[논문리뷰] QUEST: Training Frontier Deep Research Agents with Fully Synthetic Tasks
링크: 논문 PDF로 바로 열기
저자: Jian Xie, Tianhe Lin, Zilu Wang, Yuting Ning, Yuekun Yao, Tianci Xue, Zhehao Zhang, Zhongyang Li, Kai Zhang, Yufan Wu, Shijie Chen, Boyu Gou, Mingzhe Han, Yifei Wang, Vint Lee, Xinpeng Wei, Xiangjun Wang, Yu Su, Huan Sun
Part 1: 요약 본문
## 1. Key Terms & Definitions (핵심 용어 및 정의)
- Deep Research Agents: 복잡한 정보 탐색 작업을 분해하고, 웹 질의를 실행하며, 외부 소스를 검토하고, 인용 기반 응답을 합성할 수 있는 자율 에이전트.
- Rubric Tree: 유효한 답변이 충족해야 하는 제약 조건을 계층적으로 분해한 구조로, QUEST의 데이터 합성 파이프라인의 핵심 요소. 각 노드는 태스크별 기준을 나타내며, 자동으로 검증 가능한 점수를 제공.
- Context Management: 장기 추론 및 지식 합성을 위해 에이전트의 대화 이력을 Context Condenser를 통해 Context State (JSON 객체)로 압축하는 전략. Trusted, Untrusted, Uncertain 세 가지 버킷으로 지식을 구성.
- Mid-Training (MT): SFT 및 RL에 앞서 모델에 긴 컨텍스트 이해 및 Context State 구조 인식을 학습시키는 보조 훈련 단계.
- Supervised Fine-Tuning (SFT): 수집된 에이전트 궤적을 사용하여 모델이 고품질 도구 사용 패턴을 모방하도록 훈련하는 단계.
- Reinforcement Learning (RL): Rubric-tree Rewards와 Fact-checking Rewards를 결합한 보상 함수를 사용하여 에이전트 정책을 최적화하는 단계.
## 2. Motivation & Problem Statement (연구 배경 및 문제 정의)
본 논문은 Deep Research Agents의 광범위한 역량을 갖춘 훈련 방식의 불투명성과 기존 Open-weight 모델들의 한계점을 해결하고자 한다. 기존 검색 엔진과 RAG 시스템은 웹 페이지 검색 및 문서 기반 응답에 초점을 맞추지만, Deep Research Agents는 복잡한 정보 탐색 작업을 자율적으로 수행하고 합성된 지식을 제공해야 한다. 그러나 최신 Deep Research 시스템은 대부분 독점 모델과 데이터에 의존하며, 기존 Open-weight 에이전트들은 다양한 태스크 유형에 걸쳐 일반화 능력이 부족하다는 문제에 직면해 있다. 특히, Fact Seeking, Citation Grounding, Report Synthesis라는 세 가지 핵심 역량을 통합적으로 다루는 프레임워크가 부재했다 [Figure 2]. 이러한 한계로 인해 범용 Deep Research Agent를 효과적으로 훈련하는 방법에 대한 이해가 부족했다.
## 3. Method & Key Results (제안 방법론 및 핵심 결과)
저자들은 Mid-training (MT), Supervised Fine-tuning (SFT), 그리고 Reinforcement Learning (RL)을 결합한 효과적인 훈련 레시피와 새로운 데이터 합성 파이프라인, 그리고 컨텍스트 관리 전략을 제안한다. 핵심은 Unified Rubric Tree 기반의 데이터 합성 파이프라인으로, 인간 주석 없이 검증 가능한 보상과 다양한 태스크 유형에 적용 가능한 훈련 데이터를 생성한다 [Figure 3]. Context Management 메커니즘은 장기 추론을 위해 정보를 Context Condenser를 통해 Context State로 압축하여 컨텍스트 오버플로우 없이 효과적인 지식 합성을 가능하게 한다 [Figure 4]. Qwen3.5-35B-A3B를 기본 모델로 사용하고, 8K개의 합성된 태스크로 SFT 및 RL 훈련을 진행했다.
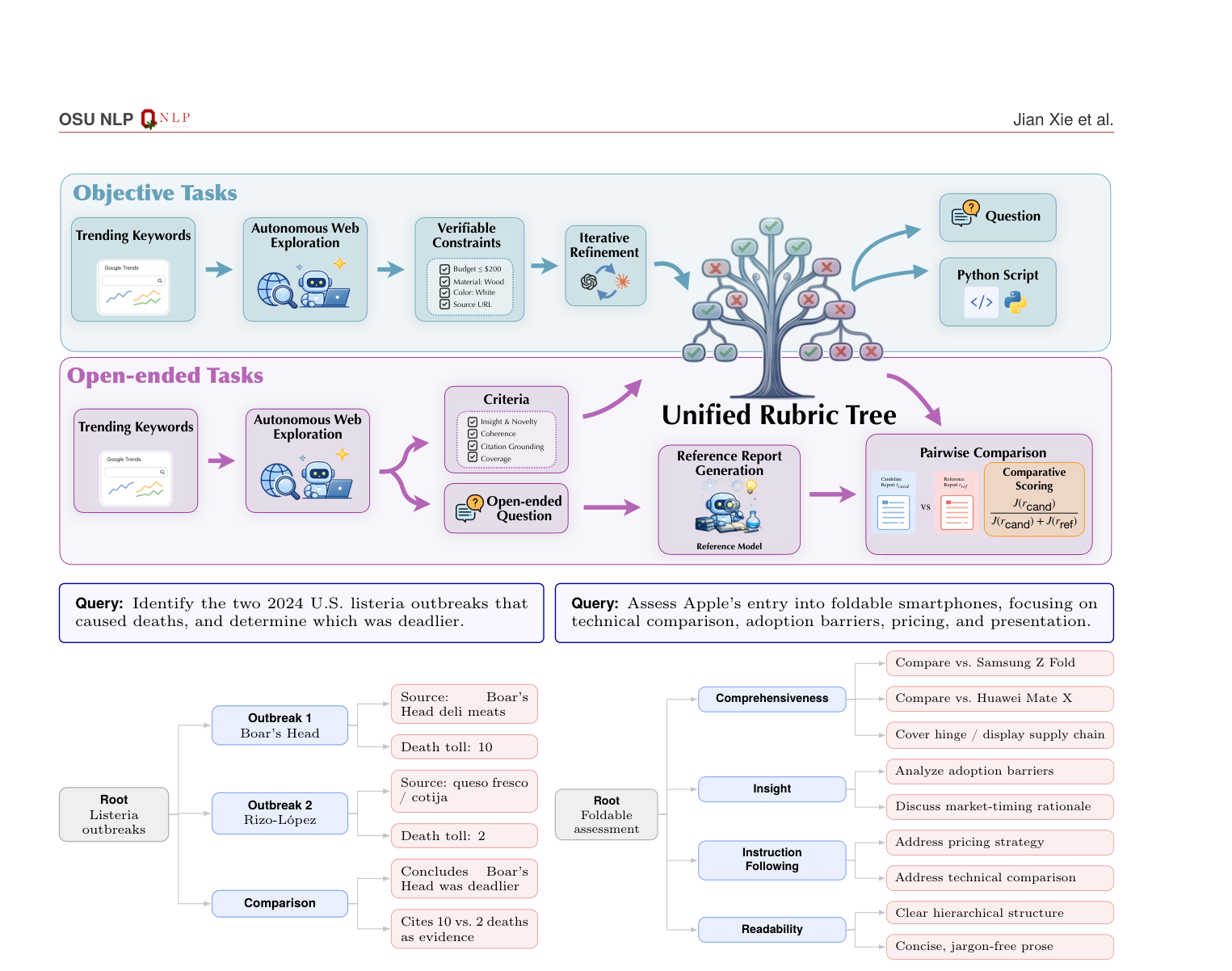
Figure 3 — QUEST의 핵심 데이터 합성 파이프라인과 루브릭 트리 구조를 설명하는 다이어그램

Figure 4 — 에이전트의 장기 추론을 가능하게 하는 컨텍스트 관리 메커니즘을 시각화
실험 결과, QUEST-35B는 8가지 Deep Research 벤치마크에서 기존 Open-weight 에이전트 중 최고 성능을 달성했으며, 일부 벤치마크에서는 Frontier Closed-source 에이전트에 근접하거나 능가했다 [Table 3]. 예를 들어, DeepResearch Bench에서 48.2% (OpenAI-DR 대비 47.0%), Mind2Web 2에서 30.7% (OpenAI-DR 대비 28.0%), GAIA에서 80.8% (GPT-5 대비 76.4%)의 성능을 기록했다. 이러한 결과는 Open-weight와 Proprietary 시스템 간의 성능 격차를 크게 줄였다. 또한, MT+SFT+RL 전체 훈련 레시피가 가장 우수한 성능을 보였으며, 2B 모델과 같은 소형 LLM도 HLE 및 GAIA와 같은 Fact Seeking 벤치마크에서 경쟁력 있는 성능을 보였다.

Table 3 — QUEST-35B와 다른 연구 에이전트들의 8가지 벤치마크 성능을 비교한 핵심 결과표
## 4. Conclusion & Impact (결론 및 시사점)
본 논문은 Fact Seeking, Citation Grounding, Report Synthesis 등 장기적인 태스크를 해결할 수 있는 범용 Deep Research Agent인 QUEST를 제안한다. QUEST-35B 모델은 8가지 벤치마크에서 Open-weight 에이전트 중 최고의 성능을 달성하고, Frontier Closed-source 에이전트의 성능에 근접함으로써 Deep Research Agents의 성능 격차를 줄였다. Rubric-tree 기반 데이터 합성, 구조화된 Context Management, 효율적인 훈련 인프라, 그리고 Mid-training, SFT, RL을 결합한 다단계 훈련 파이프라인은 이 분야의 발전에 강력한 토대를 제공한다. 이 연구는 Compute-constrained 시나리오나 개인 정보 보호가 중요한 도메인에서 소형 LLM 기반 에이전트 배포 가능성을 시사하며, Deep Research Agents 연구의 투명성과 재현성을 높이는 데 기여한다.
⚠️ 알림: 이 리뷰는 AI로 작성되었습니다.
관련 포스트
- [논문리뷰] Tongyi DeepResearch Technical Report
- [논문리뷰] Combinatorial Synthesis: Scaling Code RLVR via Atomic Decomposition and Recombination
- [논문리뷰] DR-Venus: Towards Frontier Edge-Scale Deep Research Agents with Only 10K Open Data
- [논문리뷰] MM-Zero: Self-Evolving Multi-Model Vision Language Models From Zero Data
- [논문리뷰] InftyThink+: Effective and Efficient Infinite-Horizon Reasoning via Reinforcement Learning
Review 의 다른글
- 이전글 [논문리뷰] ParaVT: Taming the Tool Prior Paradox for Parallel Tool Use in Agentic Video Reinforcement Learning
- 현재글 : [논문리뷰] QUEST: Training Frontier Deep Research Agents with Fully Synthetic Tasks
- 다음글 [논문리뷰] SkillEvolBench: Benchmarking the Evolution from Episodic Experience to Procedural Skills
댓글