[논문리뷰] Whisper Hallucination Detection and Mitigation via Hidden Representation Steering and Sparse AutoEncoders
링크: 논문 PDF로 바로 열기
저자: Georgii Aparin, Vadim Popov, Tasnima Sadekova, Assel Yermekova
1. Key Terms & Definitions (핵심 용어 및 정의)
- Whisper Hallucinations: 비음성(Non-speech) 오디오 입력에 대해 모델이 실제 입력과 무관한 유창하고 일관된 텍스트를 생성하는 현상.
- Sparse AutoEncoder (SAE): 고차원의 밀집된 활성값(Activation)을 해석 가능한 희소(Sparse)한 잠재 표현(Latent Representation)으로 분해하는 모델.
- Activation Steering: 모델의 가중치를 수정하지 않고, 추론 중에 특정 동작(예: 환각 억제)을 유도하기 위해 활성값 공간의 특정 방향으로 벡터를 더하거나 조작하는 기법.
- Detection Rate (DR): 모델의
no_speech_prob및avg_logprob필터를 기반으로 음성 포함 여부를 식별하는 성능 지표.
2. Motivation & Problem Statement (연구 배경 및 문제 정의)
본 논문은 Whisper와 같은 대규모 신경망 기반 ASR 모델이 비음성 오디오를 입력받았을 때 발생하는 환각 문제를 해결하는 것을 목적으로 한다. 기존의 heuristic 필터링 방식은 높은 신뢰도로 환각을 생성하는 사례를 효과적으로 걸러내지 못하는 한계를 지닌다. 따라서 저자들은 모델을 별도로 재학습(Fine-tuning)하지 않고도, 내부 표현을 정밀하게 제어하여 환각을 억제할 수 있는 효율적인 개입 메커니즘을 제안한다 [Figure 1].
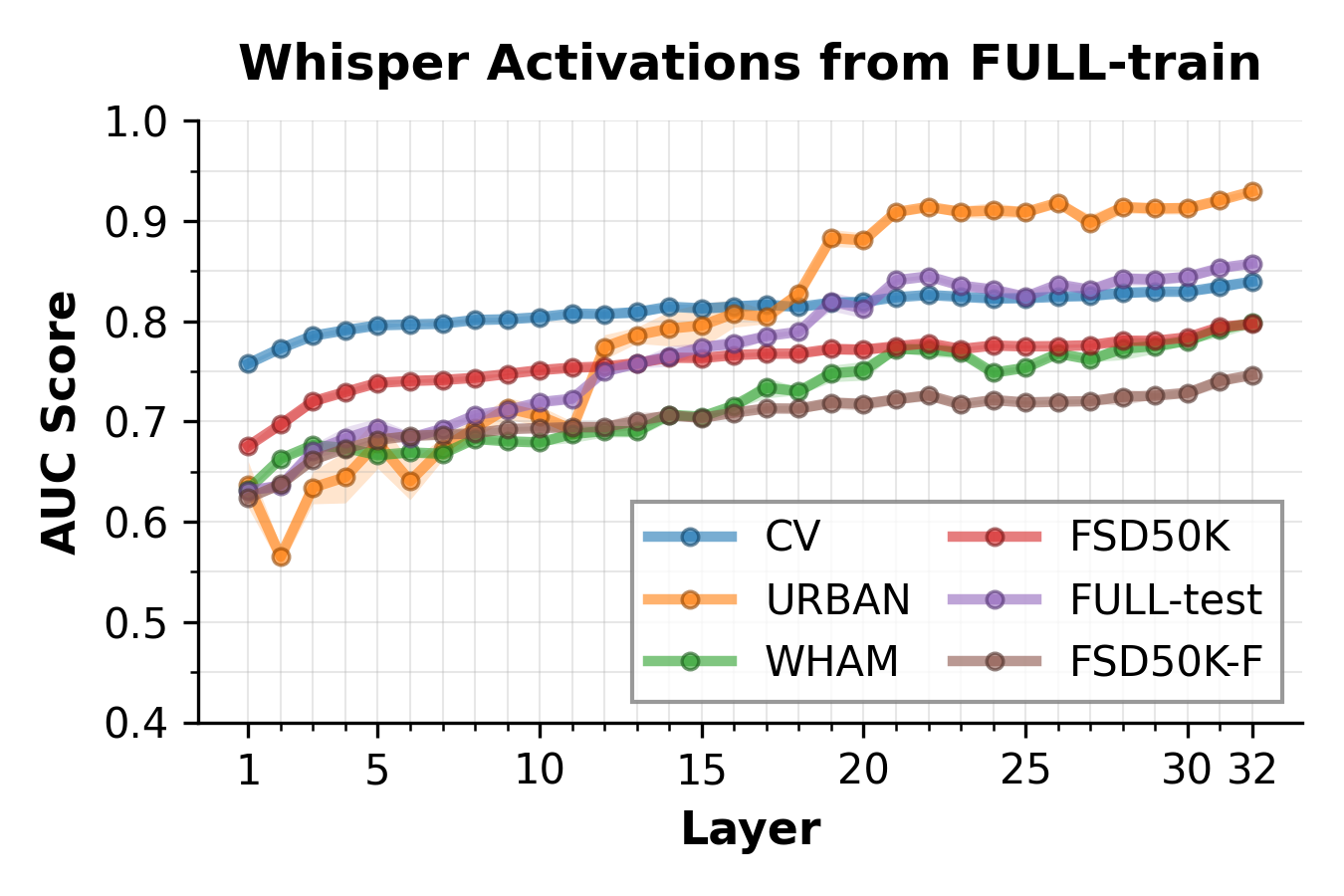
Figure 1 — 레이어별 환각 분류 성능
3. Method & Key Results (제안 방법론 및 핵심 결과)
본 논문은 Whisper의 오디오 인코더 활성값과 이를 SAE로 분해한 잠재 표현을 활용하여 환각을 감지하고 제어하는 두 가지 전략을 제시한다. 구체적으로, 환각 여부가 인코더의 심층 레이어에서 선형적으로 분리 가능하다는 점을 활용해 Activation Steering과 SAE Latent-space Steering을 수행한다 [Figure 1]. 실험 결과, SAE 기반의 Additive Steering 기법은 Whisper small 모델의 환각률(HR)을 72.63%에서 14.11%로, Whisper large-v3 모델의 경우 86.88%에서 27.33%로 획기적으로 낮추었다 [Figure 5]. 이러한 성과는 모델의 원래 파라미터를 전혀 수정하지 않고도 기존의 Fine-tuning 기반 방식들과 경쟁할 수 있는 성능을 보여주며, 정량적으로는 음성 데이터에 대한 WER 품질을 적절히 보존하면서 환각을 효율적으로 억제했다 [Figure 5].
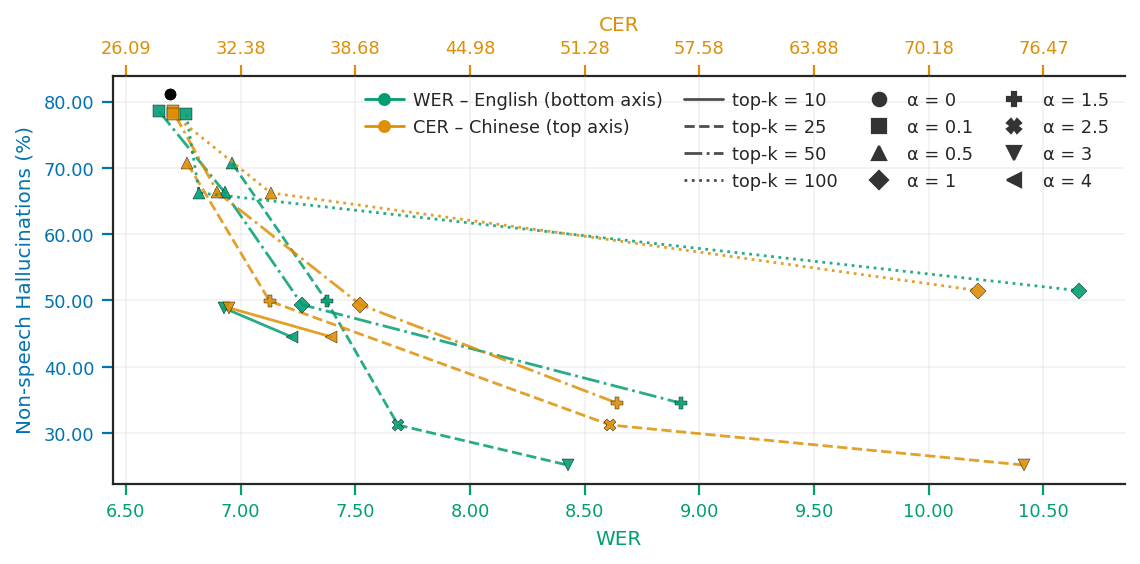
Figure 5 — 성능 및 환각 저감 트레이드오프
4. Conclusion & Impact (결론 및 시사점)
본 연구는 Whisper의 내부 활성값이 환각 정보를 담고 있음을 밝히고, SAE를 통한 희소 표현으로 이를 더 효과적으로 제어할 수 있음을 입증했다. 제안된 Steering 전략은 파라미터 업데이트 없이 환각을 저감하는 가볍고 정밀한 해결책을 제시한다. 이 연구는 ASR 모델의 신뢰성을 높이는 기술적 토대를 제공하며, 특히 Mechanistic Interpretability를 실제 오디오 처리 파이프라인의 오류 수정에 적용했다는 점에서 큰 의의가 있다.
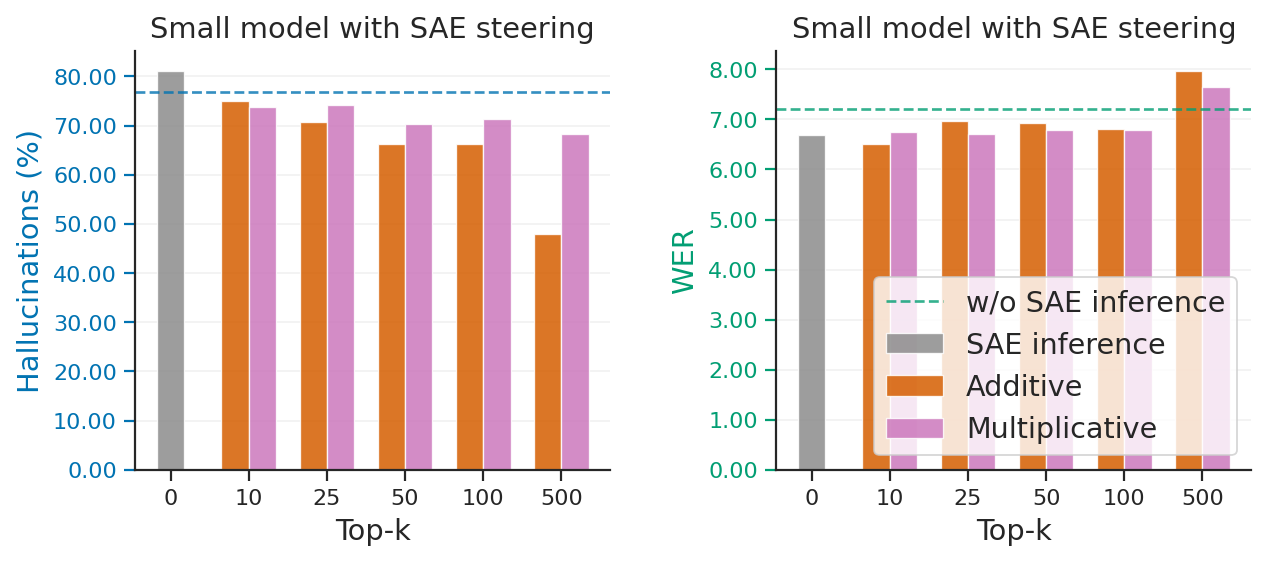
Figure 4 — SAE Steering 기법 비교
⚠️ 알림: 이 리뷰는 AI로 작성되었습니다.
관련 포스트
- [논문리뷰] A Geometric Account of Activation Steering through Angle-Norm Decomposition
- [논문리뷰] Steered LLM Activations are Non-Surjective
- [논문리뷰] Vividh-ASR: A Complexity-Tiered Benchmark and Optimization Dynamics for Robust Indic Speech Recognition
- [논문리뷰] Thinking in Uncertainty: Mitigating Hallucinations in MLRMs with Latent Entropy-Aware Decoding
- [논문리뷰] Prism-Δ: Differential Subspace Steering for Prompt Highlighting in Large Language Models
Review 의 다른글
- 이전글 [논문리뷰] Where Rectified Flows Leak: Characterising Membership Signals Along the Interpolation Path
- 현재글 : [논문리뷰] Whisper Hallucination Detection and Mitigation via Hidden Representation Steering and Sparse AutoEncoders
- 다음글 [논문리뷰] Why Muon Outperforms Adam: A Curvature Perspective
댓글