[논문리뷰] A Geometric Account of Activation Steering through Angle-Norm Decomposition
링크: 논문 PDF로 바로 열기
메타데이터
저자: Georgii Aparin, Tatiana Gaintseva
1. Key Terms & Definitions (핵심 용어 및 정의)
- Activation Steering: Language Model의 중간 레이어 hidden state를 수정하여 특정 행동이나 개념을 제어하는 inference-time 기법입니다.
- Angle-Norm Decomposition: Hidden state를 Angular component(개념 방향)와 Radial component(Norm, 크기)로 분리하여 해석하는 기법입니다.
- Spherical Steering: Norm을 보존하면서 hidden state를 concept direction 방향으로 회전시키는 제어 방식입니다.
- Pareto Frontier: Steering strength 변화에 따른 개념 제어 효과(Task metric)와 모델의 생성 안정성(Perplexity) 간의 최적 성능 곡선입니다.
2. Motivation & Problem Statement (연구 배경 및 문제 정의)
기존의 Additive Steering은 단순히 특정 방향의 벡터를 더하는 방식으로, 이는 개념 제어(Angular)와 hidden state의 크기 변화(Radial)를 동시에 발생시켜 제어의 기하학적 의미를 모호하게 만듭니다 [Figure 1]. 최근 제안된 Spherical Steering은 norm을 고정하여 안정성을 높이고자 하지만, norm 보존이 항상 최적의 안정성을 보장하는지에 대한 엄밀한 검증은 부족합니다. 본 논문은 이러한 방법론들이 개념 제어 효과와 안정성 측면에서 왜 다르게 작동하는지 기하학적으로 분석하고자 합니다. 특히, 개념 정보가 실제로 방향성에만 존재하는지, 그리고 norm의 변화가 Steering 성능에 미치는 정량적 영향을 파악하는 것이 핵심 목표입니다.
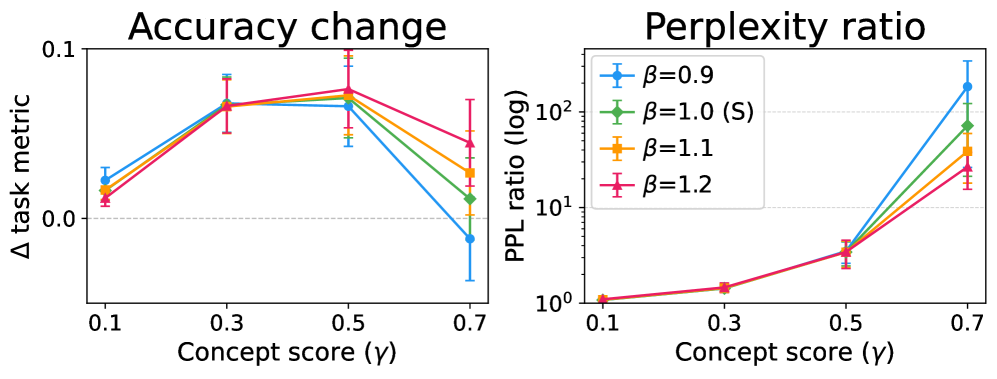
Figure 1 — Norm scaling이 생성 안정성에 미치는 영향
3. Method & Key Results (제안 방법론 및 핵심 결과)
본 연구는 hidden state를 concept 방향과의 정렬을 나타내는 Angular component와 Norm(radius)으로 분해하는 프레임워크를 제안합니다 [Equation 1, 2]. 저자들은 CAA(Concept Activation Addition), CAA-r(Renormalized), CAA-m(Matched), S(Spherical), AS(Additive Spherical), SN(Spherical with Norm scaling) 등 6가지 Steering 방식을 통해 이들의 기하학적 차이를 비교합니다 [Table 1]. 실험 결과, 7개의 LLM 모델에서 concept 정보는 주로 Angular structure에 인코딩되어 있음을 확인했습니다 [Figure 4]. 그러나 단순한 norm 보존이 능사가 아님을 입증했는데, 고강도 Steering 시 엄격한 norm 보존은 오히려 Perplexity를 급격히 상승시키고 MMLU 등 모델의 기본 성능을 저하시킵니다 [Figure 6]. 반면, 동일한 Angular target을 유지하면서도 적절한 수준의 norm 증가를 허용하는 SN 방식은 Perplexity를 최대 1.8배까지 개선하면서도 의미적 제어 효과는 안정적으로 유지함을 보였습니다 [Figure 1, Figure 2]. 이는 Steering을 단일 계수 조절이 아닌, Angular 제어와 Radial 안정성이라는 두 개의 독립적인 변수로 접근해야 함을 시사합니다.
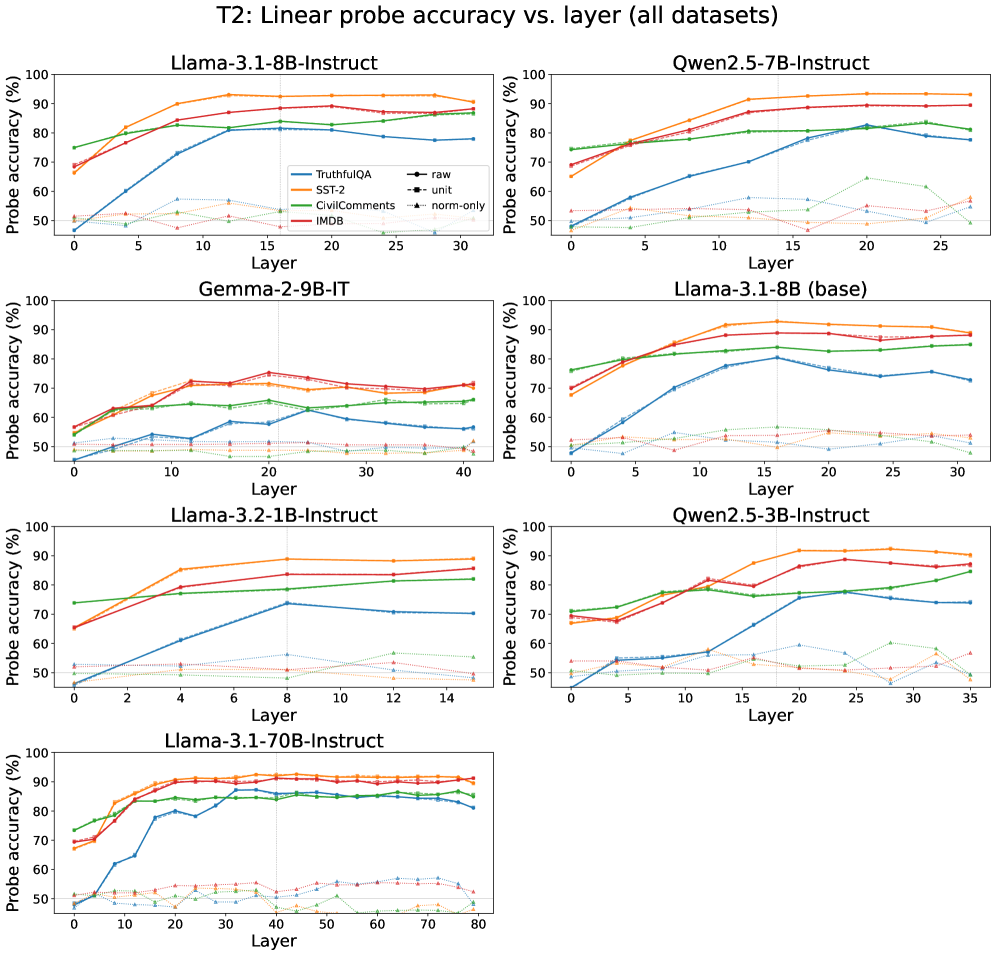
Figure 4 — 개념 정보의 Angular 인코딩 증명
4. Conclusion & Impact (결론 및 시사점)
본 논문은 Activation Steering을 Angular control과 Radial scaling의 두 파라미터로 재정의하는 기하학적 관점을 제시합니다. 개념 정보의 주된 원천이 방향성(Angular)에 있다는 가설을 검증함과 동시에, 보조적인 요소로 여겨졌던 norm이 생성 안정성 및 모델 능력 보존에 결정적인 역할을 함을 밝혔습니다. 이 연구는 향후 LLM 제어 기법을 설계할 때 단순히 방향성만 고려하는 것이 아니라, 제어 강도에 따라 유연하게 norm을 조절하여 성능과 안정성의 균형을 맞추는 최적화 가이드라인을 제공합니다.
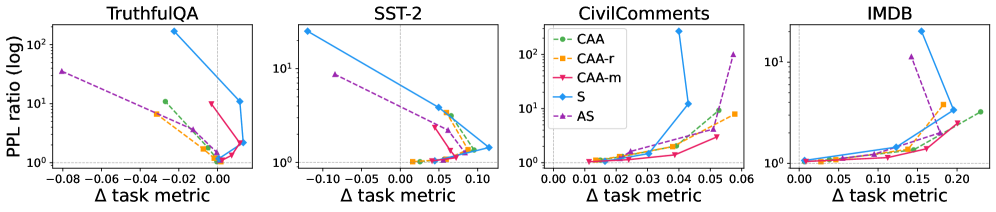
Figure 7 — 모델별 steering 기법의 Pareto 곡선 비교
⚠️ 알림: 이 리뷰는 AI로 작성되었습니다.
관련 포스트
- [논문리뷰] ASA: Training-Free Representation Engineering for Tool-Calling Agents
- [논문리뷰] Whisper Hallucination Detection and Mitigation via Hidden Representation Steering and Sparse AutoEncoders
- [논문리뷰] Monitoring the Internal Monologue: Probe Trajectories Reveal Reasoning Dynamics
- [논문리뷰] Model-Adaptive Tool Necessity Reveals the Knowing-Doing Gap in LLM Tool Use
- [논문리뷰] Steered LLM Activations are Non-Surjective
Review 의 다른글
- 이전글 [논문리뷰] dots.tts Technical Report
- 현재글 : [논문리뷰] A Geometric Account of Activation Steering through Angle-Norm Decomposition
- 다음글 [논문리뷰] AHA-WAM:Asynchronous Horizon-Adaptive World-Action Modeling with Observation-Guided Context Routing
댓글