[논문리뷰] PaddleOCR-VL-1.6: Expanding the Frontier of Document Parsing with Under-Optimized Region Refinement and Progressive Post-Training
링크: 논문 PDF로 바로 열기
메타데이터
저자: Zelun Zhang, Hongen Liu, Suyin Liang, Yubo Zhang, Yiqing Xiang, Jiaxuan Liu, Ting Sun, Manhui Lin, Yue Zhang, Changda Zhou, Tingquan Gao, Cheng Cui, Yi Liu, Dianhai Yu, Yanjun Ma
1. Key Terms & Definitions (핵심 용어 및 정의)
- PaddleOCR-VL-1.6: 이전 버전인 PaddleOCR-VL-1.5의 성능을 개선한 0.9B 파라미터 규모의 경량화된 Document Parsing 전용 Vision-Language Model입니다.
- Under-Optimized Region (UOR): 모델의 예측이 불안정하거나 데이터 커버리지가 부족하고, supervision 신뢰도가 낮은 데이터 공간상의 특정 영역을 의미합니다.
- GRPO (Group Relative Policy Optimization): RL(Reinforcement Learning) 과정에서 별도의 Value Model 없이 그룹 내 샘플 간의 상대적 보상을 통해 정책을 최적화하는 효율적인 강화학습 기법입니다.
- OmniDocBench v1.6: 본 논문에서 제안한 모델의 성능을 측정하기 위해 사용하는 Document Parsing 전용 벤치마크 데이터셋입니다.
2. Motivation & Problem Statement (연구 배경 및 문제 정의)
본 연구는 고성능 0.9B 파라미터 모델인 PaddleOCR-VL-1.5의 잔여 오류를 해결하여 성능을 극대화하고자 합니다 [Figure 1]. 저자들은 단순히 훈련 데이터를 늘리는 것만으로는 긴 꼬리(long-tail) 분포의 문서 레이아웃, 복잡한 테이블, 희귀 스크립트 등에서 발생하는 오류를 근본적으로 해결할 수 없음을 관찰했습니다. 특히 모델의 학습이 불충분하거나 불안정한 Under-Optimized Region이 존재함에 따라, 무작위 데이터 확장보다는 모델 지향적인 타겟팅 데이터 엔진과 정교한 학습 전략이 필요함을 정의하였습니다.
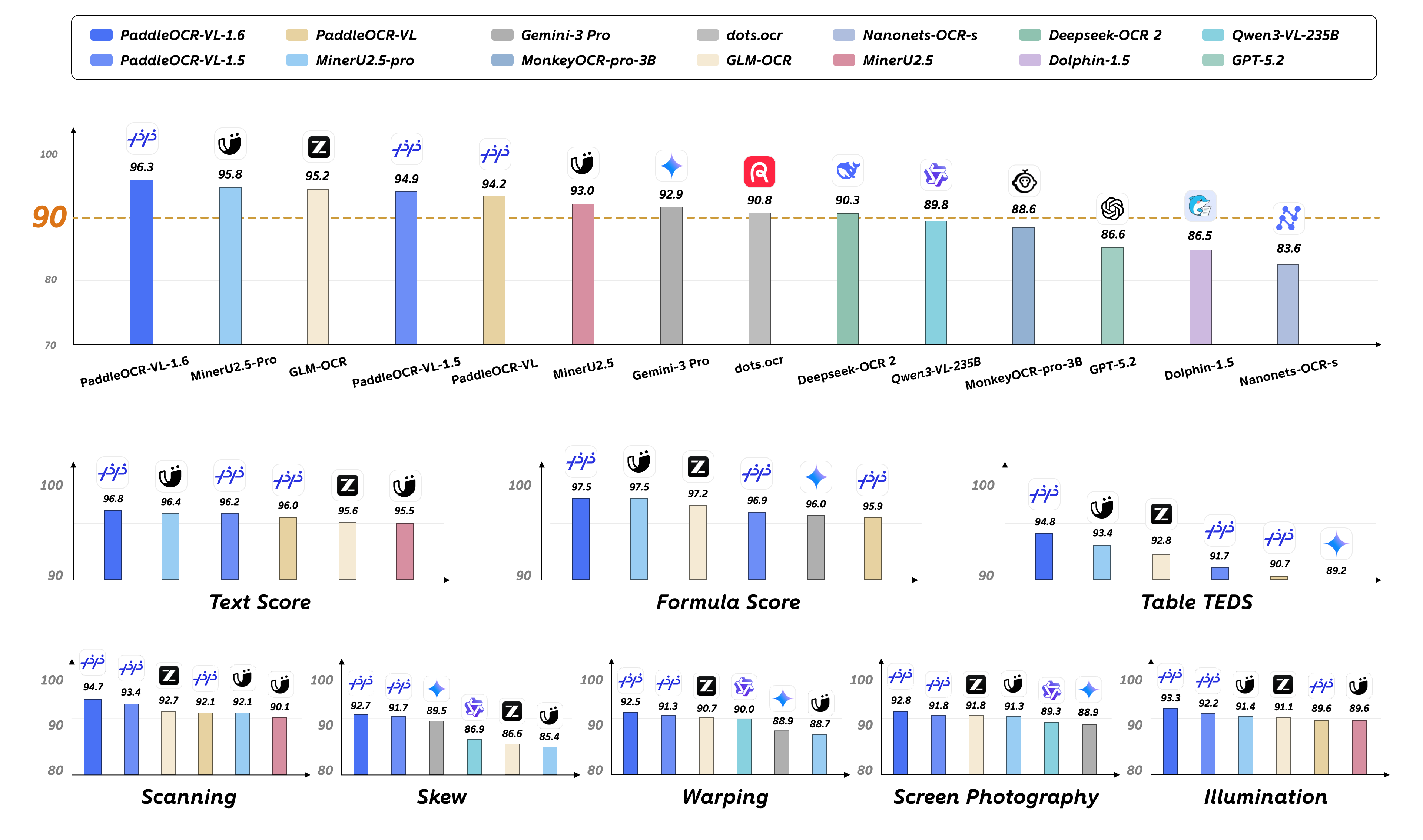
Figure 1 — 모델 성능 비교
3. Method & Key Results (제안 방법론 및 핵심 결과)
본 논문은 Under-Optimized Region을 체계적으로 발굴하고 최적화하는 데이터 엔진과 Progressive Post-Training 파이프라인을 제안합니다 [Figure 2]. 데이터 엔진은 Boundary-Fragile Regions, Coverage-Sparse Regions, Unreliable-Supervision Regions 세 가지 유형을 진단하고, 다중 전문가 합의(Multi-Expert Consensus) 및 렌더링 기반 판단(Render-Guided Refinement)을 통해 고품질의 레이블을 자동으로 생성합니다 [Figure 3]. 이후 단계적 훈련(CPT-SFT-RL)을 통해 모델의 분포 범위를 넓히고 어려운 케이스를 정교화하며, 특히 RL 단계에서는 GRPO를 활용하여 데이터의 개선 잠재력, 불확실성, 보상 분포를 고려한 고가치 샘플 선정 전략을 도입했습니다. 결과적으로 PaddleOCR-VL-1.6은 OmniDocBench v1.6에서 96.33%라는 SOTA 성능을 달성하였으며, 0.9B 수준의 compact한 규모를 유지하면서도 대규모 모델 대비 우수한 경쟁력을 입증했습니다.
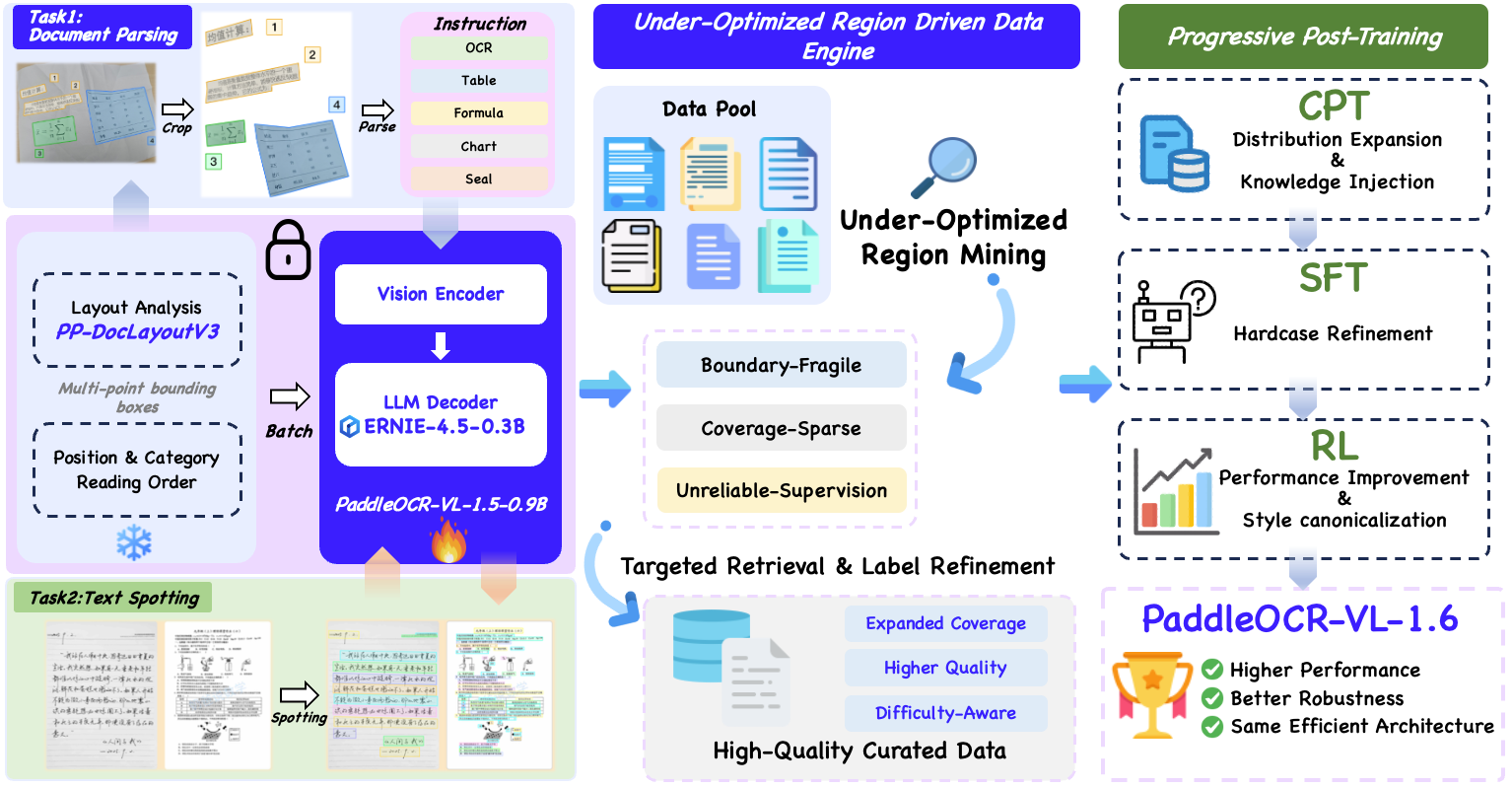
Figure 2 — 전체 아키텍처 개요
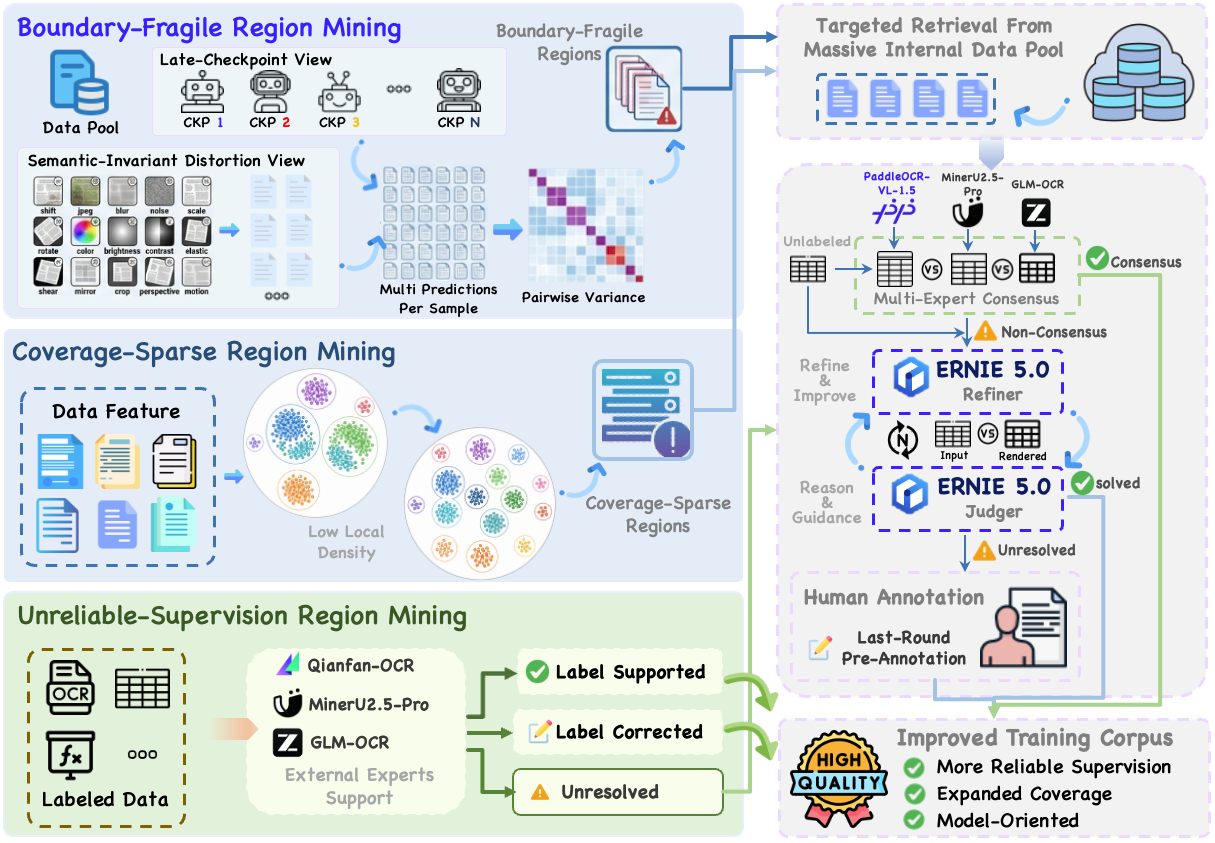
Figure 3 — 데이터 엔진 구조
4. Conclusion & Impact (결론 및 시사점)
본 논문은 경량화된 Vision-Language Model이 모델 지향적인 데이터 최적화와 단계적 강화학습을 통해 성능의 한계를 극복할 수 있음을 입증했습니다. 특히 제안된 UOR 기반의 데이터 엔진은 고비용의 수동 레이블링을 최소화하면서도 모델의 특정 취약점을 효과적으로 보완할 수 있는 실용적인 프레임워크를 제공합니다. 이 연구는 리소스 제약이 있는 환경에서 Document Parsing 모델을 구축하려는 학계 및 산업계에 고성능 배포를 위한 효율적인 post-training 레시피를 제시했다는 점에서 중요한 시사점을 가집니다.
⚠️ 알림: 이 리뷰는 AI로 작성되었습니다.
관련 포스트
- [논문리뷰] MinerU2.5-Pro: Pushing the Limits of Data-Centric Document Parsing at Scale
- [논문리뷰] MinerU2.5: A Decoupled Vision-Language Model for Efficient High-Resolution Document Parsing
- [논문리뷰] NVIDIA Nemotron Parse 1.1
- [논문리뷰] PaddleOCR-VL: Boosting Multilingual Document Parsing via a 0.9B Ultra-Compact Vision-Language Model
- [논문리뷰] N-GRPO: Embedding-Level Neighbor Mixing for Enhanced Policy Optimization
Review 의 다른글
- 이전글 [논문리뷰] OCC-RAG: Optimal Cognitive Core for Faithful Question Answering
- 현재글 : [논문리뷰] PaddleOCR-VL-1.6: Expanding the Frontier of Document Parsing with Under-Optimized Region Refinement and Progressive Post-Training
- 다음글 [논문리뷰] PlatonicNav: Unveiling Semantic Correspondence in Navigation with Platonic Topological Maps
댓글