[논문리뷰] Humanoid-GPT: Scaling Data and Structure for Zero-Shot Motion Tracking
링크: 논문 PDF로 바로 열기
메타데이터
저자: Zekun Qi, Xuchuan Chen, Dairu Liu, et al.
1. Key Terms & Definitions (핵심 용어 및 정의)
- HME (Harmonic Motion Embedding): 모션 데이터의 다양성을 정량화하고 이를 클러스터링하기 위해 사용되는 표현 학습 도구로, 관절별 주기적 진폭과 주파수를 기반으로 추출된 임베딩입니다.
- DAgger Distillation: 다양한 동작을 학습한 여러 전문가 정책(RL-based motion experts)을 하나의 범용 Transformer 모델로 통합하기 위해 사용된 학습 프레임워크입니다.
- Causal Attention: Transformer 모델에서 미래 정보를 참조하지 않고 과거 및 현재의 토큰 정보를 기반으로 미래 동작을 예측하도록 설계된 메커니즘입니다.
- Zero-Shot Generalization: 학습 단계에서 접해보지 않은 새로운 동작이나 제어 환경에 대해 별도의 추가 학습(fine-tuning) 없이 즉각적인 추적 성능을 발휘하는 능력입니다.
2. Motivation & Problem Statement (연구 배경 및 문제 정의)
본 논문은 기존 휴머노이드 모션 트래킹 연구가 겪고 있는 데이터 및 모델 규모의 한계와 그로 인한 일반화 성능 저하 문제를 해결하고자 합니다. 기존의 연구들은 주로 소규모 MLP 기반 정책에 의존해왔으며, 이는 정교한 모션 추적과 범용적인 일반화 사이의 고질적인 트레이드오프(trade-off)를 유발했습니다 [Figure 1]. 저자들은 단순히 데이터를 추가하는 것만으로는 부족하며, 대규모 데이터를 효율적으로 처리할 수 있는 구조와 학습 방식이 필요하다고 주장합니다. 이를 위해 본 연구에서는 2B-frame 규모의 대규모 모션 코퍼스를 구축하고, 이를 기반으로 Transformer 아키텍처를 도입하여 스케일링 법칙(scaling law)에 따른 성능 향상을 체계적으로 증명합니다.
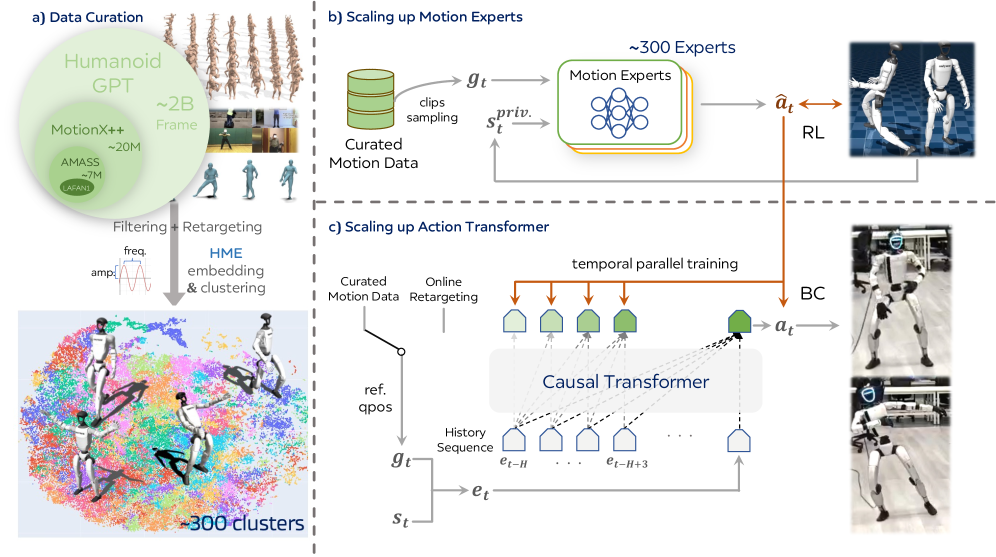
Figure 1 — Humanoid-GPT 전체 파이프라인
3. Method & Key Results (제안 방법론 및 핵심 결과)
본 논문은 Humanoid-GPT라 명명된 범용 온라인 휴머노이드 모션 트래커를 제안하며, 크게 세 단계의 파이프라인을 따릅니다. 첫째, 다양한 소스의 모션 데이터를 통합하고 HME를 통해 클러스터링하여 물리적으로 일관된 모션 데이터를 확보합니다. 둘째, 각 클러스터별로 PPO 기반의 전문가 정책을 학습시켜 개별 모션 도메인에 특화된 전문가들을 생성합니다. 셋째, 이 전문가들의 지식을 DAgger 기법을 통해 하나의 Transformer 모델로 증류(distillation)하여, 추론 시 인과적 주의(causal attention)를 기반으로 고정밀 제어 토큰을 생성합니다 [Figure 1].
성능 평가 결과, Humanoid-GPT-L은 기존 MLP 및 TCN 기반 모델 대비 압도적인 성능 우위를 점했습니다. 특히 2B 토큰 학습 조건에서 SR(Success Rate) 은 92.58% 를 기록하였으며, MPKPE(Mean per-Keypoint Position Error) 지표에서도 최신 베이스라인 대비 약 30% 이상 향상된 정밀도를 보였습니다 [Table 2]. 실환경 실험에서도 사전 학습되지 않은 춤 동작들을 Zero-shot으로 추적하며 높은 안정성과 실시간성을 입증했습니다 [Figure 3].

Figure 3 — 실제 로봇 환경 제로샷 검증
4. Conclusion & Impact (결론 및 시사점)
본 연구는 대규모 데이터와 Transformer 구조를 결합함으로써 휴머노이드 로봇의 전신 제어(whole-body control)에 새로운 성능 기준을 제시했습니다. 제안된 Humanoid-GPT는 모델 크기와 데이터 규모가 커짐에 따라 예측 가능한 성능 향상을 보여주며, 휴머노이드 트래킹 분야의 스케일링 법칙을 최초로 체계화했습니다. 이 연구는 향후 범용 로봇(embodied agent) 학습을 위한 기초 모델(foundation model)로서의 가치를 증명하였으며, 복잡한 실세계 환경에서의 로봇 배포를 가속화하는 핵심적인 프레임워크로 기능할 것으로 기대됩니다.

Figure 4 — 인퍼런스 지연 시간 비교
⚠️ 알림: 이 리뷰는 AI로 작성되었습니다.
관련 포스트
- [논문리뷰] LAMIC: Layout-Aware Multi-Image Composition via Scalability of Multimodal Diffusion Transformer
- [논문리뷰] WEAVER, Better, Faster, Longer: An Effective World Model for Robotic Manipulation
- [논문리뷰] MaskAlign: Token-Subset Representation Alignment for Efficient Diffusion Training
- [논문리뷰] CIPER: A Unified Framework for Cross-view Image-retrieval and Pose-estimation
- [논문리뷰] Confidence-Adaptive SwiGLU for Mixture-of-Experts
Review 의 다른글
- 이전글 [논문리뷰] From Activation to Causality: Discovery of Causal Visual Representations in the Human Brain
- 현재글 : [논문리뷰] Humanoid-GPT: Scaling Data and Structure for Zero-Shot Motion Tracking
- 다음글 [논문리뷰] KVarN: Variance-Normalized KV-Cache Quantization Mitigates Error Accumulation in Reasoning Tasks
댓글