[논문리뷰] What Intermediate Layers Know: Detecting Jailbreaks from Entropy Dynamics
링크: 논문 PDF로 바로 열기
메타데이터
저자: Sofiia Nikolenko, Michele Papucci, Mina Rezaei, Shireen Kudukkil Manchingal
1. Key Terms & Definitions (핵심 용어 및 정의)
- Predictive Entropy: 모델이 다음 토큰을 예측할 때 생성하는 확률 분포의 Shannon entropy로, 모델의 국소적 불확실성을 측정하는 지표입니다.
- Logit Lens: 모델의 중간 계층(intermediate layer) hidden state를 최종 unembedding matrix에 투영하여 각 단계에서의 어휘적 예측 분포를 가시화하는 기술입니다.
- Entropy Trajectories: 프롬프트의 토큰 위치에 따라 변하는 Predictive Entropy의 변화 경로를 의미하며, 이를 기반으로 모델의 내재적 상태를 분석합니다.
- Dynamic Trend Features: Kendall’s τ, Spearman’s ρ, Monotonicity 등 토큰 위치 변화에 따른 엔트로피의 구조적 흐름을 포착하는 특징량입니다.
2. Motivation & Problem Statement (연구 배경 및 문제 정의)
본 논문은 대규모 언어 모델(LLMs)의 안전성을 위협하는 Jailbreak 공격을 모델 내부의 활성화 상태(internal representations) 분석을 통해 효율적으로 탐지하고자 합니다. 기존 연구들은 주로 프롬프트 수준의 필터링이나 외부 분류기에 의존하여 모델 내부의 의미적 변화를 간과하는 한계가 있습니다. 저자들은 Jailbreak 공격이 모델 내부에 특정한 불확실성 패턴을 유발한다는 가설을 세우고, 이를 엔트로피의 역학 관점에서 체계적으로 규명하고자 합니다. 특히, 정적인 엔트로피 평균값보다는 토큰 위치에 따라 변하는 Entropy Trajectories의 구조적 특징이 더욱 강력한 탐지 신호를 제공함을 제시합니다 [Figure 1].

Figure 1 — 엔트로피 궤적 비교
3. Method & Key Results (제안 방법론 및 핵심 결과)
본 연구는 Logit Lens를 사용하여 frozen LLM의 중간 계층에서 토큰 수준의 Predictive Entropy 궤적을 추출하고, 이를 기반으로 Jailbreak를 탐지하는 학습이 필요 없는(training-free) 프레임워크를 제안합니다. 제안된 방법론은 프롬프트의 전체 엔트로피 평균값(Static) 대신 엔트로피의 순위 기반 변화 추세(Dynamic)를 측정하는 데 초점을 맞춥니다. Llama-3.1-8B, Qwen3-8B, Gemma-7b를 대상으로 실험한 결과, Monotonicity와 같은 dynamic features가 대부분의 조건에서 Static 특징량보다 우수한 탐지 성능을 보였습니다. 정량적으로, Llama-3.1-8B 모델에서 Monotonicity 지표는 최대 0.999의 AUROC를 기록하며 높은 판별력을 입증했습니다 [Table 2]. 실험을 통해 Jailbreak를 유발하는 엔트로피 패턴은 모델의 최하단이나 최상단이 아닌 중간 계층(Intermediate Layers)에서 가장 두드러지게 나타나며, 최종 출력 계층으로 갈수록 해당 신호가 감쇠됨을 확인했습니다 [Figure 2].
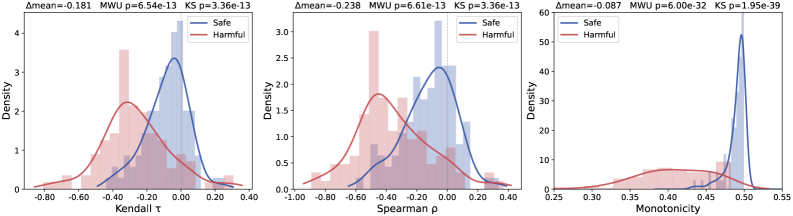
Figure 2 — 중간 계층 엔트로피 분포
4. Conclusion & Impact (결론 및 시사점)
본 논문은 Jailbreak 시도가 모델 중간 계층 내의 정형화된 불확실성 동역학을 유발하며, 이는 Kendall’s τ와 같은 Dynamic Trend Features를 통해 정교하게 포착될 수 있음을 증명했습니다. 이 연구는 별도의 추가 학습(fine-tuning) 없이도 모델 내부 표현만으로 강력한 공격 탐지가 가능함을 보여주며, LLM 해석 가능성(interpretability) 및 안전성 강화 측면에서 중요한 기여를 합니다. 향후 본 방법론은 더 큰 규모의 모델이나 복잡한 추론 모델에 적용되어, 모델 배포 전 보안 검증 단계에서 실질적인 방어 기제로 활용될 것으로 기대됩니다.
⚠️ 알림: 이 리뷰는 AI로 작성되었습니다.
관련 포스트
- [논문리뷰] On the Evidentiary Limits of Membership Inference for Copyright Auditing
- [논문리뷰] A Safety Report on GPT-5.2, Gemini 3 Pro, Qwen3-VL, Doubao 1.8, Grok 4.1 Fast, Nano Banana Pro, and Seedream 4.5
- [논문리뷰] Soft Instruction De-escalation Defense
- [논문리뷰] LLMs4All: A Review on Large Language Models for Research and Applications in Academic Disciplines
- [논문리뷰] Evolution Fine-Tuning: Learning to Discover Across 371 Optimization Tasks
Review 의 다른글
- 이전글 [논문리뷰] Wan-Streamer v0.1: End-to-end Real-time Interactive Foundation Models
- 현재글 : [논문리뷰] What Intermediate Layers Know: Detecting Jailbreaks from Entropy Dynamics
- 다음글 [논문리뷰] When Lower Privileges Suffice: Investigating Over-Privileged Tool Selection in LLM Agents
댓글