[논문리뷰] OpenSkill: Open-World Self-Evolution for LLM Agents
링크: 논문 PDF로 바로 열기
메타데이터
저자: Zhiling Yan, Dingjie Song, Hanrong Zhang, Wei Liang, Yuxuan Zhang, Yutong Dai, Lifang He, Philip S. Yu, Ran Xu, Xiang Li, Lichao Sun
1. Key Terms & Definitions (핵심 용어 및 정의)
- Open-World Self-Evolution: 타겟 태스크에 대한 명시적인 지도(supervision) 없이, 오직 태스크 프롬프트와 외부 리소스만을 활용하여 에이전트의 기술(skill)과 검증 체계(verification signal)를 스스로 구축 및 진화시키는 과정입니다.
- Open-World Knowledge Acquisition: 모델의 파라미터 내 지식에만 의존하지 않고, 외부 문서, 코드 저장소, 웹 등에서 도메인 지식과 검증용 앵커(anchor)를 직접 습득하는 단계입니다.
- Virtual Verifier: 타겟 태스크의 정답(ground-truth)에 의존하지 않고, 수집된 검증 지식을 바탕으로 자가 생성한 가상 테스트 스위트를 통해 에이전트의 기술을 평가하고 피드백을 제공하는 구성 요소입니다.
- Leakage-Free Skill Evolution: 외부 리소스 탐색 및 기술 정제 과정에서 타겟 태스크의 정답 정보가 유출되지 않도록 차단하는 설계 원칙으로, 오직 최종 평가 단계에서만 지도를 활용합니다.
2. Motivation & Problem Statement (연구 배경 및 문제 정의)
본 논문은 LLM 에이전트가 배포 후 외부의 정답이나 지도 없이 스스로 학습할 수 있는 'Open-World Self-Evolution' 환경에서의 불확실성을 해결하고자 합니다 [Figure 1]. 기존의 자가 진화 연구들은 사람의 지도가 있거나, 성공적인 실행 궤적(trajectories) 및 신뢰할 수 있는 피드백 루프가 이미 존재하는 폐쇄적인 환경을 가정합니다. 하지만 실제 오픈 월드에서는 이러한 자원들이 제공되지 않으며, 에이전트는 지식 습득과 동시에 그 지식을 평가할 검증 체계까지 제로 베이스에서 스스로 구축해야 하는 한계가 있습니다. 이러한 문제를 해결하기 위해 저자들은 외부 환경에서 학습 동력을 얻고 타겟 지도 없이도 스스로 진화할 수 있는 OpenSkill 프레임워크를 제안합니다.
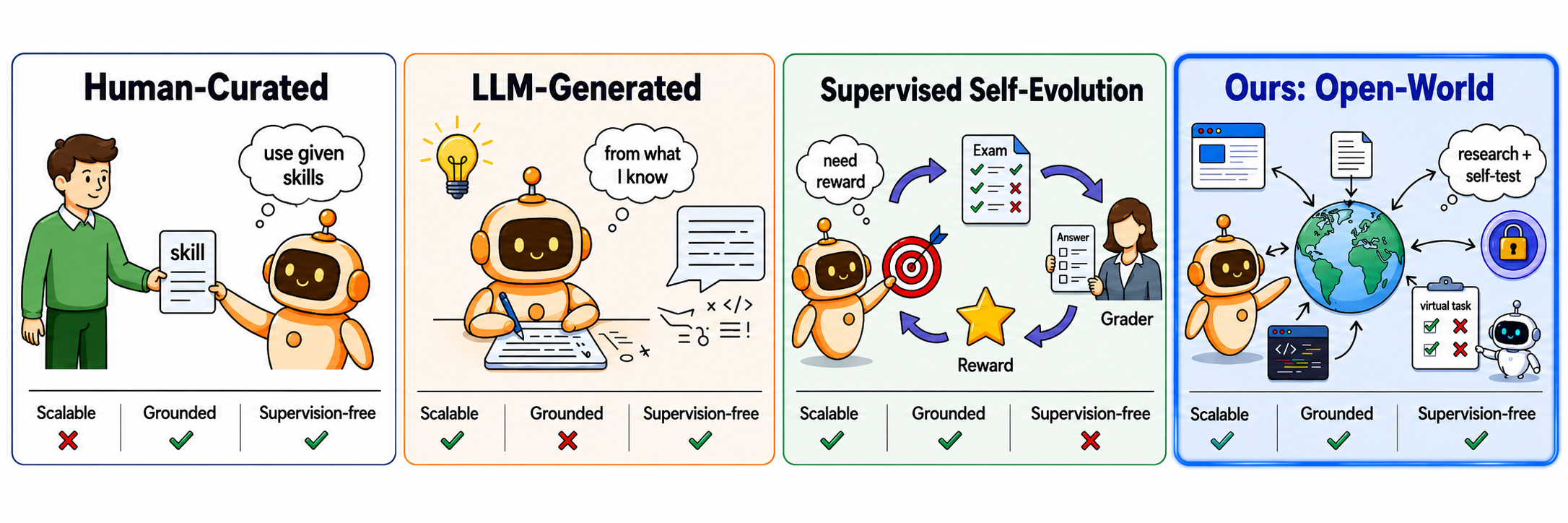
Figure 1 — 자가 진화 에이전트 패러다임 비교
3. Method & Key Results (제안 방법론 및 핵심 결과)
OpenSkill은 크게 세 단계인 지식 습득, 기술 정제, 제로샷 평가로 구성됩니다 [Figure 2]. 첫째, Open-World Knowledge Acquisition을 통해 작업과 관련된 도메인 지식과 검증을 위한 앵커를 수집합니다. 둘째, Leakage-Free Skill Evolution 단계에서는 수집된 지식으로 기술을 구축하고, 타겟 정답 대신 자체 생성한 가상 테스트를 통해 반복적으로 기술을 개선합니다. 마지막으로, 생성된 기술은 모델 웨이트를 수정하지 않는 명시적 아티팩트(artifact)로 저장되어 타겟 에이전트에 제로샷으로 배포됩니다. 실험 결과, OpenSkill은 SkillsBench에서 기존 자동화 베이스라인 대비 Opus 4.6 모델에서 +8.9%, GPT 5.2 모델에서 +8.8%의 성능 향상을 기록하며 가장 높은 자동화 패스율을 달성했습니다. 또한, 본 연구의 기술은 특정 모델에 종속되지 않고 다른 모델로 전이 가능한 특성을 보이며, 구축된 Virtual Verifier는 인간이 작성한 테스트 의도의 88.9%를 커버할 정도로 높은 정합성을 보였습니다 [Table 1, Table 2, Figure 3].
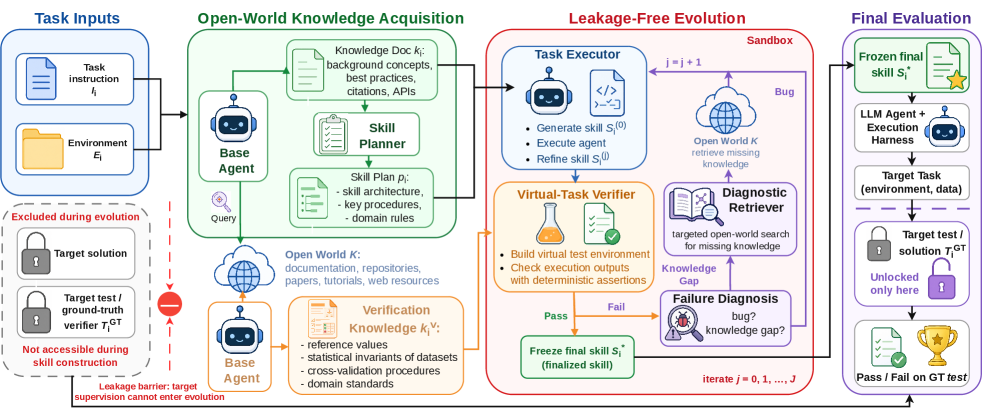
Figure 2 — OpenSkill 프레임워크 전체 구조
4. Conclusion & Impact (결론 및 시사점)
본 논문은 LLM 에이전트가 외부 정답 없이도 오픈 월드에서 스스로 필요한 기술을 습득하고 검증할 수 있음을 입증했습니다. OpenSkill은 지식 습득, 기술 진화, 성능 검증이라는 복합적인 루프를 완전히 자동화함으로써 기존 폐쇄형 모델의 한계를 극복했습니다. 본 연구는 에이전트의 범용적인 학습 방식에 대한 새로운 패러다임을 제시하며, 특히 모델 비의존적인 아티팩트 형태의 기술 전이 능력을 통해 향후 대규모 에이전트 시스템의 유지보수와 성능 향상에 크게 기여할 것으로 기대됩니다.

Figure 3 — 모델 간 기술 전이 성능 비교
⚠️ 알림: 이 리뷰는 AI로 작성되었습니다.
관련 포스트
- [논문리뷰] SkillGrad: Optimizing Agent Skills Like Gradient Descent
- [논문리뷰] SkillEvolBench: Benchmarking the Evolution from Episodic Experience to Procedural Skills
- [논문리뷰] SkillsVote: Lifecycle Governance of Agent Skills from Collection, Recommendation to Evolution
- [논문리뷰] SkillClaw: Let Skills Evolve Collectively with Agentic Evolver
- [논문리뷰] Trace2Skill: Distill Trajectory-Local Lessons into Transferable Agent Skills
Review 의 다른글
- 이전글 [논문리뷰] Measuring Model Robustness via Fisher Information: Spectral Bounds, Theoretical Guarantees, and Practical Algorithms
- 현재글 : [논문리뷰] OpenSkill: Open-World Self-Evolution for LLM Agents
- 다음글 [논문리뷰] PaperFlow: Profiling, Recommending, and Adapting Across Daily Paper Streams
댓글