[논문리뷰] Illuminating Unified Multimodal Model for Free-form Interleaved Text-Image Generation
링크: 논문 PDF로 바로 열기
저자: Chonghuinan Wang, Zhikai Chen, Chunwei Wang, Yecong Wan, Junwei Yang, Zhixin Wang, Wei Zhang, Jiaqi Xu, Renjing Pei, Xiaohe Wu, Fan Li, Wangmeng Zuo
## 1. Key Terms & Definitions (핵심 용어 및 정의)
- ILLUME-X: 본 논문에서 제안하는 Free-form interleaved text-image generation을 위한 통합 멀티모달 프레임워크입니다.
- Interleaved Classifier-free Guidance (ICFG): 텍스트와 이미지 조건을 분리하여 멀티모달 시퀀스 생성의 정밀도를 높이는 제어 메커니즘입니다.
- ILScore: 멀티모달 생성물의 교차 모달 연속성과 단일 모달 품질을 정량적으로 평가하기 위해 제안된 새로운 평가 프로토콜입니다.
- Unified Transformer: 비전과 텍스트 토큰을 공유된 Attention 메커니즘으로 처리하여 N-to-M 멀티모달 추론을 가능하게 하는 모델 구조입니다.
## 2. Motivation & Problem Statement (연구 배경 및 문제 정의) 본 논문은 기존 MLLM이 텍스트와 이미지를 교차로 생성하는 Free-form interleaved task에서 겪는 성능 한계를 해결하고자 합니다. 기존의 AR(Autoregressive) 기반 모델이나 diffusion 하이브리드 방식은 고품질의 interleaved 시퀀스를 생성하는 데 필요한 데이터 부족과 안정적인 훈련 방법론의 부재라는 문제에 직면해 있습니다 [Figure 1]. 특히, 기존 평가 벤치마크들은 특정 구조에만 의존하여 복잡한 interleaved 출력을 객관적으로 검증하는 데 한계가 있었습니다. 이를 극복하기 위해 본 연구는 데이터 효율성, 훈련 안정성, 그리고 포괄적인 평가 지표를 통합한 새로운 패러다임을 제안합니다.
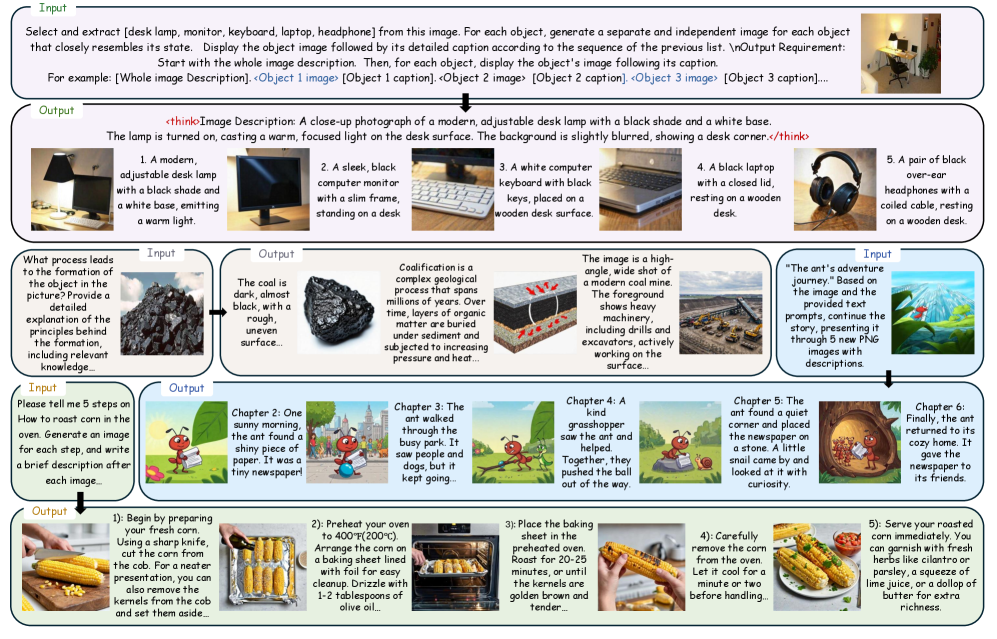
Figure 1 — ILLUME-X의 통합 생성 예시
## 3. Method & Key Results (제안 방법론 및 핵심 결과) 본 논문은 통합된 데이터 파이프라인과 Progressive 훈련 전략을 결합한 ILLUME-X를 제안합니다 [Figure 2]. 저자들은 비디오 데이터로부터 시맨틱 전환을 추출하고, MLLM을 활용한 다단계 In-context generation을 통해 100K 규모의 고품질 interleaved 학습 데이터를 구축하였습니다 [Figure 3]. 모델은 Shared Attention 기반의 Unified Transformer 구조를 채택하여 text, vision, 그리고 특수 토큰(BOI, EOI, EOS)을 통합적으로 처리합니다. 주요 실험 결과, ILLUME-X는 ISG-Bench에서 평균 점수 6.26을 기록하며 기존의 Unified 모델들을 큰 격차로 압도하였습니다. 또한, 새롭게 도입된 ILScore 평가 지표 상에서도 전체 점수 5.34를 달성하여 최신 상용 모델인 Gemini 3 Pro보다 우수한 성능을 입증하였습니다. 특히, GenEval과 DPG-Bench 등 표준 벤치마크에서도 기존 모델 대비 높은 Attribute 및 Entity 정확도를 보이며 복잡한 시각적 합성 능력에서의 우위를 점하였습니다.
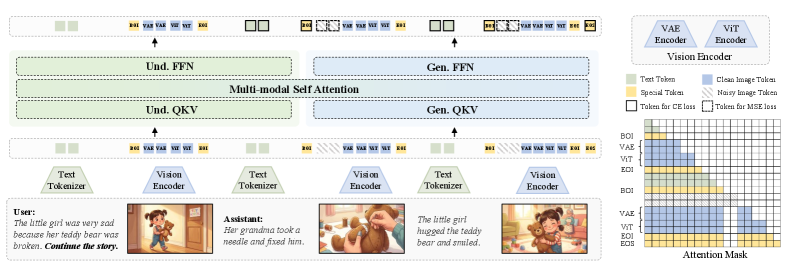
Figure 2 — ILLUME-X 전체 아키텍처
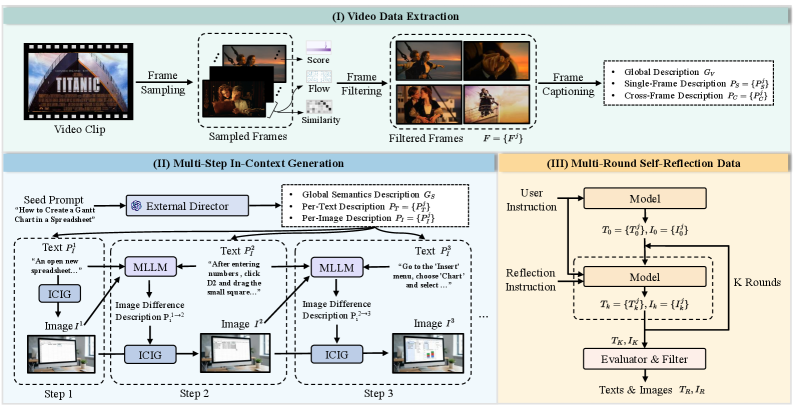
Figure 3 — 데이터 구축 파이프라인
## 4. Conclusion & Impact (결론 및 시사점) 본 연구는 Free-form interleaved text-image generation을 위한 통합된 파이프라인과 평가 프로토콜을 성공적으로 확립하였습니다. ILLUME-X의 도입은 멀티모달 생성 모델이 실제 복합적인 시각적 스토리텔링과 같은 고난도 과업을 수행하는 데 있어 더 높은 정밀도와 효율성을 갖추게 함을 시사합니다. 향후 본 프레임워크는 고해상도 생성 및 확장된 컨텍스트 길이를 지원하는 방향으로 발전할 가능성이 크며, 범용 멀티모달 지능 연구에 중요한 이정표가 될 것으로 평가됩니다.
⚠️ 알림: 이 리뷰는 AI로 작성되었습니다.
관련 포스트
- [논문리뷰] UniGRPO: Unified Policy Optimization for Reasoning-Driven Visual Generation
- [논문리뷰] ViQ: Text-Aligned Visual Quantized Representations at Any Resolution
- [논문리뷰] Running the Gauntlet: Re-evaluating the Capabilities of Agents Beyond Familiar Environments
- [논문리뷰] V-Zero: Answer-Label-Free On-Policy Distillation with Contrastive Evidence Gating for Fine-Grained Visual Reasoning
- [논문리뷰] FlowR2A: Learning Reward-to-Action Distribution for Multimodal Driving Planning
Review 의 다른글
- 이전글 [논문리뷰] How Good Can Linear Models Be for Time-Series Forecasting?
- 현재글 : [논문리뷰] Illuminating Unified Multimodal Model for Free-form Interleaved Text-Image Generation
- 다음글 [논문리뷰] Interleaved Speech Language Models Latently Work In Text
댓글