[논문리뷰] ClawHub Security Signals: When VirusTotal, Static Analysis, and SkillSpector Disagree
링크: 논문 PDF로 바로 열기
메타데이터
저자: Vincent Koc, Patrick Erichsen, Jacob Tomlinson, Agustin Rivera, Michael Appel, Nir Paz
1. Key Terms & Definitions (핵심 용어 및 정의)
- Agent Skills: LLM 에이전트에게 절차적 지식, 도구 사용법, 스크립트 및 워크플로우를 제공하는 재사용 가능한 소프트웨어 번들입니다.
- ClawScan: OpenClaw 레지스트리 내에서 스킬의 신뢰성을 검증하기 위해 여러 스캐너의 입력과 메타데이터를 종합하여 최종 Verdict를 결정하는 자동화된 검증 파이프라인입니다.
- SkillSpector: 스킬의 instruction, 선언된 capability, 메타데이터를 분석하여 semantic agentic-risk에 대한 조언(Advisory)을 제공하는 NVIDIA의 스캔 도구입니다.
- Scanner Disagreement: 동일한 대상에 대해 서로 다른 보안 스캐너가 서로 다른 탐지 결과를 내놓는 현상으로, 본 논문에서는 이를 시스템적 다층 방어의 필요성으로 해석합니다.
- Silver-Standard Dataset: 완벽한 인간의 라벨링이 아닌, 자동화된 도구(registry verdict)를 기반으로 구축된 데이터셋으로, 연구 및 툴 개발을 위한 초기 버전임을 명시합니다.
2. Motivation & Problem Statement (연구 배경 및 문제 정의)
본 논문은 LLM 에이전트 생태계에서 핵심 소프트웨어 단위인 Agent Skills의 보안 문제를 다루며, 서로 다른 보안 스캐너(VirusTotal, Static Analysis, SkillSpector)들이 동일한 스킬에 대해 불일치하는 결과를 보일 때 이를 어떻게 해석하고 대응할 것인지에 대한 문제를 제기한다. 기존 연구들은 개별 탐지기의 성능에 의존하여 보안 위협의 유병률(prevalence)을 측정하는 데 그쳤으나, 본 연구는 검출기 간의 불일치가 무작위적인 오류가 아닌 각 스캐너가 검사하는 attack surface의 차이에서 기인한다는 점을 밝힌다. 특히 스킬의 위협은 번들된 코드뿐만 아니라 instruction과 권한 설정 등 다층적인 영역에 걸쳐 존재하므로, 단일 스캐너의 allow/block 결정만으로는 안전성을 보장할 수 없다는 한계가 존재한다 [Figure 1].
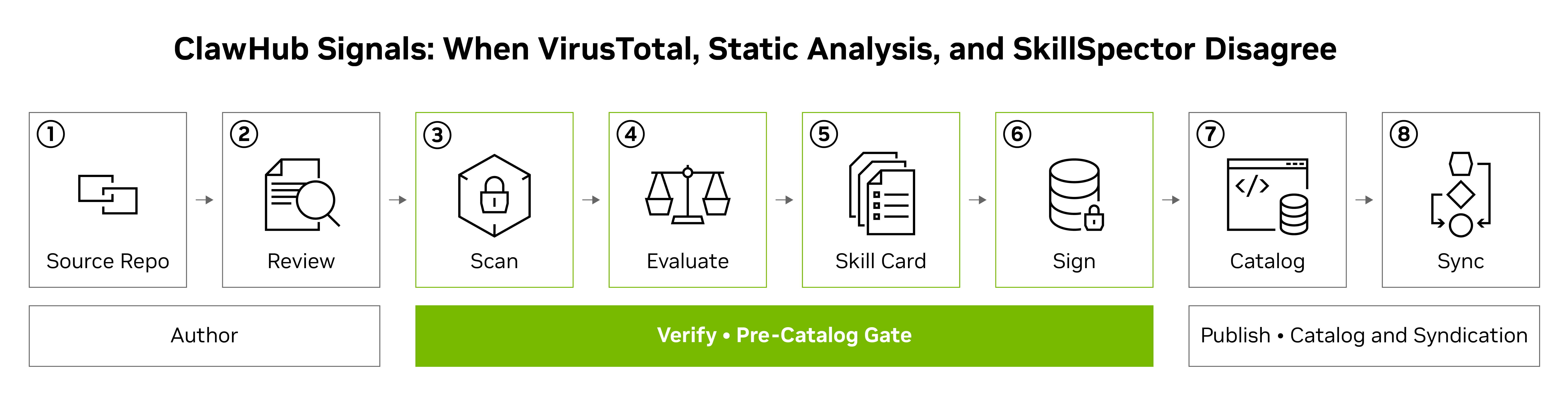
Figure 1 — ClawHub 스킬 검증 파이프라인
3. Method & Key Results (제안 방법론 및 핵심 결과)
본 논문은 67,453개의 OpenClaw 스킬 버전을 포함하는 ClawHub Security Signals 데이터셋을 구축하고, 세 가지 독립적인 스캐너 패밀리의 신호를 레지스트리의 최종 ClawScan Verdict와 결합하여 분석한다. 저자들은 데이터셋 내 스킬들의 검출 현황을 조사한 결과, 전체의 52.8%가 최소 하나의 스캐너에서 positive 신호를 보였으나, 세 스캐너가 모두 동의한 비율은 0.69%에 불과함을 확인했다. 또한 pairwise agreement 분석에서 Jaccard 지수 0.104 이하, Cohen’s κ 값이 0.082 이하를 기록하며 스캐너 간 매우 낮은 상관관계를 증명했다 [Table 4]. 핵심 결과로서, SkillSpector는 suspicious 판정 스킬의 75.3%를 탐지한 반면, VirusTotal은 malicious 판정 스킬의 72.8%를 탐지하는 구조적 전문화 현상을 보였다. 이는 에이전트 보안이 bundled-code 분석(VirusTotal)과 semantic agentic-risk 분석(SkillSpector)의 결합을 필요로 하는 다층적 거버넌스임을 정량적으로 시사한다.
4. Conclusion & Impact (결론 및 시사점)
본 논문은 Agent Skills에 대한 보안이 단순한 악성코드 탐지를 넘어, 기술된 의도와 실제 동작 간의 불일치를 판단하는 다층적 거버넌스임을 결론짓는다. 이러한 Scanner Disagreement는 스캐너의 결함이 아니라 각 탐지기가 서로 다른 보안 표면(attack surface)을 다루기 때문에 발생하는 구조적 특징이다. 본 연구가 배포한 Silver-Standard Dataset은 향후 연구자들이 스킬 보안 triage 모델을 개발하거나, 자동화된 검증 파이프라인을 개선하는 데 핵심적인 지표가 될 것이다. 결과적으로 본 연구는 AI 에이전트 생태계의 신뢰성을 확보하기 위해 개별 보안 도구의 결과값을 합산하는 대신, 상호 보완적인 보안 신호를 활용하는 systemic defense 체계 구축의 중요성을 강조한다.
⚠️ 알림: 이 리뷰는 AI로 작성되었습니다.
관련 포스트
- [논문리뷰] OpenSkillEval: Automatically Auditing the Open Skill Ecosystem for LLM Agents
- [논문리뷰] SkillGrad: Optimizing Agent Skills Like Gradient Descent
- [논문리뷰] SkillsVote: Lifecycle Governance of Agent Skills from Collection, Recommendation to Evolution
- [논문리뷰] Evoflux: Inference-Time Evolution of Executable Tool Workflows for Compact Agents
- [논문리뷰] EvoArena: Tracking Memory Evolution for Robust LLM Agents in Dynamic Environments
Review 의 다른글
- 이전글 [논문리뷰] Bootstrap Your Generator: Unpaired Visual Editing with Flow Matching
- 현재글 : [논문리뷰] ClawHub Security Signals: When VirusTotal, Static Analysis, and SkillSpector Disagree
- 다음글 [논문리뷰] Decentralized Instruction Tuning: Conflict-Aware Splitting and Weight Merging
댓글