[논문리뷰] Why Multi-Step Tool-Use Reinforcement Learning Collapses and How Supervisory Signals Fix It
링크: 논문 PDF로 바로 열기
저자: Yupu Hao, Zhuoran Jin, Huanxuan Liao, Kang Liu, Jun Zhao
1. Key Terms & Definitions (핵심 용어 및 정의)
- Structural Collapse: RL 학습 과정에서 모델이 의도치 않게 특정 제어 토큰을 과도하게 생성하여, 유효한 도구 호출 구조가 파괴되고 퇴행적인 종결 시퀀스로 수렴하는 현상입니다.
- Interleaved Training: RL 업데이트와 SFT(Supervised Fine-Tuning) 단계를 반복적으로 교차 수행하여 모델의 구조적 안정성을 유지하고 성능 저하를 방지하는 학습 전략입니다.
- Process Reflection Supervision (PRS): 학습 데이터 내의 중간 추론 단계와 구조적 오류를 추출하여 텍스트 형태의 피드백으로 변환하고, 이를 모델이 학습하도록 유도하는 강화된 지도 학습 기법입니다.
- Tool-Use Trajectory: LLM이 외부 도구 호출(Action)과 환경 응답(Feedback)을 반복하며 복잡한 태스크를 해결해 나가는 다단계(Multi-turn) 상호작용 경로입니다.
2. Motivation & Problem Statement (연구 배경 및 문제 정의)
본 논문은 다단계 도구 사용 태스크에서 RL 기반 최적화가 겪는 학습 불안정성과 성능 정체 문제를 해결하고자 합니다. 기존의 pure RL 방식은 환경 보상에만 의존하여 탐색을 수행하는 과정에서, 도구 호출을 위한 필수 제어 토큰(Control token)의 확률 분포를 비정상적으로 증폭시킴으로써 구조적 붕괴를 초래합니다 [Figure 1]. 이러한 현상은 모델의 추론 능력 자체보다는 도구 사용 형식을 유지하는 구조적 안정성 결여에서 기인하며, 단순 보상 중심의 학습이 가진 한계를 명확히 드러냅니다. 따라서 저자들은 RL의 탐색적 이점과 SFT의 안정성을 효과적으로 결합하기 위한 새로운 지도 신호(Supervisory signals) 통합 프레임워크를 제안합니다.
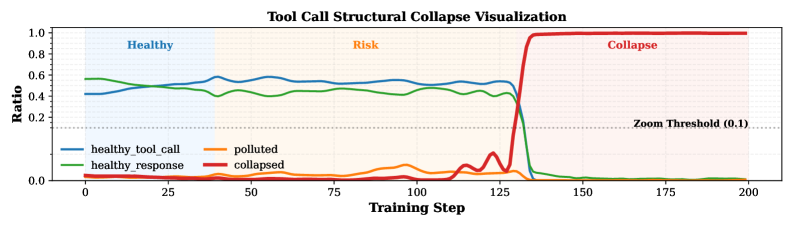
Figure 1 — 학습 중 제어 토큰 빈도 변화
3. Method & Key Results (제안 방법론 및 핵심 결과)
본 논문은 다양한 지도 신호(OPS, HBG, ETS, PRS)를 통합하여 RL의 구조적 붕괴를 제어하는 체계적인 프레임워크를 제안합니다 [Figure 3]. 특히 Process Reflection Supervision (PRS)은 중간 추론 과정을 텍스트로 반영하여 모델이 논리적 구조를 내재화하도록 유도하며, Erroneous Trajectory Supervision (ETS)은 RL 실패 사례를 명시적으로 재학습하여 구조적 실수를 교정합니다. 실험 결과, 단순 RL 방식은 거의 모든 환경에서 성능 붕괴(0점 수렴)를 보인 반면, 제안하는 PRS와 ETS를 포함한 Interleaved 방식은 Qwen2.5-1.5B-Instruct 모델에서 평균 25.75점 및 20.0점의 성과를 기록하며 성능 우위를 입증했습니다 [Table 1]. 특히, SFT와 RL을 교차 적용하는 방식은 동기식(Synchronous) 학습 대비 분포 불일치(Distribution mismatch) 문제를 완화하고, OOD 환경에서도 더 높은 일반화 성능을 보여주었습니다 [Table 2]. 이는 제안된 지도 신호가 모델의 구조적 제어를 위한 필수적인 정규화(Regularizer) 역할을 함을 시사합니다.
Figure 3 — 제안하는 학습 프레임워크
4. Conclusion & Impact (결론 및 시사점)
본 연구는 다단계 도구 사용 환경에서의 RL 실패가 능력의 상실이 아닌 구조적 붕괴임을 규명하고, 이를 해결하기 위한 다각적인 지도 신호 활용 방안을 제시하였습니다. Interleaved 방식과 텍스트 기반의 정교한 지도 학습은 모델의 구조적 안정성을 획기적으로 개선하며, 특히 PRS와 같은 방식은 향후 복잡한 에이전트 태스크에서 RL을 효과적으로 운용하기 위한 중요한 이론적 토대를 제공합니다. 이 연구는 대규모 언어 모델이 안정적인 도구 활용 에이전트로 진화하는 데 있어, 보상 신호 외에 명시적인 구조적 지도 신호의 중요성을 강조하는 산업적/학술적 시사점을 가집니다.
⚠️ 알림: 이 리뷰는 AI로 작성되었습니다.
관련 포스트
- [논문리뷰] Thinking with Programming Vision: Towards a Unified View for Thinking with Images
- [논문리뷰] UltraCUA: A Foundation Model for Computer Use Agents with Hybrid Action
- [논문리뷰] Knowledge-based Visual Question Answer with Multimodal Processing, Retrieval and Filtering
- [논문리뷰] Mem-α: Learning Memory Construction via Reinforcement Learning
- [논문리뷰] Xiaomi-GUI-0 Technical Report
Review 의 다른글
- 이전글 [논문리뷰] When Does Combining Language Models Help? A Co-Failure Ceiling on Routing, Voting, and Mixture-of-Agents Across 67 Frontier Models
- 현재글 : [논문리뷰] Why Multi-Step Tool-Use Reinforcement Learning Collapses and How Supervisory Signals Fix It
- 다음글 [논문리뷰] Boundary-Aware Context Grounding for A Low-Channel EEG Agent
댓글