[논문리뷰] Why Muon Outperforms Adam: A Curvature Perspective
링크: 논문 PDF로 바로 열기
저자: Shuche Wang, Fengzhuo Zhang, Jiaxiang Li, Dirk Bergemann, Zhuoran Yang
1. Key Terms & Definitions (핵심 용어 및 정의)
- Muon: LLM pretraining에서 Adam 대비 우수한 효율을 보이는 matrix-parameter optimizer로, momentum matrix의 singular value를 정규화하여 업데이트 방향을 결정합니다.
- Normalized Directional Sharpness (NDS): 업데이트 방향에 대한 Hessian curvature를 update norm으로 정규화한 지표로, 최적화 과정에서 발생하는 curvature penalty의 핵심 원인입니다.
- Hessian: 최적화 landscape의 2차 곡률(curvature)을 나타내는 행렬로, 본 논문에서는 매개변수 업데이트의 효율을 결정하는 2차 손실 비용을 분석하는 데 사용됩니다.
- Kronecker Rank: Hessian 행렬을 Kronecker product들의 합으로 분해했을 때의 랭크로, LLM의 Hessian이 낮은 Kronecker rank를 가짐을 입증하는 데 활용됩니다.
2. Motivation & Problem Statement (연구 배경 및 문제 정의)
본 논문은 LLM pretraining에서 Muon이 왜 Adam보다 약 2배 빠른 학습 효율을 보이는지, 그 근본적인 기하학적 이유를 규명하고자 합니다. 기존 연구들은 주로 associative memory나 데이터 분포의 관점에서 이를 해석했으나, 최적화 landscape의 2차 곡률(curvature) 특성에 대한 분석은 부족했습니다. 저자들은 Adam과 Muon의 업데이트가 동일한 매개변수 지점에서 왜 다른 학습 성과를 내는지 이해하기 위해, 2차 Taylor 전개를 통해 one-step loss decrease를 분해하여 비교합니다. 이를 통해 Muon의 우위가 1차적인 gradient alignment가 아닌, 2차적인 curvature penalty에서 기인함을 밝힙니다.
3. Method & Key Results (제안 방법론 및 핵심 결과)
저자들은 2차 Taylor 근사를 통해 one-step loss decrease를 first-order gain과 second-order curvature penalty로 분해하는 프레임워크를 제안합니다 [Figure 1]. 실험 결과, Muon과 Adam은 유사한 first-order gain을 보이지만, Muon은 Adam보다 일관되게 낮은 curvature penalty를 기록함을 확인했습니다 [Figure 1]. 또한, curvature penalty를 update norm과 NDS로 분해한 결과, 두 옵티마이저의 update norm은 유사함에도 불구하고 Muon이 현저히 낮은 NDS를 보였습니다 [Figure 2]. 데이터 불균형(imbalance)이 커질수록 NDS 격차가 확대됨을 보였으며, 이는 Muon이 불균형한 데이터 환경에서 더 강력한 우위를 점하게 함을 시사합니다 [Figure 3]. 마지막으로 NDS가 학습 후반부로 갈수록 within-layer Hessian block에 집중된다는 사실을 밝혀냈으며, 이는 정량적으로 Muon의 within-layer fraction이 학습 과정에서 약 14%에서 44%로 크게 증가하는 것으로 증명됩니다 [Figure 4].
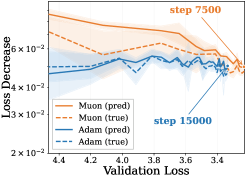
Figure 1 — Muon과 Adam의 1단계 최적화 분해
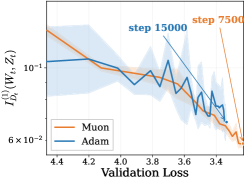
Figure 2 — NDS 및 업데이트 크기 비교
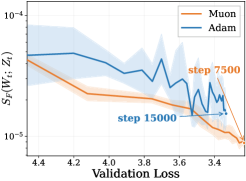
Figure 4 — NDS의 계층 내/간 기여도 분석
4. Conclusion & Impact (결론 및 시사점)
본 논문은 Muon이 Adam 대비 우월한 성능을 내는 이유가 더 낮은 NDS를 통해 2차 curvature penalty를 줄이기 때문이라는 기하학적 메커니즘을 최초로 제시합니다. 특히 데이터 불균형이 이 curvature advantage를 증폭시킨다는 점은 LLM 학습 데이터의 구조와 옵티마이저 선택 간의 상관관계를 명확히 설명합니다. 이 연구는 최적화 landscape 관점에서 구조화된 행렬 업데이트(structured matrix updates)의 기하학적 이점을 입증함으로써, 차세대 효율적 옵티마이저 설계에 중요한 이론적 토대를 제공합니다.
⚠️ 알림: 이 리뷰는 AI로 작성되었습니다.
관련 포스트
- [논문리뷰] Learnable Multipliers: Freeing the Scale of Language Model Matrix Layers
- [논문리뷰] Your UnEmbedding Matrix is Secretly a Feature Lens for Text Embeddings
- [논문리뷰] Rethinking Muon Beyond Pretraining: Spectral Failures and High-Pass Remedies for VLA and RLVR
- [논문리뷰] TransitLM: A Large-Scale Dataset and Benchmark for Map-Free Transit Route Generation
- [논문리뷰] From Runnable to Shippable: Multi-Agent Test-Driven Development for Generating Full-Stack Web Applications from Requirements
Review 의 다른글
- 이전글 [논문리뷰] Whisper Hallucination Detection and Mitigation via Hidden Representation Steering and Sparse AutoEncoders
- 현재글 : [논문리뷰] Why Muon Outperforms Adam: A Curvature Perspective
- 다음글 [논문리뷰] WorldCraft: From Camera Navigation to Object Manipulation in Interactive Video World Models
댓글