[논문리뷰] Your UnEmbedding Matrix is Secretly a Feature Lens for Text Embeddings
링크: 논문 PDF로 바로 열기
메타데이터
저자: Songhao Wu, Zhongxin Chen, Yuxuan Liu, Heng Cui, Cong Li, Rui Yan
1. Key Terms & Definitions (핵심 용어 및 정의)
- Unembedding Matrix: LLM의 마지막 레이어 출력(hidden states)을 vocabulary space로 투영하여 다음 토큰을 예측하는 행렬로, 본 논문에서는 이 행렬이 임베딩 공간의 의미론적 편향을 결정하는 필터 역할을 함을 규명함.
- Logit Lens: 모델의 중간 활성화를 vocabulary space로 직접 투영하여, 특정 임베딩이 어떤 토큰과 강하게 정렬되는지 시각화하고 해석하는 Mechanistic Interpretability 도구.
- Edge Spectrum: Unembedding matrix의 singular value decomposition(SVD) 결과에서, 가장 크거나 작은 singular value에 대응하는 right singular vectors가 만드는 subspace. 이 공간이 높은 빈도의 무의미한 토큰을 임베딩에 과하게 투영한다는 것이 논문의 핵심 발견임.
- EmbedFilter: 위에서 발견된 Edge Spectrum subspace를 선형 변환을 통해 제거함으로써, 높은 빈도의 노이즈를 억제하고 의미론적 표현을 강화하는 사후 처리(post-processing) 기술.
2. Motivation & Problem Statement (연구 배경 및 문제 정의)
본 논문은 LLM이 우수한 zero-shot 능력을 갖추고 있음에도 불구하고, 범용 text embedding 모델로 활용될 때는 성능이 저하되는 원인을 분석하고 해결하고자 한다. 저자들은 raw text embedding이 vocabulary space에 투영될 때, 실제 의미와 무관한 고빈도(high-frequency) 토큰에 과도하게 정렬되는 현상을 발견하였다 [Figure 1]. 이러한 현상은 LLM 내부에 고유한 "average" token(훈련 코퍼스의 빈도 가중 평균)을 향해 임베딩이 쏠리는 '표현 붕괴(representation collapse)' 및 anisotropy 문제에 기인한다. 기존의 heuristic한 prompt engineering 방식은 이러한 근본적인 bottleneck을 해결하지 못하며, 결과적으로 LLM이 잠재적으로 보유한 풍부한 의미론적 정보를 효과적으로 추출하지 못한다는 한계가 있다.
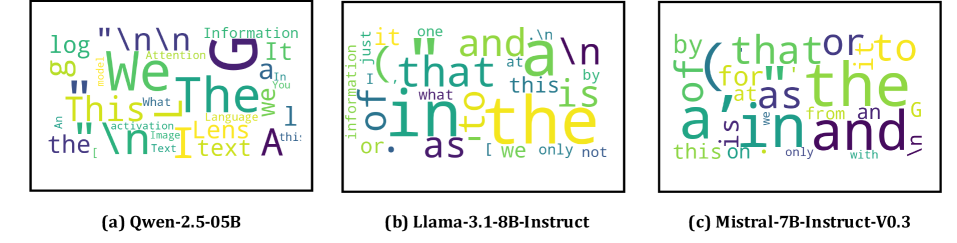
Figure 1 — LLM 임베딩의 Logit Lens 분석
3. Method & Key Results (제안 방법론 및 핵심 결과)
저자들은 LLM의 unembedding matrix가 일종의 feature lens 역할을 한다는 점에 착안하여, 이를 역공학(reverse-engineering)함으로써 무의미한 고빈도 토큰을 생성하는 Edge Spectrum subspace를 식별하였다 [Figure 2]. 제안하는 EmbedFilter는 이 subspace를 간단한 선형 변환으로 필터링하여 임베딩을 정제하는 기법이다. 본 방법론은 별도의 재학습 없이 사후 처리만으로 적용 가능하며, MTEB 벤치마크에서 기존 baseline 대비 평균 14.1%의 성능 향상을 기록하였다 [Table 1]. 또한, EmbedFilter는 orthogonal 행렬의 특성을 활용한 거리 보존 변환(distance-preserving transformation)으로, 성능 손실을 최소화하면서 차원 축소(dimensionality reduction)를 동시에 달성할 수 있다. 실험 결과, 원래 차원의 1/8 수준으로 임베딩을 압축하더라도 정제된 표현력을 유지하여 retrieval 속도와 저장 효율성을 크게 개선하였다. 추가적인 Logit Lens 분석을 통해 정제된 임베딩이 고빈도 노이즈가 아닌 실제 입력 텍스트와 관련된 의미 있는 토큰에 정렬됨을 입증하였다 [Figure 3].
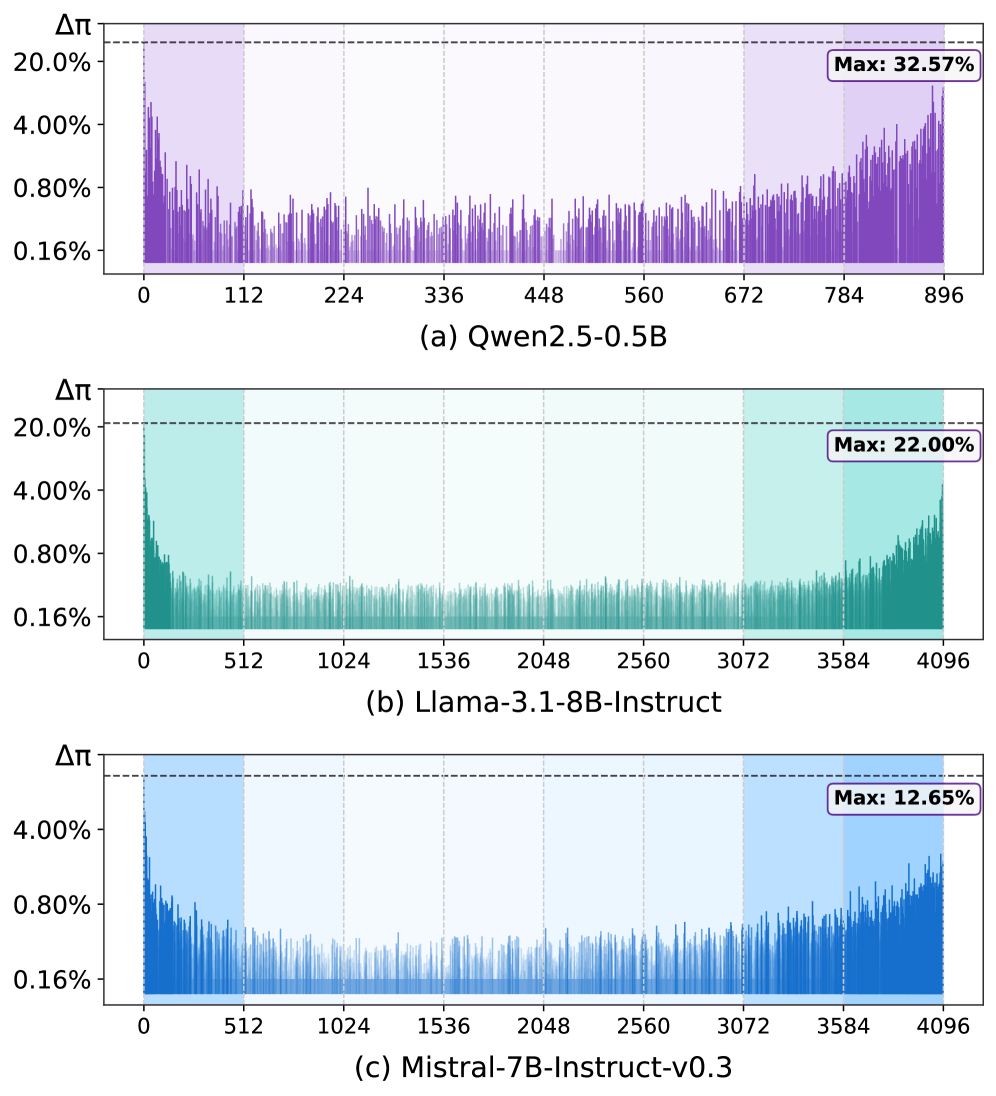
Figure 2 — Edge Spectrum subspace 분포
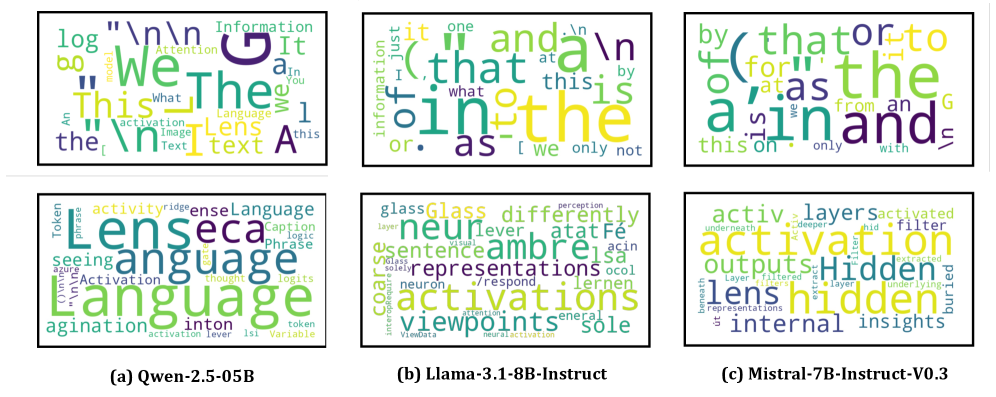
Figure 3 — EmbedFilter 정제 후 Logit 분석
4. Conclusion & Impact (결론 및 시사점)
본 연구는 LLM의 unembedding matrix를 해석 가능한 도구로 활용하여 text embedding의 성능 저하 원인을 규명하고, 이를 해결할 수 있는 효율적인 솔루션인 EmbedFilter를 제안하였다. 본 연구의 결과는 고성능 text embedding 추출을 위해 복잡한 pipeline이나 추가 학습이 반드시 필요한 것은 아님을 시사하며, 간단한 선형 변환만으로도 모델의 효율성과 효과성을 동시에 극대화할 수 있음을 보여준다. 이러한 메커니즘 해석과 실용적 기술은 추후 LLM 기반 representation 학습 전략 수립 및 대규모 retrieval 시스템 최적화에 중요한 기반이 될 것으로 기대된다.
⚠️ 알림: 이 리뷰는 AI로 작성되었습니다.
관련 포스트
- [논문리뷰] Spurious Rewards Paradox: Mechanistically Understanding How RLVR Activates Memorization Shortcuts in LLMs
- [논문리뷰] Map the Flow: Revealing Hidden Pathways of Information in VideoLLMs
- [논문리뷰] Beyond Transcription: Mechanistic Interpretability in ASR
- [논문리뷰] Interpreting and Steering a Text-to-Speech Language Model with Sparse Autoencoders
- [논문리뷰] Why Muon Outperforms Adam: A Curvature Perspective
Review 의 다른글
- 이전글 [논문리뷰] WorldBench: A Challenging and Visually Diverse Multimodal Reasoning Benchmark
- 현재글 : [논문리뷰] Your UnEmbedding Matrix is Secretly a Feature Lens for Text Embeddings
- 다음글 [논문리뷰] dots.tts Technical Report
댓글