[논문리뷰] Wan-Streamer v0.1: End-to-end Real-time Interactive Foundation Models
링크: 논문 PDF로 바로 열기
메타데이터
저자: Lianghua Huang, Zhifan Wu, Wei Wang, et al.
1. Key Terms & Definitions (핵심 용어 및 정의)
- Wan-Streamer: 언어, 오디오, 비디오 입출력을 단일 Transformer에서 처리하는 네이티브 스트리밍, end-to-end 인터랙티브 파운데이션 모델입니다.
- Block-causal Attention: 증분 스트리밍 생성(incremental streaming generation)을 가능하게 하며, 인과적(causal) 제약 조건을 유지하면서 시퀀스를 처리하는 핵심 메커니즘입니다.
- Thinker-Performer Pipeline: 추론 과정에서 thinker(상태 업데이트 및 제어)와 performer(잠재 변수 생성)를 분리하여 지연 시간(Latency)을 최소화하고 하드웨어 효율을 극대화하는 배포 전략입니다.
- Full-duplex: 사용자의 입력을 실시간으로 수신함과 동시에 에이전트가 반응을 생성하는 양방향 상호작용 방식으로, 중단(interruption)이나 동시 대화 처리를 지원합니다.
2. Motivation & Problem Statement (연구 배경 및 문제 정의)
본 논문은 실시간 오디오-비디오 인터랙션의 단절성과 모듈 간의 지연 시간 문제를 해결하기 위해 Wan-Streamer를 제안한다. 기존 연구들은 VAD, ASR, LLM, TTS 등을 결합한 캐스케이드(cascaded) 방식을 사용하여, 모듈 경계에서의 대기 시간과 오차 누적 문제에 직면해 있다 [Figure 1]. 이러한 방식은 인간의 자연스러운 인터랙션 패턴인 실시간성 및 전이중(full-duplex) 특성을 온전히 반영하지 못하며, 언어와 비주얼 표현 간의 동기화 부족을 야기한다. 따라서 저자들은 인과적 스트리밍(causal streaming)을 근간으로 하여 perception, reasoning, generation이 통합된 단일 모델의 필요성을 강조한다.
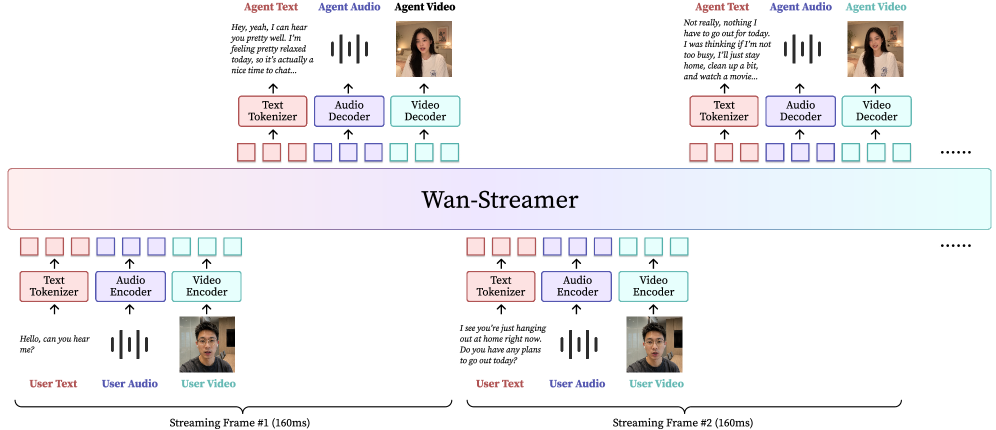
Figure 1 — Wan-Streamer 전체 아키텍처 개요
3. Method & Key Results (제안 방법론 및 핵심 결과)
본 논문은 모든 입력과 출력을 단일 인과적 시퀀스로 모델링하는 Wan-Streamer 아키텍처를 도입하여 상호작용의 자연스러움을 극대화한다. 저자들은 causal audio/video VAEs, 인과적 인코더/디코더, 그리고 block-causal attention을 통해 스트리밍 단위(160 ms) 내에서 실시간 반응이 가능하도록 설계하였다 [Figure 1]. 효율적인 추론을 위해 thinker-performer 인프라를 구축하여, 현재 프레임의 이해와 이전 프레임의 출력 디코딩, 다음 프레임의 잠재 변수 생성을 병렬 처리한다 [Figure 2]. 주요 실험 결과, Wan-Streamer는 모델 측면에서 약 200 ms의 응답 지연 시간(response latency)을 달성하였다. 또한 네트워크 지연을 포함한 총 인터랙션 지연 시간은 약 550 ms로, 기존의 모듈화된 시스템 대비 낮은 지연 시간과 고품질의 25 FPS 비디오 출력을 제공한다.
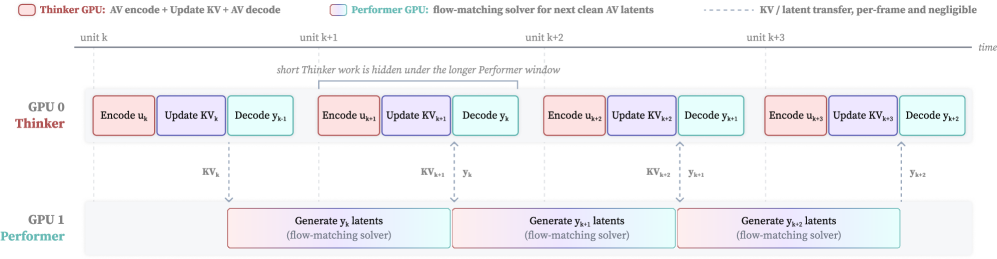
Figure 2 — Thinker-Performer 스트리밍 추론 파이프라인
4. Conclusion & Impact (결론 및 시사점)
본 논문은 실시간 양방향 인터랙션이 가능한 end-to-end 파운데이션 모델로서 Wan-Streamer의 효용성을 입증하였다. 이는 복잡한 모듈 조합 없이도 perception과 expression을 통합 학습함으로써, 인간과 유사한 반응 속도와 동기화된 멀티모달 출력을 가능하게 한다. 본 연구는 차세대 임베디드 어시스턴트 및 대화형 디지털 휴먼 설계에 있어, 시스템을 캐스케이드 방식에서 탈피하여 네이티브 스트리밍 모델로 전환해야 한다는 중요한 시사점을 제시한다.
⚠️ 알림: 이 리뷰는 AI로 작성되었습니다.
관련 포스트
Review 의 다른글
- 이전글 [논문리뷰] V-Zero: Answer-Label-Free On-Policy Distillation with Contrastive Evidence Gating for Fine-Grained Visual Reasoning
- 현재글 : [논문리뷰] Wan-Streamer v0.1: End-to-end Real-time Interactive Foundation Models
- 다음글 [논문리뷰] What Intermediate Layers Know: Detecting Jailbreaks from Entropy Dynamics
댓글