[논문리뷰] PlatonicNav: Unveiling Semantic Correspondence in Navigation with Platonic Topological Maps
링크: 논문 PDF로 바로 열기
메타데이터
저자: Junlin Long, Zeyu Zhang, Xu Deng, Yiran Wang, Yue Yang, Luke Borgnolo, Maxwell Twelftree, Yang Zhao
1. Key Terms & Definitions (핵심 용어 및 정의)
- Platonic Representation Hypothesis: 서로 다른 modality(Vision, Language)로 학습된 독립적인 인코더가 학습 데이터의 공유 없이도 공통의 통계적 현실 모델(Semantic Manifold)로 수렴한다는 가설.
- Platonic Topological Map: 물리적 공간의 기하학적 정보뿐만 아니라, DINOv3 등으로부터 도출된 의미적 거리(Platonic distance)를 노드 간 가중치로 결합하여 표현한 객체 중심의 그래프 구조.
- Blind Matching: Paird data 없이 두 인코더의 쌍대 관계(Pairwise relation)만을 활용하여, 서로 다른 임베딩 공간에 있는 Vision-Language 간의 대응 관계를 추론하는 기법.
- ObjNav / VLN: Embodied AI 분야의 핵심 과제로, 각각 객체 범주 기반의 목표 탐색과 자연어 명령에 따른 에이전트의 이동 경로 탐색을 지칭.
2. Motivation & Problem Statement (연구 배경 및 문제 정의)
본 논문은 기존의 Embodied Navigation 연구들이 Vision-Language Navigation (VLN)과 Object Goal Navigation (ObjNav)을 분리된 문제로 다루며, 이들 사이의 연계를 위해 과도한 Cross-modal 학습이나 대규모 VLM 모델에 의존하고 있다는 점을 문제로 지적한다 [Figure 1]. 저자들은 독립적으로 학습된 Vision 및 Language 인코더가 이미 공유된 의미적 구조를 내재하고 있다는 가설을 세우고, 이를 활용하여 학습 데이터의 쌍(Paird data) 없이도 범용적인 네비게이션이 가능한지를 탐구하고자 한다. 기존의 방식은 고비용의 Cross-modal 지도 학습이 필수적이었으나, 본 연구는 이를 기하학적·의미적 공통 기반인 Platonic Topological Map으로 대체하고자 한다 [Figure 3].
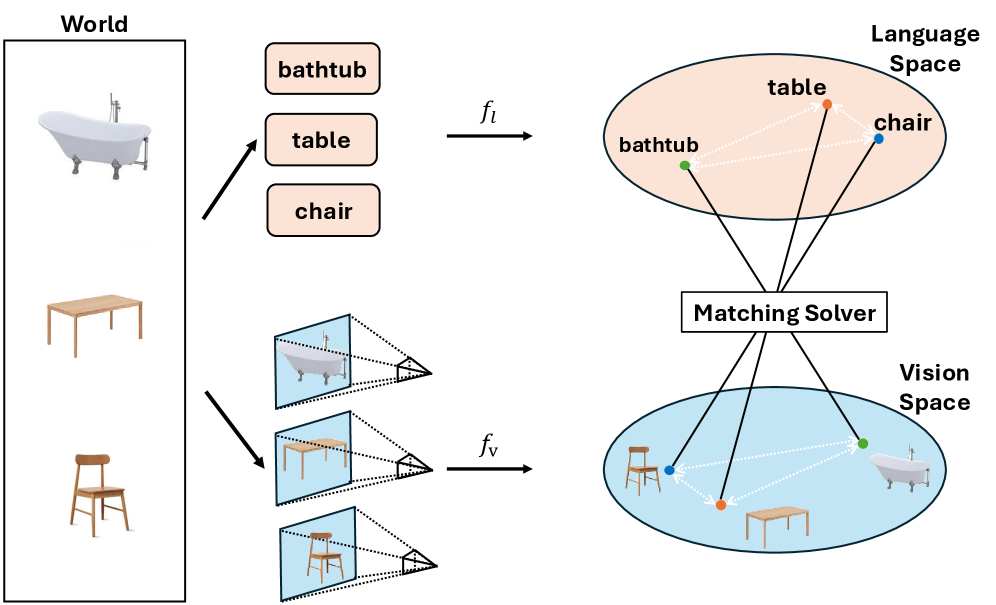
Figure 1 — Vision-Language의 blind matching 개념
Figure 3 — 네비게이션 궤적 비교
3. Method & Key Results (제안 방법론 및 핵심 결과)
본 논문은 Platonic Representation Hypothesis를 Embodied Navigation에 확장하여 적용한 PlatonicNav를 제안한다 [Figure 2]. 이 방법론은 객체 중심의 topological map을 구성할 때, 물리적 거리(Geometric distance)와 비전 인코더의 임베딩 간 의미적 거리(Platonic distance)를 convex combination으로 결합한 하이브리드 가중치를 사용한다. 또한, 언어 목표(Language goal)는 blind matching 기법을 통해 visual segment와 매칭되며, 이를 통해 추가적인 Cross-modal 학습 없이도 목표 지점에 도달할 수 있다. 실험 결과, PlatonicNav는 HM3D-IIN, OVON, R2R-CE 등 주요 벤치마크에서 기존의 지도 학습 기반 모델들과 대등하거나 우수한 성능을 보였다. 특히 Unitree Go2 로봇 플랫폼을 이용한 실세계 평가에서도, 명시적인 Cross-modal 훈련 없이도 성공적인 네비게이션이 가능함을 정량적 및 정성적으로 입증하였다 [Figure 2, Figure 3].
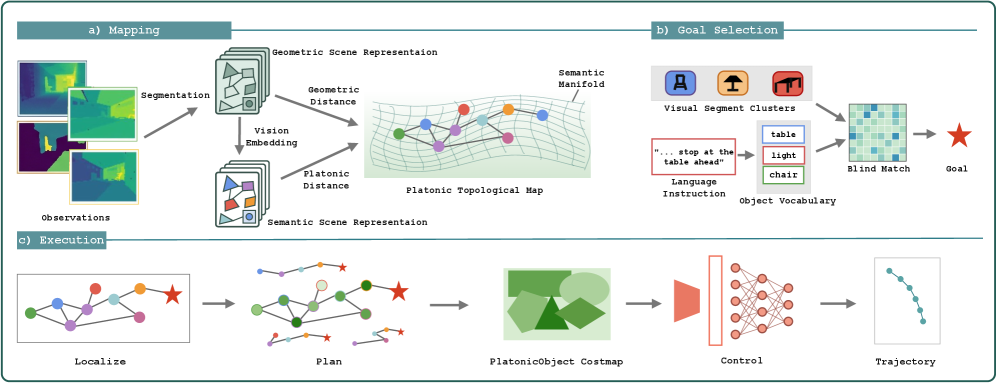
Figure 2 — PlatonicNav 전체 파이프라인
4. Conclusion & Impact (결론 및 시사점)
본 논문은 VLN과 ObjNav가 동일한 의미적 manifold를 공유하는 서로 다른 인터페이스임을 성공적으로 입증하였다. PlatonicNav의 성공은 Cross-modal 정렬을 위해 필수적이라 여겨졌던 대규모 병렬 데이터 세트나 고비용의 VLM 지도 학습이 실제로는 독립적인 인코더 내에 이미 내재된 기하학적 구조를 통해 상당 부분 대체될 수 있음을 시사한다. 이 연구는 향후 Embodied AI가 개별 모달리티의 한계를 넘어 범용적인 의미론적 네비게이션으로 나아가는 데 중요한 이론적, 실무적 토대를 마련하였다.
⚠️ 알림: 이 리뷰는 AI로 작성되었습니다.
관련 포스트
- [논문리뷰] LoMo: Local Modality Substitution for Deeper Vision-Language Fusion
- [논문리뷰] LatentOmni: Rethinking Omni-Modal Understanding via Unified Audio-Visual Latent Reasoning
- [논문리뷰] Revisiting the Platonic Representation Hypothesis: An Aristotelian View
- [논문리뷰] VLingNav: Embodied Navigation with Adaptive Reasoning and Visual-Assisted Linguistic Memory
- [논문리뷰] T2AV-Compass: Towards Unified Evaluation for Text-to-Audio-Video Generation
Review 의 다른글
- 이전글 [논문리뷰] PaddleOCR-VL-1.6: Expanding the Frontier of Document Parsing with Under-Optimized Region Refinement and Progressive Post-Training
- 현재글 : [논문리뷰] PlatonicNav: Unveiling Semantic Correspondence in Navigation with Platonic Topological Maps
- 다음글 [논문리뷰] Pressure-Testing Deception Probes in LLMs: Scaling, Robustness, and the Geometry of Deceptive Representations
댓글