[논문리뷰] Interleaved Speech Language Models Latently Work In Text
링크: 논문 PDF로 바로 열기
메타데이터
저자: Talia Sternberg, Gallil Maimon, Yossi Adi
1. Key Terms & Definitions (핵심 용어 및 정의)
- Interleaved Speech-Text LMs: 음성(Speech) 유닛과 텍스트(Text) 토큰이 동일한 시퀀스 스트림 내에 혼합되어 학습된 언어 모델.
- Logit Lens: 모델의 중간 레이어 hidden state를 학습된 output projection을 통해 어휘(Vocabulary) 공간의 확률 분포로 매핑하여 내부 표현을 해석하는 기법.
- Implicit Latent Transcription: 음성 인식(Speech Recognition) 목적의 직접적인 지도 학습 없이, 모델 내부 중간 레이어에서 음성 입력이 대응되는 텍스트 토큰으로 복원되는 현상.
- Modality Gap: 서로 다른 모달리티(음성 vs 텍스트) 간의 표현 차이로 인해 발생하는 성능 격차나 해석상의 난이도.
2. Motivation & Problem Statement (연구 배경 및 문제 정의)
본 논문은 Interleaved Speech-Text LMs의 내부 latent space에서 음성과 텍스트 모달리티가 어떻게 상호작용하는지에 대한 불투명성을 해결하고자 한다. 최근 연구들은 음성과 텍스트를 혼합하여 학습하는 방식이 모델의 전반적인 의미론적 성능을 향상시킨다고 보고하고 있으나, 모델 내부에서 왜 이러한 성능 향상이 발생하는지에 대한 근본적인 메커니즘은 밝혀지지 않았다. 저자들은 단순히 성능 지표만 측정하는 것을 넘어, 모델의 내부 연산 과정을 추적함으로써 이들 간의 긴밀한 상호작용 원리를 규명하는 것을 목표로 한다. 특히 음성 입력이 모델 내에서 어떻게 텍스트 도메인으로 변환되고 처리되는지를 명확히 정의하고자 한다.
3. Method & Key Results (제안 방법론 및 핵심 결과)
본 연구는 Logit Lens를 활용하여 다양한 크기와 모델 패밀리(Llama3.2-3B, Qwen2.5 등)의 내부 hidden state를 분석하는 프레임워크를 제안한다. 분석 결과, 모델은 입력된 음성을 처리하는 과정에서 중간 레이어에서 텍스트 기반의 Implicit latent transcription 단계를 거치는 것으로 나타났다 [Figure 1]. 이 모델들은 음성 인식(ASR)을 위한 명시적 지도 학습을 수행하지 않았음에도 불구하고, 전체 데이터의 최대 77%에서 현재 발화된 단어를 텍스트 토큰으로 성공적으로 복원하는 성능을 보였다. 또한, Text pretraining과 Interleaved data 학습의 결합이 이러한 현상을 유도하는 핵심 요소임을 입증하였다 [Table 1]. 정량적 실험 결과, implicit transcription 성능이 높은 모델일수록 공통 상식 기반의 사실적 지식(Factual knowledge) 회수 성능이 유의미하게 향상되는 양의 상관관계를 보였다 [Figure 4].
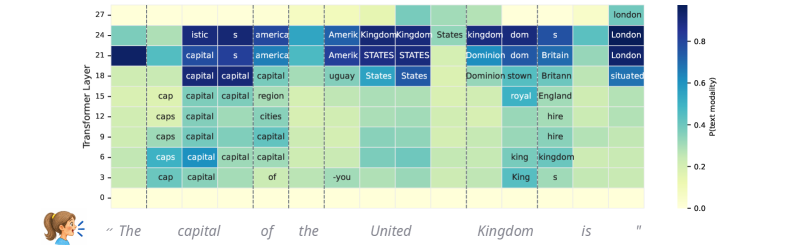
Figure 1 — 암묵적 음성 전사 현상
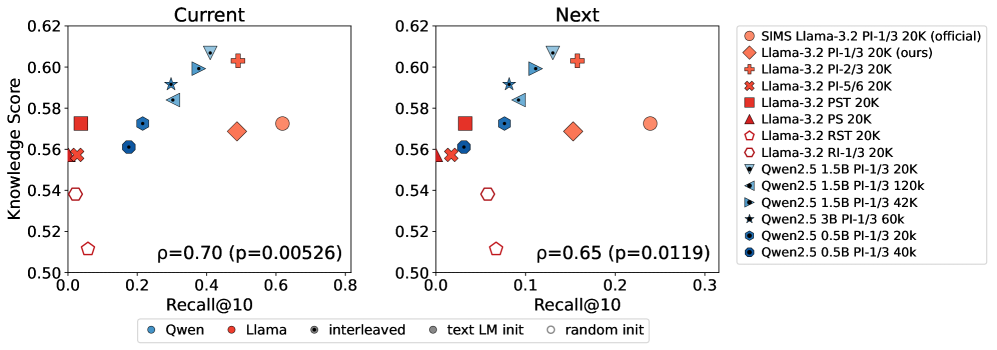
Figure 4 — 전사 능력과 지식 성능의 상관관계
4. Conclusion & Impact (결론 및 시사점)
본 연구는 Interleaved Speech-Text LMs가 본질적으로 '텍스트'라는 내부 작업 공간에서 연산하고 있음을 실증적으로 증명하였다. 이러한 발견은 음성 모달리티가 텍스트 모델의 연산 능력과 어떻게 결합되는지에 대한 새로운 해석적 관점을 제공한다. 향후 SLM(Speech Language Models)의 최적화 단계에서 이러한 내부 전사(Transcription) 메커니즘을 의도적으로 강화하거나 조정함으로써, 더 효율적인 음성 기반의 지식 검색 및 다국어 처리 시스템을 설계하는 데 중요한 가이드라인이 될 것으로 기대된다.
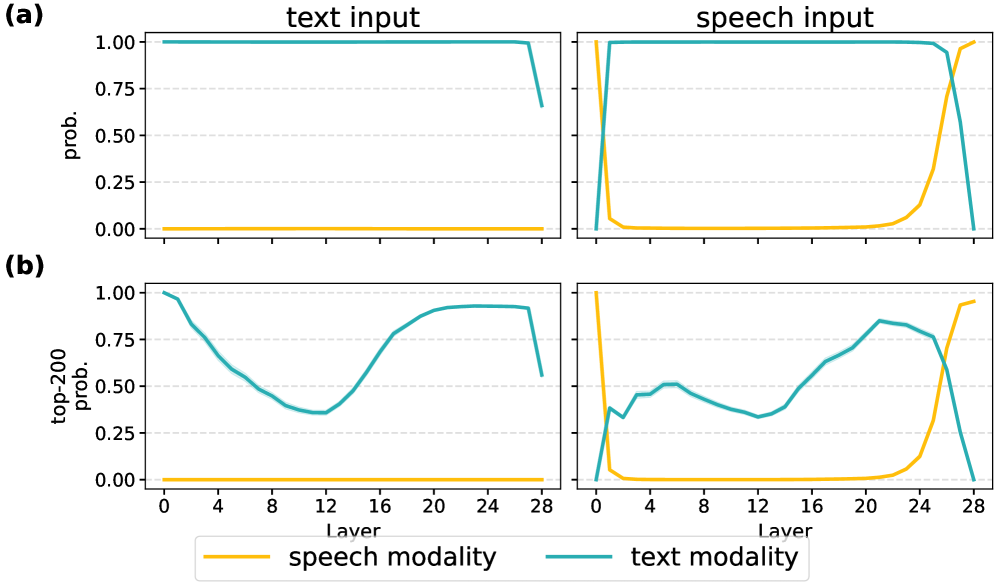
Figure 2 — 모델 레이어별 모달리티 분포
⚠️ 알림: 이 리뷰는 AI로 작성되었습니다.
관련 포스트
- [논문리뷰] Why Multi-Step Tool-Use Reinforcement Learning Collapses and How Supervisory Signals Fix It
- [논문리뷰] What Intermediate Layers Know: Detecting Jailbreaks from Entropy Dynamics
- [논문리뷰] FLUX3D: High-Fidelity 3D Gaussian Generation with Diffusion-Aligned Sparse Representation
- [논문리뷰] Your UnEmbedding Matrix is Secretly a Feature Lens for Text Embeddings
- [논문리뷰] PlatonicNav: Unveiling Semantic Correspondence in Navigation with Platonic Topological Maps
Review 의 다른글
- 이전글 [논문리뷰] Illuminating Unified Multimodal Model for Free-form Interleaved Text-Image Generation
- 현재글 : [논문리뷰] Interleaved Speech Language Models Latently Work In Text
- 다음글 [논문리뷰] Large-Scale Tunnel Air-Ground Collaboration With FLISP: Fast LiDAR-IMU Synchronized Path Planner
댓글