security Signals: When VirusTotal, Static Analysis, and SkillSpector Disagree
- 현재글 : [논문리뷰] Decentralized Instruction Tuning: Conflict-Aware Splitting and Weight Merging
- 다음글 [논문리뷰] Decoupled Residual Denoising Diffusion Models for Unified and Data Efficient Image-to-Image Translation
댓글