[논문리뷰] SkillGrad: Optimizing Agent Skills Like Gradient Descent
링크: 논문 PDF로 바로 열기
Part 1: 요약 본문
저자: Hanyu Wang, Yifan Lan, Bochuan Cao, Lu Lin, Jinghui Chen
1. Key Terms & Definitions (핵심 용어 및 정의)
- Agent Skills: LLM 에이전트가 특정 도메인 작업(예: 스프레드시트 조작)을 수행하기 위해 로드하는 재사용 가능한 구조화된 파일 패키지입니다.
- SkillGrad: 에이전트 스킬을 최적화하기 위해 Gradient Descent의 개념적 구조(Parameter, Loss Evidence, Gradient, Momentum, Update)를 도입한 최적화 프레임워크입니다.
- Structured Skill Package: 메타데이터(L1), 핵심 지침(L2, SKILL.md), 조건부 참조 자료(L3, Resources)로 구성된 최적화 가능한 파라미터 객체입니다.
- Textual Momentum: 이전 반복(iteration)에서 학습된 진단 패턴을 저장하는 persistent memory로, 최적화 과정의 안정성을 높이고 재사용 가능한 행동을 보존합니다.
- Layer-aware Patching: 스킬의 계층 구조를 이해하고, Diagnoser로부터 도출된 textual update signals를 기반으로 L2/L3 내 적절한 위치에 지침을 수정하거나 추가하는 과정입니다.
2. Motivation & Problem Statement (연구 배경 및 문제 정의)
본 논문은 LLM 에이전트의 도메인 적응력을 높이기 위한 Agent Skills가 흔히 불완전하거나, 시대에 뒤떨어지거나, 신뢰할 수 없다는 문제를 해결하고자 합니다. 기존의 스킬 진화 방식은 휴리스틱한 반성(heuristic reflection)에 의존할 뿐, 명확한 최적화 공식이 결여되어 있어 체계적인 개선이 어렵다는 한계가 있습니다. 이를 극복하기 위해 저자들은 스킬 패키지를 최적화 가능한 구조적 파라미터로 정의하고, Gradient Descent의 연산 구조를 텍스트 도메인에 적용하여 스킬의 질을 체계적으로 향상시키는 방법을 제안합니다 [Table 1].
3. Method & Key Results (제안 방법론 및 핵심 결과)
SkillGrad는 작업을 수행한 후, 실패한 궤적과 성공한 궤적의 차이를 분석하여 textual gradients를 생성하는 최적화 루프를 중심으로 작동합니다. 각 반복마다 에이전트는 작업을 수행하고, Diagnoser가 이 과정에서 얻은 trajectory evidence를 토대로 업데이트 신호를 도출합니다. 이후 Textual Momentum 모듈이 recurring diagnostic patterns를 memory에 기록하여 학습 방향을 안정화하며, 최종적으로 Patcher가 Layer-aware 방식을 통해 구조화된 스킬 패키지를 수정합니다 [Figure 1].
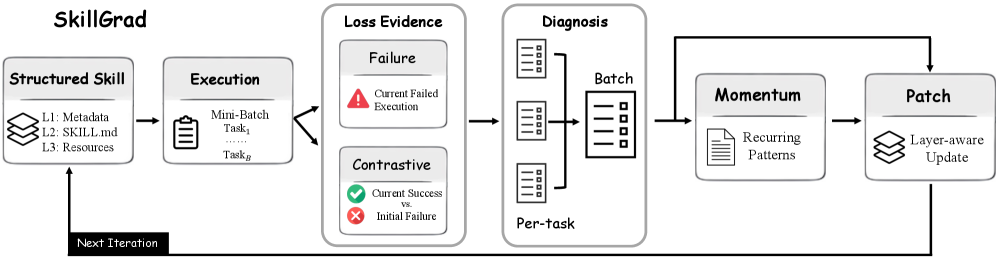
Figure 1 — SkillGrad 전체 아키텍처
실험 결과, SpreadsheetBench Verified와 WikiTableQuestions에서 SkillGrad는 강력한 baseline인 EvoSkill 및 Trace2Skill보다 우수한 성능을 보였습니다. 구체적으로, gpt-5.4 backbone 사용 시 LLM-generated 초기 스킬에서 기존 최강 baseline 대비 평균 4.44 pp 높은 성능 향상을 기록했습니다. 또한, gpt-4.1 환경에서는 baseline인 Trace2Skill과 EvoSkill이 37.22%의 정확도를 보인 반면, SkillGrad는 54.17%를 달성하여 16.95 pp 이상의 압도적인 우위를 입증했습니다 [Table 2]. 아블레이션 연구에서는 Textual Momentum과 Contrastive Diagnosis를 제거할 경우 성능이 유의미하게 하락함을 확인하여 제안된 각 모듈의 기여도를 검증하였습니다 [Table 3].
4. Conclusion & Impact (결론 및 시사점)
본 논문은 에이전트 스킬의 진화 과정을 명확한 최적화 프레임워크로 정립하여, 고비용의 미세 조정(fine-tuning) 없이도 효과적으로 스킬을 개선할 수 있는 경로를 제시합니다. 제안된 SkillGrad는 초기 스킬의 출처와 관계없이 일관된 성능 향상을 보이며, OOD(Out-of-Domain) 환경에서도 재사용 가능한 프로시저 지침을 생성함을 확인했습니다. 이 연구는 앞으로 복잡한 에이전트 시스템의 자율적 지식 보존 및 진화 연구에 중요한 방법론적 토대가 될 것으로 기대됩니다.
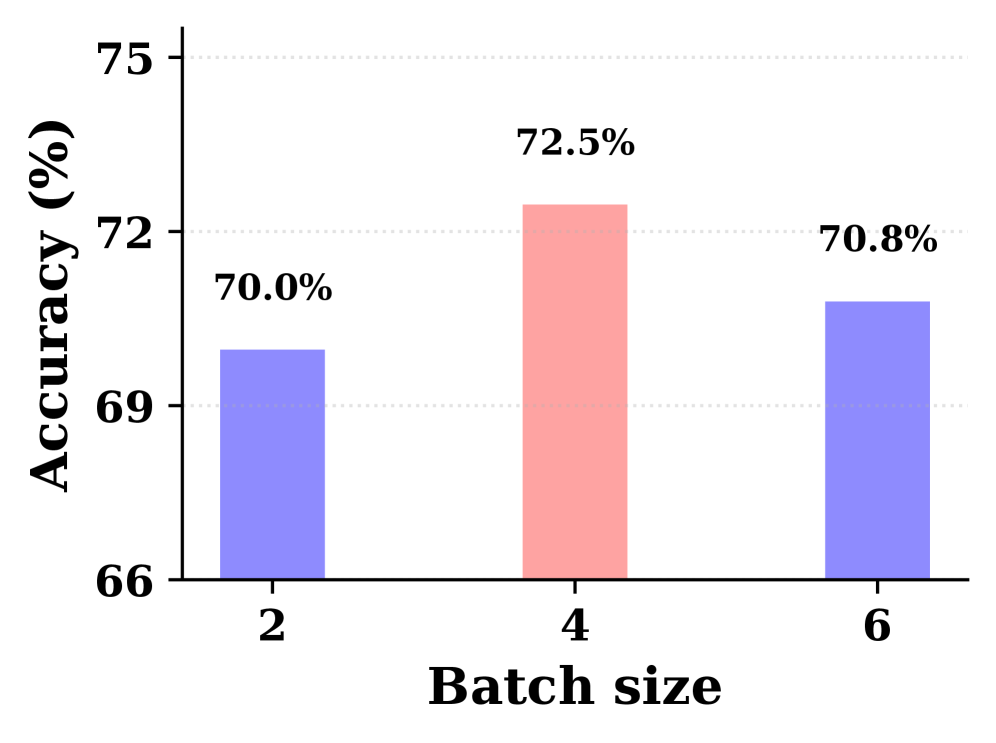
Figure 2 — Batch size에 따른 분석
⚠️ 알림: 이 리뷰는 AI로 작성되었습니다.
관련 포스트
- [논문리뷰] SkillsVote: Lifecycle Governance of Agent Skills from Collection, Recommendation to Evolution
- [논문리뷰] OpenSkill: Open-World Self-Evolution for LLM Agents
- [논문리뷰] ClawHub Security Signals: When VirusTotal, Static Analysis, and SkillSpector Disagree
- [논문리뷰] OpenSkillEval: Automatically Auditing the Open Skill Ecosystem for LLM Agents
- [논문리뷰] SkillEvolBench: Benchmarking the Evolution from Episodic Experience to Procedural Skills
Review 의 다른글
- 이전글 [논문리뷰] Self-Improving Language Models with Bidirectional Evolutionary Search
- 현재글 : [논문리뷰] SkillGrad: Optimizing Agent Skills Like Gradient Descent
- 다음글 [논문리뷰] The Fragility of Chain-of-Thought Monitoring Across Typologically Diverse Languages
댓글