[논문리뷰] When Does Combining Language Models Help? A Co-Failure Ceiling on Routing, Voting, and Mixture-of-Agents Across 67 Frontier Models
링크: 논문 PDF로 바로 열기
메타데이터
저자: Josef Chen, et al.
1. Key Terms & Definitions (핵심 용어 및 정의)
- Co-failure Ceiling: 모든 모델이 동일한 쿼리에서 동시에 실패하는 비율($\beta$)에 의해 결정되는 이론적 정확도 한계($1-\beta$)를 의미하며, 어떠한 선택 정책(Router, Voting, Cascade 등)도 이를 초과할 수 없음.
- Pairwise Error Correlation ($\rho$): 두 모델 간의 오차 상관관계를 나타내는 지표로, 기존 연구에서는 이 값이 낮을수록 모델 결합(Ensemble)의 이득이 클 것으로 기대함.
- Tetrachoric Calibration: 이진 오차 지표 간의 Pearson 상관관계가 아닌, 기저에 깔린 잠재적 확률 분포를 추정하여 모델 간 상관관계를 측정하는 통계적 기법.
- Oracle Gain ($G$): 단일 최고 성능 모델(Single-best) 대비 per-query 오라클 모델이 달성할 수 있는 성능 향상 폭으로, 논문에서는 실제 정책이 도달 가능한 성능의 상한을 정의함.
2. Motivation & Problem Statement (연구 배경 및 문제 정의)
본 논문은 다양한 LLM 시스템(Routing, Voting, Mixture-of-Agents)의 정확도 향상 잠재력이 일반적으로 알려진 것보다 훨씬 낮다는 문제를 제기한다. 기존 실무에서는 모델 간의 오차 상관관계인 $\rho$를 지표로 활용하여, $\rho$가 낮으면 다양한 모델을 결합하는 것이 효과적이라 판단해왔다. 그러나 저자들은 이러한 $\rho$ 지표가 실제 결합 성능을 제약하는 실질적인 요인인 '동시 실패율($\beta$)'을 포착하지 못한다는 점을 증명한다. 즉, 기존의 $\rho$ 기반 진단은 모델 결합의 이득을 잘못 측정하게 만들며, frontier 모델들조차 특정 작업에서 함께 실패하는 경향이 커짐에 따라 orchestration의 효용성이 과대평가되고 있다 [Figure 1].
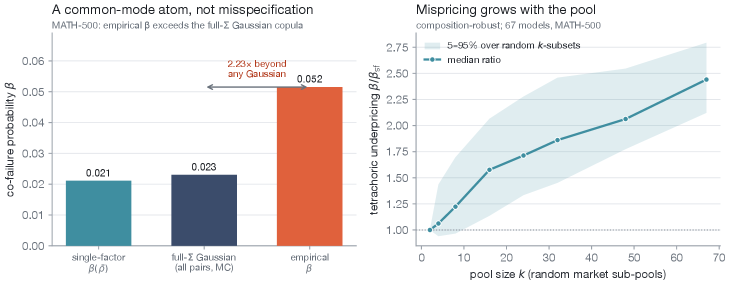
Figure 1 — 모델 오케스트레이션 개념도 및 제약
3. Method & Key Results (제안 방법론 및 핵심 결과)
본 연구는 67개의 frontier 모델을 포함한 대규모 모델 풀을 활용하여 실증적인 orchestration 한계를 측정하였다. 먼저, 모든 선택 정책의 성능이 $1-\beta$라는 ceiling에 고정됨을 수리적으로 증명하고, 단 한 번의 검증 세트만으로도 성능 한계를 추정할 수 있는 Clopper–Pearson bound 기반의 $0 비용 인증 기법을 제시한다. 실험 결과, MATH-500과 같은 개방형 수학 문제 도메인에서 $\beta$ 값은 단일 인자 모델이 예측하는 것보다 약 2.5배 더 큰 것으로 나타났다(90% CI 1.7~3.4). 또한, 모델 수가 증가할수록 이러한 오차 상관관계의 미스프라이싱(mispricing) 현상이 심화됨을 확인하였다. 정량적으로, 대부분의 정교한 라우팅 모델들은 단일 최고 모델(Single-best) 대비 Oracle Gain ($G$)의 극히 일부분만을 구현해내며, 특히 frontier 모델들이 공유하는 실패 패턴으로 인해 실제 도달 가능한 이득은 매우 제한적임을 입증하였다 [Table 2].
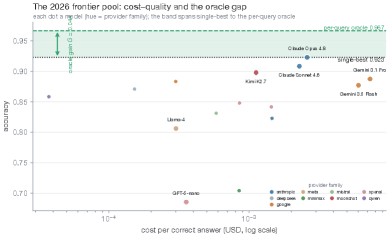
Table 2 — 동시 실패율과 성능 지표 비교
4. Conclusion & Impact (결론 및 시사점)
본 논문은 모델 결합의 한계가 $\rho$가 아닌 $\beta$에 의해 결정된다는 것을 명확히 밝히며, 단순히 모델을 늘리는 방식이 아닌 작업별 실패 패턴의 분석이 핵심임을 시사한다. 이 연구 결과는 모델 orchestration을 구축하려는 기업들에게 무분별한 모델 통합의 비용 대비 효용성을 재평가할 것을 요구한다. 결과적으로, orchestration의 실질적 이득은 모델을 추가하는 데서 오는 것이 아니라, 모델들이 서로 다른 질문에서 실패할 때 발생하는 상호 보완성에서 기인한다는 점을 학계와 산업계에 강조한다.
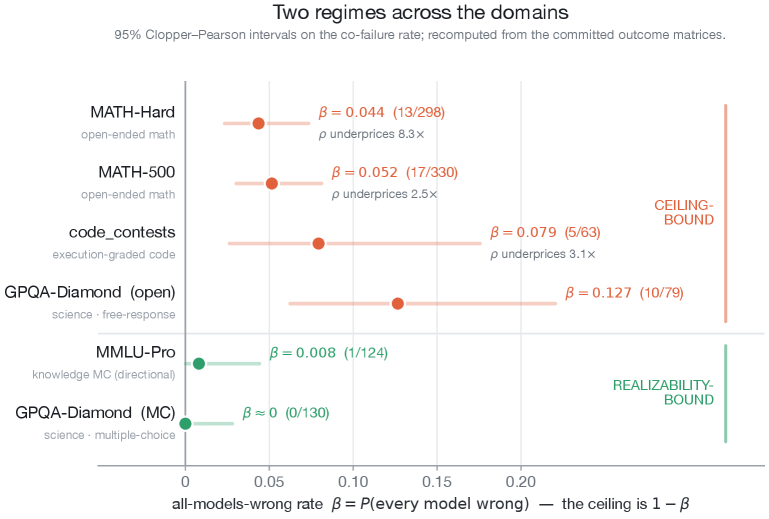
Table 1 — 프론티어 모델의 도메인별 오라클 성능
⚠️ 알림: 이 리뷰는 AI로 작성되었습니다.
관련 포스트
- [논문리뷰] Cluster, Route, Escalate: Cascaded Framework for Cost-Aware LLM Serving
- [논문리뷰] SciOrch: Learning to Orchestrate Expert LLMs for Solving Frontier Multimodal Scientific Reasoning Tasks
- [논문리뷰] When Cloud Agents Meet Device Agents: Lessons from Hybrid Multi-Agent Systems
- [논문리뷰] Qualixar OS: A Universal Operating System for AI Agent Orchestration
- [논문리뷰] Dynamic Model Routing and Cascading for Efficient LLM Inference: A Survey
Review 의 다른글
- 이전글 [논문리뷰] ViQ: Text-Aligned Visual Quantized Representations at Any Resolution
- 현재글 : [논문리뷰] When Does Combining Language Models Help? A Co-Failure Ceiling on Routing, Voting, and Mixture-of-Agents Across 67 Frontier Models
- 다음글 [논문리뷰] Why Multi-Step Tool-Use Reinforcement Learning Collapses and How Supervisory Signals Fix It
댓글