[논문리뷰] SkillEvolBench: Benchmarking the Evolution from Episodic Experience to Procedural Skills
링크: 논문 PDF로 바로 열기
저자: Yingtie Lei, Zhongwei Wan, et al.
1. Key Terms & Definitions (핵심 용어 및 정의)
- LLM Agents: Large Language Models (LLMs)를 기반으로 하여 추론, 도구 호출, 파일 검사, 코드 실행 및 피드백 관찰 등을 통해 외부 환경과 상호 작용하며 다단계 작업을 해결하는 시스템.
- Episodic Experience: LLM Agents가 실제 작업을 해결하는 동안 축적하는 풍부한 궤적(trajectories) 데이터로, 특정 작업 시도 중에 발생한 모든 단계를 기록한다.
- Procedural Skills: 재사용 가능한 노하우(know-how)를 외부 아티팩트(artifacts) 형태로 변환한 것으로, 에이전트가 관련 작업을 수행할 때 원본 에피소드를 다시 재생하지 않고도 로드, 호출 및 따를 수 있는 명시적인 절차적 형태를 의미한다.
- Skill Author: 에피소드 궤적 요약과 검증자 피드백을 사용하여 새로운 Skill을 작성하거나, 기존 Skill을 수정하거나, Skill 라이브러리 업데이트를 건너뛸지 결정하는 호스트 측 호출(host-side call) 메커니즘.
- Frozen Deployment: Skill 라이브러리가 더 어려운 관련 작업에 대해 평가되기 전에 더 이상 수정할 수 없도록 고정되는 단계로, 이전 경험이 직접적인 추적 재생, 지속적인 적응 또는 테스트 시점의 수정이 아닌 재사용 가능한 절차로 변환되었는지 여부에 따라 성공이 결정된다.
2. Motivation & Problem Statement (연구 배경 및 문제 정의)
본 논문은 LLM Agents가 실제 작업을 해결하면서 축적하는 풍부한 Episodic Experience가 재사용 가능한 Procedural Skills로 증류될 수 있는지 여부가 불분명하다는 핵심 문제를 제기한다. 기존 연구들은 에이전트가 이전 경험을 재사용하여 성능을 향상시킬 수 있음을 보여주었지만, 이러한 경험이 단순한 에피소드 재생을 넘어 명시적이고 전이 가능한 절차적 지식으로 전환되는지에 대한 연구는 부족했다. 특히, 기존의 SkillsBench는 큐레이트된 Skill이 성능을 향상시키지만, "cold-start" 자가 생성 Skill은 제한적인 이점을 제공한다고 밝혔다. 이는 Skill use와 Skill formation 사이의 중요한 격차를 드러내며, 노이즈가 많은 일회성 경험을 향후 에이전트가 원본 에피소드를 넘어서 적용할 수 있는 압축된 Skill로 추출할 수 있는지에 대한 질문을 남겼다. 저자들은 이러한 격차를 해결하기 위해 SkillEvolBench를 제안하여, 에피소드적 경험이 견고하고 재사용 가능한 Procedural Skills로 진화하는 과정을 진단하고자 한다 [Figure 1].
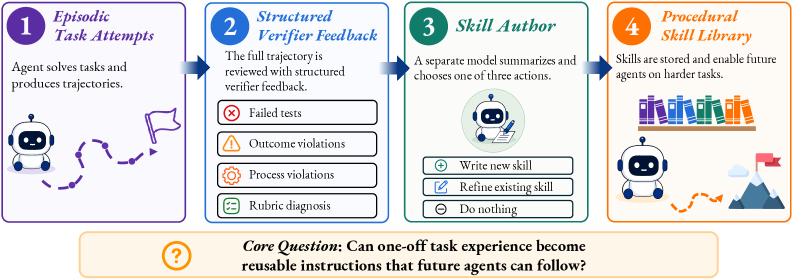
Figure 1 — SkillEvolBench 개요
3. Method & Key Results (제안 방법론 및 핵심 결과)
저자들은 Episodic Experience가 Procedural Skills로 변환되는 과정을 평가하기 위해 SkillEvolBench 벤치마크와 Skill Evolution Protocol을 제안한다. SkillEvolBench는 6가지 실제 에이전트 환경에 걸쳐 180개의 작업을 포함하며, 각 환경은 5개의 Task Family로 구성되고 각 가족은 공유된 잠재적 절차를 갖는다 [Figure 2]. 각 가족 내에서 에이전트는 Acquisition Tasks(canonical, enriched, variant)를 통해 학습하고, Compacted Trajectories 및 Verifier Feedback을 사용하여 외부 Skill Library를 업데이트한다. 이 라이브러리는 Frozen Deployment Tasks(context-shift, adversarial, composition)에 직면하기 전에 고정되어, 이전 경험이 직접적인 추적 재생이 아닌 재사용 가능한 절차로 변환되었는지 여부에 따라 성공이 결정된다 [Figure 3]. 이 프로토콜은 No-Skill, Raw-Trajectory, Curated-Start, Self-Generated 등의 다양한 조건에서 10가지 모델 구성과 3가지 에이전트 하니스(Claude Code, Codex CLI, Gemini CLI)를 평가했다.
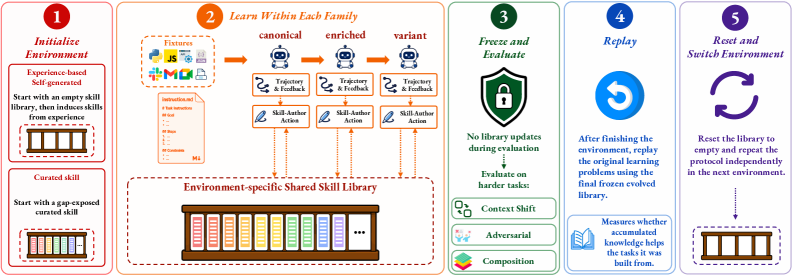
Figure 3 — SkillEvolBench 평가 프로토콜
주요 결과는 현재 에이전트가 국소적으로는 적응하지만, 견고하고 재사용 가능한 Procedural Skills를 안정적으로 형성하지 못한다는 것을 보여준다. Skill-based conditions는 LSR (Acquisition Success Rate) 또는 RSR (Replay Success Rate)을 개선할 수 있지만, 이러한 개선이 ESR (Frozen Deployment Success Rate), CSSR (Context-Shift Success Rate), ARSR (Adversarial Robustness Success Rate), CompSR (Composition Success Rate)과 같은 Frozen Deployment Tasks로 일관되게 전이되지 않는다 [Table 1, Table 2]. 특히, Raw-Trajectory 컨트롤과의 비교에서 Skill 추상화가 손실을 초래하는 병목 현상(Lossy Abstraction Bottleneck)을 나타낸다; 에이전트는 종종 증류된 Skill보다 에피소드 궤적을 직접적으로 더 효과적으로 사용한다 [Figure 4]. 이는 Skill 추상화 과정에서 전이, 견고성 및 구성에 필요한 상황적, 절차적 단서가 손실될 수 있음을 시사한다. 또한, Tier-3 Capacity Diagnostic을 통해 Skill 라이브러리의 크기를 늘리는 것만으로는 불충분하며 [Figure 5], 추가적인 업데이트가 특정 사례에서 커버리지를 향상시킬 수 있지만, 에피소드별 드리프트와 절차적 혼란을 야기할 수 있음을 확인했다. 예를 들어, GPT-5.4는 Curated-Always 조건에서 ESR이 +6.7%p 향상되었지만, 더 큰 라이브러리를 가진 Curated-Always+Tier3 및 SelfGen-Always+Tier3 조건에서는 ESR이 감소했다.
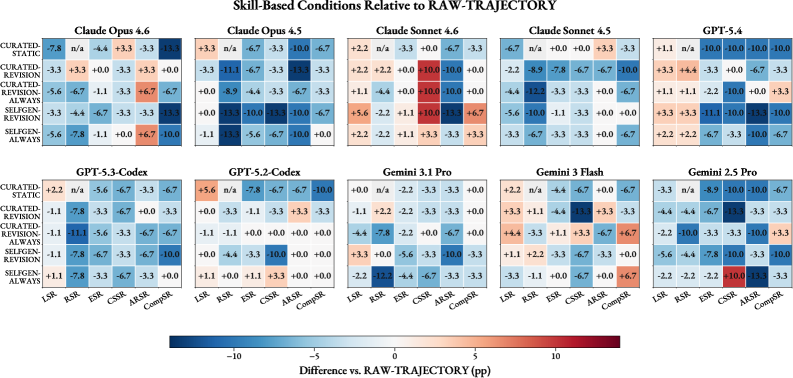
Figure 4 — Raw-Trajectory 대비 Skill 기반 조건
4. Conclusion & Impact (결론 및 시사점)
SkillEvolBench는 에이전트가 일회성 Episodic Experience를 재사용 가능한 Procedural Skills로 전환할 수 있는지 여부를 평가하는 진단 벤치마크를 제공한다. 이 연구의 결과는 현재 LLM Agents가 국소적인 적응은 보이지만, Context Shift, Adversarial Shortcuts, Composition과 같은 다양한 배포 조건에서 안정적으로 전이되는 견고한 Procedural Skills를 형성하는 데는 어려움을 겪는다는 것을 명확히 보여준다. 특히, Raw-Trajectory의 성능이 증류된 Skill보다 우수하다는 점은 Lossy Abstraction Bottleneck의 존재를 강조하며, Skill 추상화 과정에서 중요한 정보가 손실될 수 있음을 시사한다. 이 연구는 단지 더 많은 경험을 저장하거나 Skill을 더 자주 수정하거나 더 큰 리소스 라이브러리를 제공하는 것만으로는 충분하지 않으며, 미래의 호출, 검증, 견고성 및 구성에 필요한 세부 사항을 보존하면서 국소적인 수정과 에피소드별 노이즈를 필터링하는 Selective Procedural Abstraction이 핵심 과제임을 강조한다. SkillEvolBench는 에이전트가 일회성 작업 경험을 배포 변화(deployment shift) 하에서 내구성 있는 절차적 지식으로 발전시키는 단계에서 진행 상황을 측정하는 중요한 테스트베드가 될 것이다.
⚠️ 알림: 이 리뷰는 AI로 작성되었습니다.
관련 포스트
- [논문리뷰] SubtleMemory: A Benchmark for Fine-Grained Relational Memory Discrimination in Long-Horizon AI Agents
- [논문리뷰] OpenSkill: Open-World Self-Evolution for LLM Agents
- [논문리뷰] MCP-Persona: Benchmarking LLM Agents on Real-World Personal Applications via Environment Simulation
- [논문리뷰] OpenSkillEval: Automatically Auditing the Open Skill Ecosystem for LLM Agents
- [논문리뷰] SkillGrad: Optimizing Agent Skills Like Gradient Descent
Review 의 다른글
- 이전글 [논문리뷰] QUEST: Training Frontier Deep Research Agents with Fully Synthetic Tasks
- 현재글 : [논문리뷰] SkillEvolBench: Benchmarking the Evolution from Episodic Experience to Procedural Skills
- 다음글 [논문리뷰] ThriftAttention: Selective Mixed Precision for Long-Context FP4 Attention
댓글