[논문리뷰] MCP-Persona: Benchmarking LLM Agents on Real-World Personal Applications via Environment Simulation
링크: 논문 PDF로 바로 열기
메타데이터
저자: Wenhao Wang, Peizhi Niu, Gongyi Zou, et al.
1. Key Terms & Definitions (핵심 용어 및 정의)
- Model Context Protocol (MCP): LLM과 외부 데이터 소스 및 도구를 연결하기 위한 표준 프로토콜로, 본 논문에서는 개인화된 앱 통합의 핵심 인프라로 사용됨.
- Tool-Traverse: 실제 MCP 서버의 행동 방식을 파악하기 위해 authentic function calls를 탐색하고, 이를 기반으로 실행 가능한 시뮬레이터를 구축하는 파라다임.
- Context-Tree: 개인화된 사용자 컨텍스트(사용자 프로필, 계정 데이터 등)를 트리 계층 구조로 구조화하여 상태 유지가 필요한 도구 실행을 지원하는 방법론.
- Persona-Gen: Tool invocation chain을 활용해 사용자 의도를 합성하고, 실제 사용자가 입력하는 것처럼 모호한 지시사항으로 변환(fuzzification)하는 데이터 생성 파이프라인.
2. Motivation & Problem Statement (연구 배경 및 문제 정의)
본 논문은 기존의 에이전트 벤치마크가 범용 도구 사용에만 집중되어 있어, 실제 사용자의 계정 및 로컬 데이터와 밀접하게 연동되는 개인화된 앱에서의 성능을 평가하지 못하는 문제를 해결하고자 한다. 기존 연구들은 대규모 환경 구축의 어려움, 개인 정보 보호 문제, 그리고 복잡한 상태 관리가 필요한 실제 환경의 재현 불가능성으로 인해 실질적인 개인화 시나리오를 다루는 데 한계가 있었다 [Figure 1]. 이러한 제약은 특히 소셜 미디어 플랫폼이나 기업 협업 툴과 같이 사용자의 맥락이 깊게 투영된 환경에서 LLM 에이전트의 실질적인 활용을 저해하는 요인이 된다. 따라서 저자들은 실제와 유사한 환경을 재현하면서도 개인정보를 보호할 수 있는 새로운 평가 플랫폼인 MCP-Persona를 제안한다.
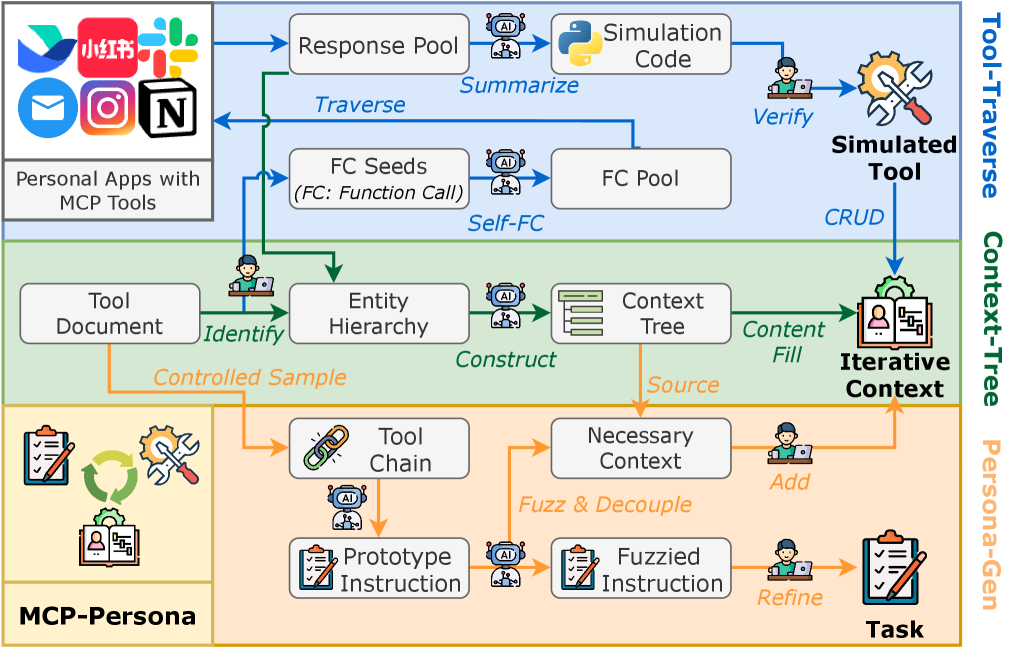
Figure 1 — MCP-Persona 시스템 개요
3. Method & Key Results (제안 방법론 및 핵심 결과)
본 논문은 실제와 유사한 환경 시뮬레이션을 위해 세 가지 핵심 모듈인 Tool-Traverse, Context-Tree, Persona-Gen을 제안한다. Tool-Traverse는 실제 서버로부터 수집한 기능 호출 데이터를 기반으로 LLM을 활용해 실행 가능한 파이썬 시뮬레이터를 자동으로 생성하며, 이를 통해 고충실도(high-fidelity)의 도구 시뮬레이션을 달성한다. Context-Tree는 사용자의 개인적 맥락을 트리 구조로 조직화하여 도구 호출 시 상태 기반(stateful)의 일관된 데이터 조작을 가능하게 한다 [Figure 2]. Persona-Gen은 정의된 환경 위에서 도구 호출 체인을 샘플링하고 지시사항을 의도적으로 모호하게 만드는 fuzzification 과정을 거쳐 173개의 고품질 개인화 태스크를 구축하였다. 실험 결과, GPT-5와 같은 SOTA 모델들조차 개인화된 환경 내에 숨겨진 정보를 제대로 탐색하지 못하고, 도구 활용의 복잡성에 대응하는 데 어려움을 겪는 것으로 나타났다. 특히, 시뮬레이션 방식은 기존 방식 대비 적은 비용으로도 실제 환경과 매우 유사한 도구 행동을 복제할 수 있음을 입증하였으며, 이는 에이전트의 개인화 성능 격차를 식별하는 데 결정적인 지표로 활용될 수 있다.
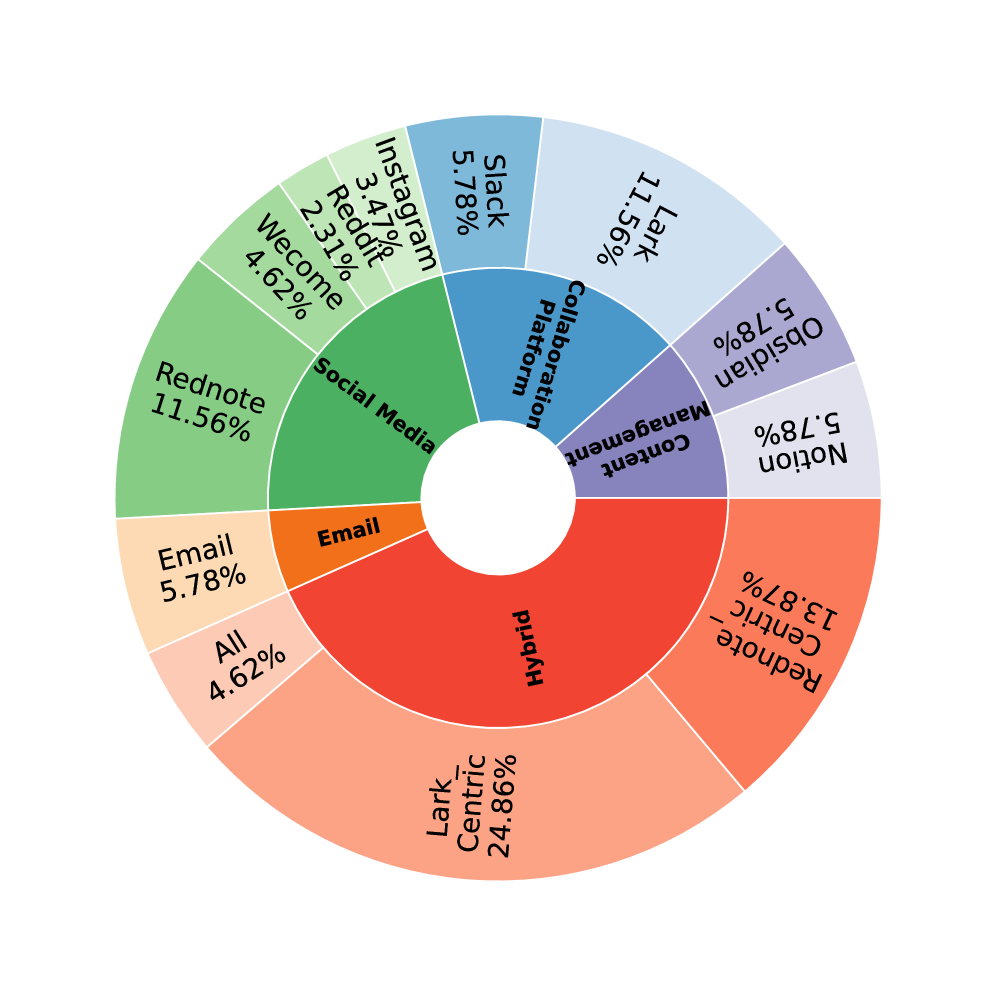
Figure 2 — 데이터셋 및 도구 통계
4. Conclusion & Impact (결론 및 시사점)
본 논문은 실세계 개인화 애플리케이션을 대상으로 하는 최초의 LLM 에이전트 벤치마크인 MCP-Persona를 통해 에이전트의 현실적 성능 평가를 위한 새로운 이정표를 제시하였다. 제안된 환경 시뮬레이션 방식은 프라이버시 문제 없이도 복잡한 개인화 앱 환경을 효과적으로 모사하여 학계와 산업계가 보다 안전하고 신뢰성 있는 도구 활용형 에이전트를 개발할 수 있도록 지원한다. 이 연구는 향후 개인화 에이전트 생태계의 발전 방향을 명확히 하고, LLM이 복잡한 사용자 컨텍스트를 얼마나 잘 이해하고 활용하는지를 정량적으로 평가할 수 있는 기반 기술로서 중요한 가치를 지닌다.
⚠️ 알림: 이 리뷰는 AI로 작성되었습니다.
관련 포스트
- [논문리뷰] FinMCP-Bench: Benchmarking LLM Agents for Real-World Financial Tool Use under the Model Context Protocol
- [논문리뷰] SubtleMemory: A Benchmark for Fine-Grained Relational Memory Discrimination in Long-Horizon AI Agents
- [논문리뷰] OpenSkillEval: Automatically Auditing the Open Skill Ecosystem for LLM Agents
- [논문리뷰] SkillEvolBench: Benchmarking the Evolution from Episodic Experience to Procedural Skills
- [논문리뷰] How Well Do Agentic Skills Work in the Wild: Benchmarking LLM Skill Usage in Realistic Settings
Review 의 다른글
- 이전글 [논문리뷰] LongLive-RAG: A General Retrieval-Augmented Framework for Long Video Generation
- 현재글 : [논문리뷰] MCP-Persona: Benchmarking LLM Agents on Real-World Personal Applications via Environment Simulation
- 다음글 [논문리뷰] Masking Stale Observations Helps Search Agents -- Until It Doesn't: A Regime Map and Its Mechanism
댓글