[논문리뷰] dots.tts Technical Report
링크: 논문 PDF로 바로 열기
저자: Shi Lian, Changtao Li, Bohan Li, Hankun Wang, Da Zheng, Junfeng Tian, Yufeng Ma, Colin Zhang, Kai Yu
Part 1: 요약 본문
1. Key Terms & Definitions (핵심 용어 및 정의)
- AudioVAE: 음성을 128차원 연속 latent 공간으로 인코딩하고, 이를 고품질 음성으로 복원하는 신경망(Neural Vocoder)의 역할을 수행하는 모델입니다.
- AR-FM (Autoregressive Flow-Matching): 연속 latent 공간에서 다음 Patch를 예측하는 핵심 아키텍처로, Diffusion Transformer(DiT) 기반의 velocity field 예측을 통해 음성을 생성합니다.
- Self-corrective Alignment: 외부 보상 모델 없이 모델 스스로 자신의 추론 오차를 학습하여 장기 일관성(Long-range consistency)을 높이는 후학습(Post-training) 기법입니다.
- MeanFlow Distillation: 복잡한 ODE Solver 과정을 단일 또는 소수의 단계로 압축하여 고속 추론을 가능하게 하는 지식 증류 기법입니다.
- 1T1A (1-Text-1-Audio) Interleaved mode: 텍스트 토큰과 오디오 단위를 1대 1로 교차 배치하여 실시간 스트리밍 환경에서 낮은 첫 번째 패킷 Latency를 구현하는 방식입니다.
2. Motivation & Problem Statement (연구 배경 및 문제 정의)
본 논문은 기존의 이산적(Discrete) 토큰 기반 TTS 모델이 가진 표현력의 한계를 극복하고, 연속적인(Continuous) latent 공간에서 안정적인 AR 음성 생성을 구현하고자 합니다. 기존의 연속 AR 모델들은 생성 과정에서 발생하는 오차 누적(Error accumulation) 문제로 인해 긴 발화에서 불안정성을 보였으며, 이는 음질 저하와 발화 중단으로 이어지는 주요 원인이었습니다 [Figure 1]. 저자들은 이러한 오차 누적을 방지하고 연속 latent 기반의 장점인 고품질 음성과 풍부한 표현력을 유지하기 위한 새로운 엔드투엔드(End-to-End) 시스템을 제안합니다.
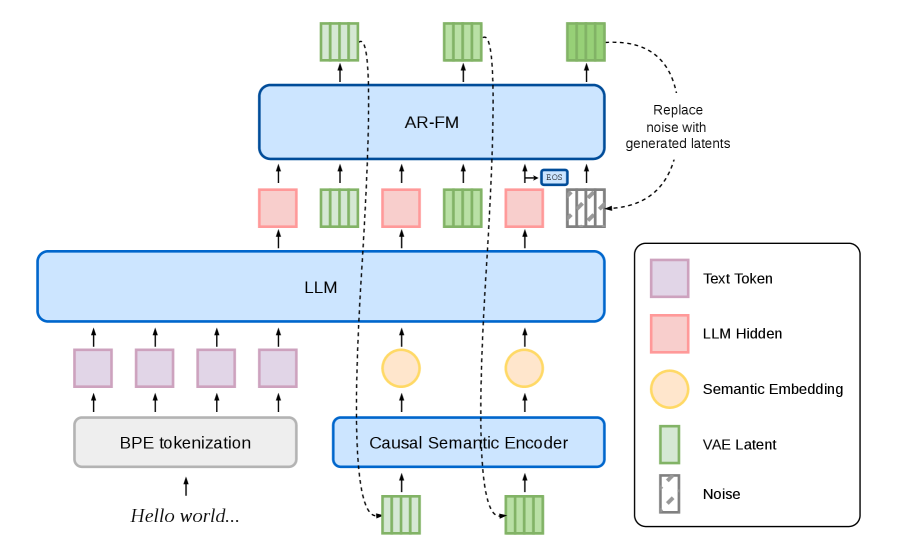
Figure 1 — dots.tts 모델 전체 아키텍처
3. Method & Key Results (제안 방법론 및 핵심 결과)
본 논문은 AudioVAE 기반의 연속 표현과 ARDiT 구조를 결합한 새로운 AR TTS 프레임워크를 제안합니다. 첫째, AudioVAE를 통해 음성을 semantically structured한 공간으로 정규화하고, 둘째, LLM과 AR-FM 헤드를 분리하여 의미론적 계획과 음향적 렌더링의 경쟁을 방지함으로써 장기적 안정성을 확보했습니다 [Figure 1]. 셋째, Reward-free Self-corrective alignment를 통해 inference 오차를 스스로 수정하며, CFG-aware MeanFlow distillation을 통해 대규모 모델임에도 실시간 수준의 낮은 Latency를 달성했습니다 [Figure 2]. 주요 실험 결과, dots.tts는 Seed-TTS-Eval 벤치마크에서 기존 최고 성능 모델 대비 우수한 지표를 기록하였으며, 중국어(zh)와 영어(en) 환경에서 각각 0.94%와 1.30%의 WER(Word Error Rate) 및 81.0, 77.1의 SIM(Speaker Similarity) 점수를 기록하며 SOTA(State-of-the-art) 성능을 입증했습니다. 또한, MeanFlow 적용 시 Plain 모드에서 85ms, Interleaved 스트리밍 모드에서 54ms의 낮은 First-packet latency를 달성하여 실제 배포 환경에서의 효율성을 검증하였습니다.
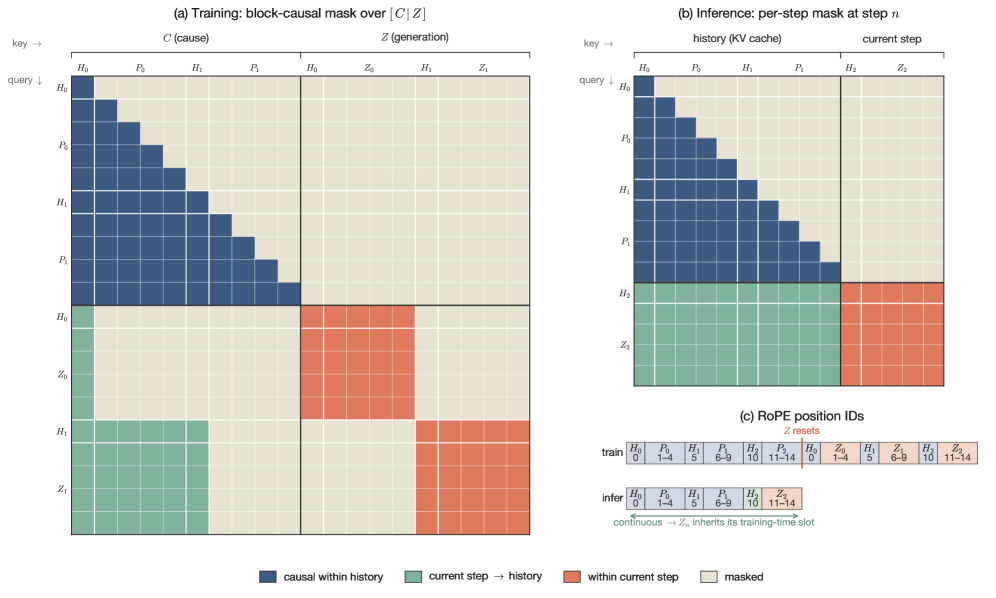
Figure 2 — AR-FM 헤드의 Attention 마스크
4. Conclusion & Impact (결론 및 시사점)
본 연구는 2B 파라미터 규모의 완전 연속형 AR TTS 시스템인 dots.tts를 통해 기존 discrete 토큰 시스템의 구조적 한계를 성공적으로 해결했습니다. 제안된 아키텍처와 post-training 기법은 고충실도 음성 생성, 안정적인 음성 복제(Voice cloning), 그리고 스트리밍 성능을 동시에 만족합니다. 특히, 학습 및 추론 코드와 체크포인트를 오픈소스로 공개함으로써, 향후 고표현력 실시간 인터랙티브 음성 AI 연구와 산업계 배포에 중요한 기술적 이정표가 될 것으로 기대됩니다.
⚠️ 알림: 이 리뷰는 AI로 작성되었습니다.
관련 포스트
- [논문리뷰] Voxtral TTS
- [논문리뷰] Lip Forcing: Few-Step Autoregressive Diffusion for Real-time Lip Synchronization
- [논문리뷰] Interpreting and Steering a Text-to-Speech Language Model with Sparse Autoencoders
- [논문리뷰] LongLive-RAG: A General Retrieval-Augmented Framework for Long Video Generation
- [논문리뷰] SwanVoice: Expressive Long-Form Zero-Shot Speech Synthesis for Both Monologue and Dialogue
Review 의 다른글
- 이전글 [논문리뷰] Your UnEmbedding Matrix is Secretly a Feature Lens for Text Embeddings
- 현재글 : [논문리뷰] dots.tts Technical Report
- 다음글 [논문리뷰] A Geometric Account of Activation Steering through Angle-Norm Decomposition
댓글